Klein 4B / 9B / Base LoRAs aren't cross-compatible — a 9B NSFW LoRA throws 'lora key not loaded' on mflux's 4B path. The variant map, what mflux runs today, and where the working hands-on test lives.
Practical findings from someone who published 18 Chrome extensions over 6 months: what moved installs (titles, short descriptions, screenshots, review prompts) and how the Manifest V2 to V3 migration affects install rates.
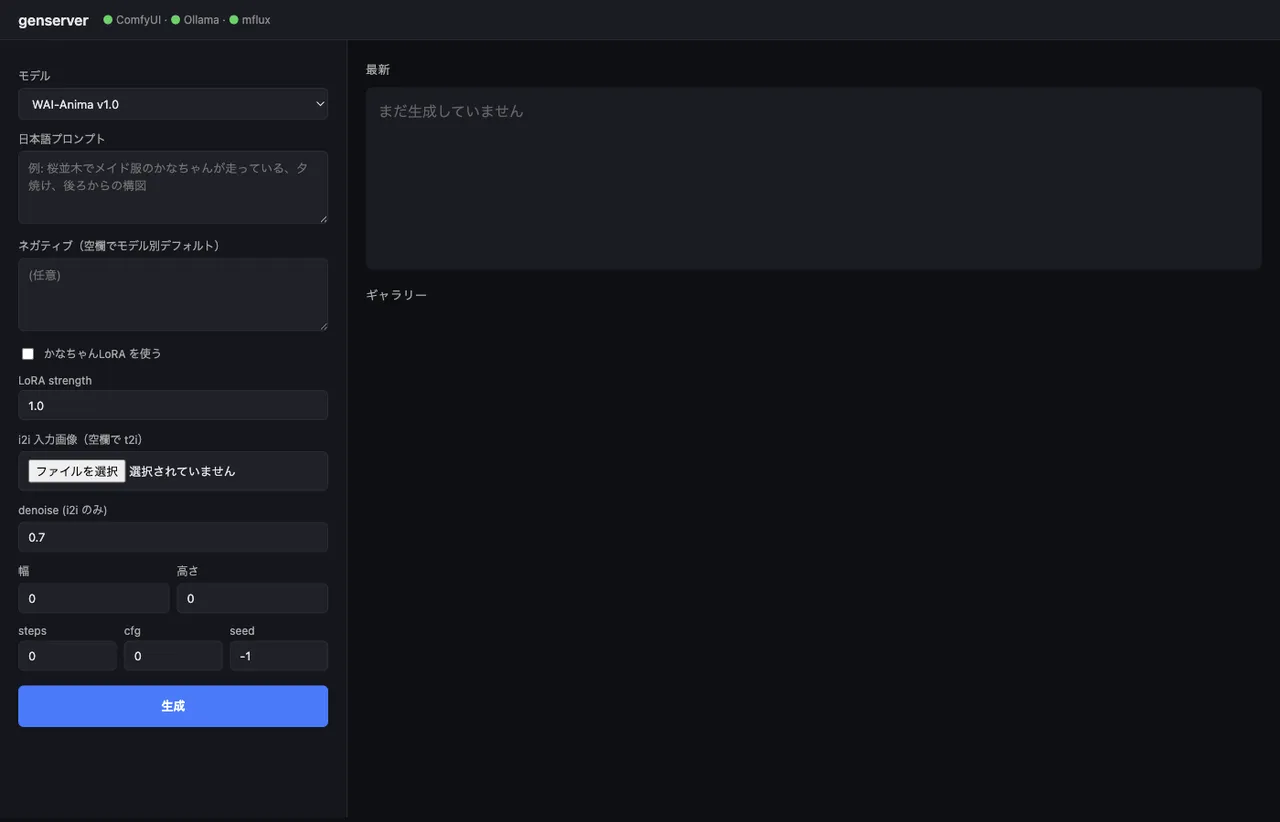
Three local image generation engines (WAI-Anima, WAI-IL/SDXL, FLUX.2 Klein 4B) tied together by a thin FastAPI wrapper that takes Japanese prompts. Ollama (gemma3:12b) handles JP→EN, ComfyUI workflows are built on the fly in Python, FLUX.2 runs as an mflux subprocess, and the whole thing is reachable from an iPhone over Tailscale.
Hands-on log of building the DEV article's PDF RAG on M1 Max 64GB, extending it with images via CLIP, and pushing through Japanese with bge-m3 + Qwen3.6 35B. Documents the modality gap, the dual inference server crash, and LLM-jp 4-8B's empty chat template silently dropping the system role.
A hands-on log of running Qwen-Scope's Sparse Autoencoder locally on M1 Max 64GB with Qwen3-8B-Base, extracting feature IDs that discriminate between Japanese, English, code, and Chinese from a single middle layer.
A hybrid approach that lets Apache POI build the OOXML scaffold while sheetData is streamed by hand. Verified XML escape, control char, date cell, and merge behavior of scndry's implementation on M1 Max.
Hands-on benchmark of FLUX.2 Klein 4B on M1 Max 64GB using mflux (MLX) and iris.c (pure C + Metal). A counter to Pruna AI's H100-only tutorial — measuring how fast Apple Silicon actually gets there.
Confirmed SeeSee21/Z-Anime is a full fine-tune of Z-Image Base, then ran the AIO version on local ComfyUI on an M1 Max 64GB to verify t2i, i2i, and how NSFW prompts pass through.
A verification log for converting color anime-style AI illustrations to manga-style monochrome. AI re-generation approaches lean to either color leakage or face drift, and pure deterministic local processing looks mechanical. Frames the next directions to try: putting a grayscale-only LoRA on Anima, and using See-through for part decomposition before mechanical composition.
With v3 captions kept as-is and only the training amount pushed up to Anima's official 12,000+ step recommendation, the direction hit rate went 100% at ep150-180, crashed to 0% at ep200, then partially recovered to 67% at ep227 — a non-monotonic curve. 600-720 exposures per training image is the sweet spot; over 800 triggers catastrophic forgetting. Learning rate 2e-5, ~11 hours / $10 of RunPod training plus a sweet-spot epoch scan.
Records of rewriting captions for the 53 training images for the WAI-Anima character LoRA retrain after side ponytail direction control failed last time. Wrote position information into natural language so Qwen3 TE could pick it up, and dropped the IL-era strategy of absorbing the entire hairstyle into the single 'kanachan' trigger by promoting hairstyle to independent Danbooru tags. Includes notes on year tag necessity, the bikini/nude swapped-caption discovery, and blazer color recognition drift.
The NotebookLM clone open-notebook assumes Docker and cloud APIs by default. I installed SurrealDB natively, ran four processes in tmux, and wired everything through Ollama's qwen3.6:35b and bge-m3. I fed it the Qwen3.6 benchmark article I wrote this morning, and it answered with the correct numbers.