技術 2026年5月14日(木) 更新 約10分 Microsoft 2026年5月Patch Tuesdayの本命はDNS ClientとNetlogonの認証不要RCE、ZeroLogon・SIGRedとの位置づけで読む 5月Patch Tuesdayは137件中Critical 30件、公開悪用ゼロ。確認の中心は認証不要でCVSS 9.8のCVE-2026-41089 Netlogon RCEとCVE-2026-41096 DNS Client RCE。ZeroLogon・SIGRedとの違いとExploitability Index控えめの読み方、優先順位、検出ポイントを整理する。 Microsoft Windows セキュリティ 脆弱性 CVE RCE Active Directory DNS
技術 2026年5月14日(木) 約6分 3GBのSQLite FTSを10MBのRust FSTに置き換えたフィンランド語辞書で圧縮率300倍が出た条件 Andrew Quinnのフィンランド語辞書tskで、3GBのSQLite FTSが10MBのRust FSTになった話を読む。前方一致、語形変化、静的データ、接尾辞の共有が揃うと何が起きるか。 データ構造 検索 全文検索 Rust
技術 2026年5月14日(木) 更新 約6分 nginxの18年越しrewrite脆弱性CVE-2026-42945は設定パターン次第で未認証RCEに届く nginx 0.6.27〜1.30.0のrewriteモジュールに18年間残っていたバッファオーバーフロー。CVSS 9.2だが全環境ではなく特定のrewrite設定パターンだけが対象で、nginx -Tによる確認方法も書いた セキュリティ CVE nginx 脆弱性 RCE
技術 2026年5月14日(木) 約6分 Linuxゲームが速くなるのはNTSYNCがWindowsの待ち合わせをカーネルで処理するから Linux 6.14のNTSYNC、Wine 11.0、Proton 11 betaで何が変わったか。平均FPSよりフレーム時間、/dev/ntsyncの確認、Proton側の採用状況まで。 Linux カーネル Steam ゲーム
技術 2026年5月14日(木) 約12分 GTIGが初観測したAI生成ゼロデイ、OSSウェブ管理ツールの2FAをLLMが見つけたセマンティック欠陥でバイパス 2026年5月11日にGoogle GTIGが公表した、攻撃者がLLMで生成したゼロデイの初確認事例。OSSウェブ系管理ツールの2FAバイパスを「ハードコードされた信頼仮定」のセマンティック欠陥として発見、Pythonエクスプロイトに残ったハルシネートCVSSスコアと教科書的構造が手がかりだった。APT45・UNC2814の周辺動向まで整理 セキュリティ AI LLM ゼロデイ Google
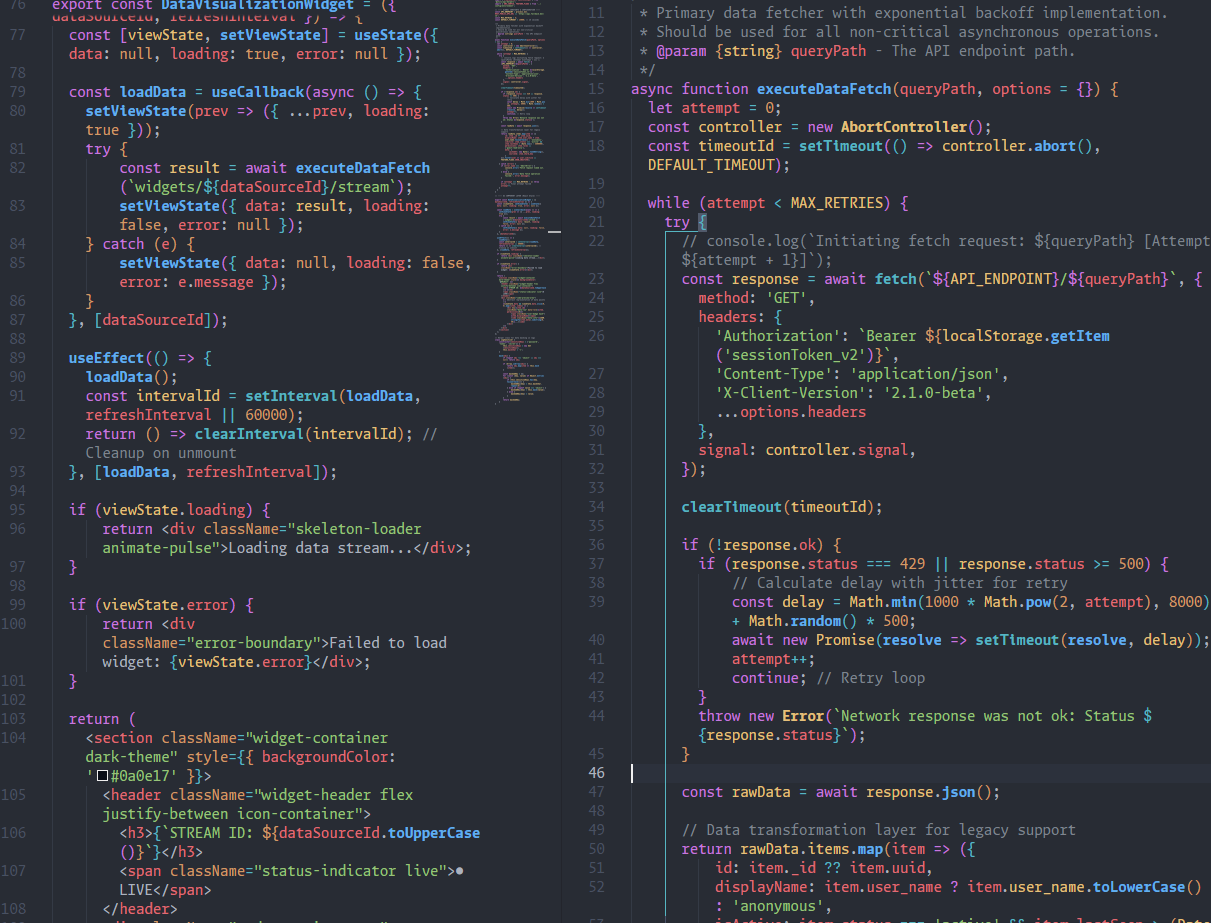
技術 2026年5月14日(木) 約29分 oMLX 0.3.9.dev2をM1 Max 64GBで実測、SSD KVキャッシュ・Gemma 4 VLM MTP・DFlash・omlx launch copilot M1 Max 64GBにoMLX 0.3.9.dev2を入れて、SSD KVキャッシュ2回目prefill短縮、Gemma 4 VLM MTPオン/オフ、DFlash vs 通常エンジン、omlx launch copilotの実動作を順に測る。VLM入力はWAI-Animaで生成したかなちゃん画像で揃えた。 AI LLM ローカルLLM Apple Silicon MLX 推論最適化 Codex 実験
