技術 更新 約17分
Anima-Base v1.0をM1 Maxで動かしてWAI-Animaと比較、既存LoRA互換性とTurbo LoRA 5.7倍高速化を検証
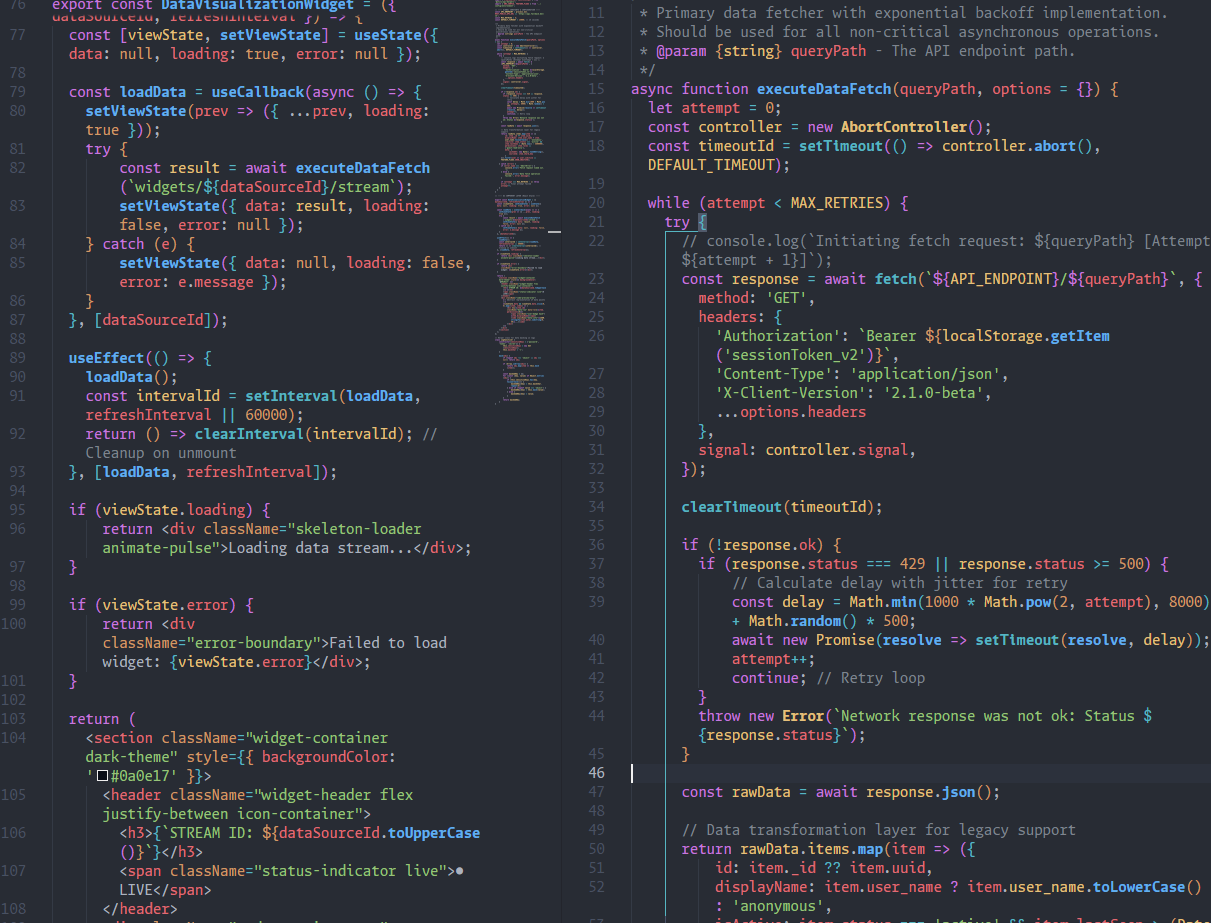
CircleStone Labs公式の真のbase model Anima-Base v1.0 をM1 Max 64GB / ComfyUIで preview3-base / WAI-Anima と並べた。生成時間は275〜285秒でほぼ同じだがWAI-Anima向け既存 kanachan LoRA は v1.0 で崩壊しやすく、軽い指定では22%しか拾わない。衣装パーツを明示する重い指定+Turbo LoRA+kana 1.0 では67%まで回復。v1.0 ベースで運用するなら LoRA 再学習が必要、というのが結論。