Controlled a Beambox Niji Badge over BLE from Windows without the official app. Sending a raw JPEG just produced a black screen — the fix was a custom binary container and a different command type than expected.
Wired M5Stack's CO2L Unit (SCD41) to a CoreS3 over Grove and put CO2/temp/humidity on screen. The factory-fresh sensor read +30% high against a SwitchBot NDIR meter, so I ran FRC over a serial command to pull it in line.
A brand-new CoreS3 failed with 'SD Card initialization failed!' on the stock firmware. Tested two LAZOS cards: the 16GB never mounts at any SPI clock, the 32GB mounts but only writes at 10MHz, and a soft reset wedges the card until power-off.
Three LLMs converted the same 10 Japanese scene briefs into Anima (Qwen-DiT) prompts, generated as 60 fixed-seed images on an M1 Max with a merged 3-character LoRA. The Qwen-to-Qwen affinity hypothesis did not survive; a strict formatter brief with character-count locks is what actually moved the results, and two failure modes survive any prompt.
Tested on an M1 Max, NumPy only: Qwen maps a prompt to a JSON of knobs, and a 2D Kuramoto oscillator field renders it. No objects, but composition, color, and motion change with the prompt.
Tested Astro 6→7 on a 1,558-post blog: keeping remark/rehype past Sätteri with @astrojs/markdown-remark, the @astrojs/vercel v11 bump, and a middleware TS1543/esbuild import-attribute trap.
Un-0 swaps neural-net weighted sums for Kuramoto coupled-oscillator physics, hitting FID 6.74 on ImageNet-64. Still GPU-simulated, and the 1000x energy claim is unproven — no chip yet.
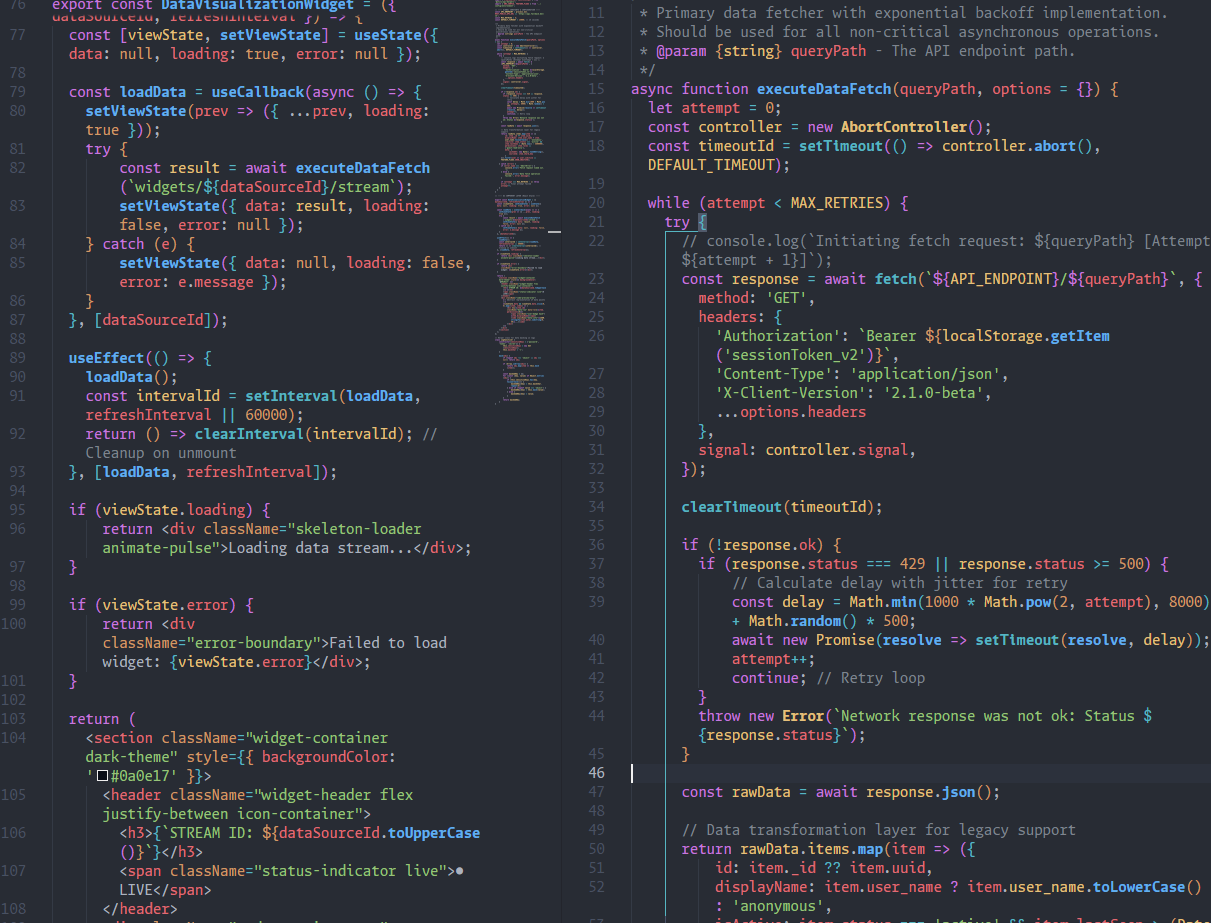
Fujitsu's PHOTON claims up to 475x over Transformers, but that's tokens/s/GiB (multi-query memory throughput), not faster single responses. What the 1.2B paper tables, the quality drop, and 9-query integration really show.
DeepSeek-V4-Pro-DSpark isn't a new base model. It's the same 1.6T V4-Pro checkpoint plus a DSpark speculative-decoding head (~893GB). What config.json and the DeepSpec repo reveal, and why there's no speed benchmark yet.
Merged kei, kana, and koharu into a single Anima (Qwen-DiT) LoRA and ran my first training on Blackwell (RTX 5090, sm_120). Hands-on log: the cu128 / torch2.8 / SDPA stack swap from the 4090, why the weakest character gets absorbed (caption asymmetry, not rank), and how trigger-only prompts separate three close-packed characters at ep143 without ControlNet.
Tested local Wan video gen on a Radeon 8060S (Strix Halo, 48GB UMA, Windows). ZLUDA can't run stock PyTorch; AMD's TheRock gfx1151 wheel gives native ROCm. FastWan 1.3B in 4min, Wan 14B I2V in 13.6min — VAE decode and 16GB-RAM Segfaults are the real limits.
Tested FramePack F1 on an RTX 4060 Laptop (8GB VRAM, 32GB RAM): VRAM peaked at 5.75GB, but the 26GB model overflowed RAM into the pagefile and a 5s clip took 56 min. The real bottleneck for local video gen on a laptop is RAM, not VRAM.