技術 2026年5月13日(水) 約7分 Quake IIIの高速逆平方根(0x5f3759df)をApple M4とZen 3で実機ベンチ、std::sqrtより速くなる条件がプラットフォームで違った Apple M4 (Mac mini) と Zen 3 (Ryzen 5800HS / WSL2) でFISRを実機ベンチ。M4は-O2で1/sqrtfがrsqrte化されQ_rsqrtに肉薄、Zen 3は-ffast-math必須で-O2のままだと12倍差。自前NEON/SSEは逆に遅い、ニュートン回数別の誤差、Lomont定数比較も込み。 C アルゴリズム ベンチマーク Apple Silicon 数学 ゲーム開発 実験
技術 2026年5月13日(水) 更新 約7分 oMLX 0.3.9.dev2はMacローカルLLMをCodexやCopilotに寄せてきた oMLX 0.3.9.dev2のリリースノートを読む。Gemma 4 VLMのMTP、DFlash対応、SSD KVキャッシュ、`omlx launch copilot`まわりが、Codex/Copilotなど常駐エージェントをMacローカルLLMに繋ぐ時にどこへ効くかを整理した。 AI LLM ローカルLLM Apple Silicon MLX 推論最適化 Codex
技術 2026年5月13日(水) 約5分 RubyGemsが500件超の悪性パッケージ対応で新規登録を一時停止 RubyGems.orgは悪性スパム投稿への対応として新規アカウント登録を停止した。500件超の悪性パッケージはyank済みで、既存ユーザーのgem installとpushは影響なし。新規gem採用や公開アカウント作成時の確認対象を絞る。 セキュリティ サプライチェーン マルウェア
技術 2026年5月13日(水) 約9分 VoxCPM2含めOSS TTSが7方向に割れてきた VoxCPM2のtokenizer-free方式を起点に、F5-TTSやCosyVoice2など7モデルの方向の違い、Irodori-TTSやStyle-Bert-VITS2など日本語特化TTSの位置づけ、台本+OpenJTalkで音素を作る学習データの仕組み、ボイスクローン悪用リスクまでを整理した。 AI TTS 音声合成 ボイスクローン ローカルAI オープンソース ファインチューニング
技術 2026年5月12日(火) 更新 約7分 NIST NVDの優先度付きenrichmentでSCAツールごとに見落とし方が変わる 2026年4月15日のNIST NVD運用変更で、KEV・米連邦利用ソフト・EO 14028 critical software以外のCVEはDeferredで止まる。Snyk・Trivy・Dependabot・OSV-Scanner・Grypeが何を見ているか、NVD APIでvulnStatusを確認するコマンド、実際にDeferredになったCVE例までまとめた。 セキュリティ 脆弱性 CVE CISA
技術 2026年5月12日(火) 更新 約13分 CodePush終了後のReact Native OTA更新をEAS Update・Stallion・自己ホストで比べる CodePush終了後にEAS Update、自己ホスト、Stallionを比較。ロールバック・署名の要件、ゲームアプリのAssetBundle配信との対比に加え、TestFlight配布、PWAのService Workerキャッシュ制御、Cloudflare Workersの停止問題まで、デプロイ済みコードのライフサイクルを扱う。 JavaScript React iOS Android モバイル開発