CreateFileW dwShareMode=0 locks 500K SMB files in 8 min with no encryption. Detection key: NAS session exclusive handle counts, not write-based indicators.
Tested on M1 Max: Floyd-Steinberg halftone + BLE pacing + a vendor-specific density command `1D 49 F0 nn` to print sharp photos on the Sugar YMP-01 thermal mini printer from Python.
Tested on M1 Max: switching a Python BLE client to RFCOMM (SPP Ch.2) cuts transfer from ~60s to 5.38s for a 140KB JPEG. Covers PyObjC quirks, macOS Bluetooth entitlement, and an isolation experiment confirming olie.xdev's 'possibly not required' steps.
Tested BMBrick's LEGO mosaic pipeline in Node + sharp with a 45-color palette: RGB nearest sprinkles 16% glitter and silver on photos, OKLab + material penalty wipes them out, and the original 0.15 is 7× overkill (0.02 is already enough).
Gemini API File Search now indexes images alongside text in the same store. Metadata filters can isolate NPC memories by chapter and character, and a single-character prototype costs under $1/month on Flash-Lite. Notes on tier limits, pricing breakdown, and what to test first.
A DEV Community article proposes cross-modal distillation for wildfire evacuation routing that encodes road closures and AQI thresholds directly into the loss function. I look at the teacher-student gap when the student drops satellite imagery, why 23ms edge inference is irrelevant if sensor data is 5 minutes old, and what's missing for production.
Cold install benchmarks from a Next.js 16 + Shadcn/ui + Railway monorepo show pnpm at half npm's time, but the real story is Radix UI's undeclared dependencies breaking under strict hoisting. A practical look at .npmrc tuning, Bun's flat structure trade-off, and where Next.js dependency weight dominates.
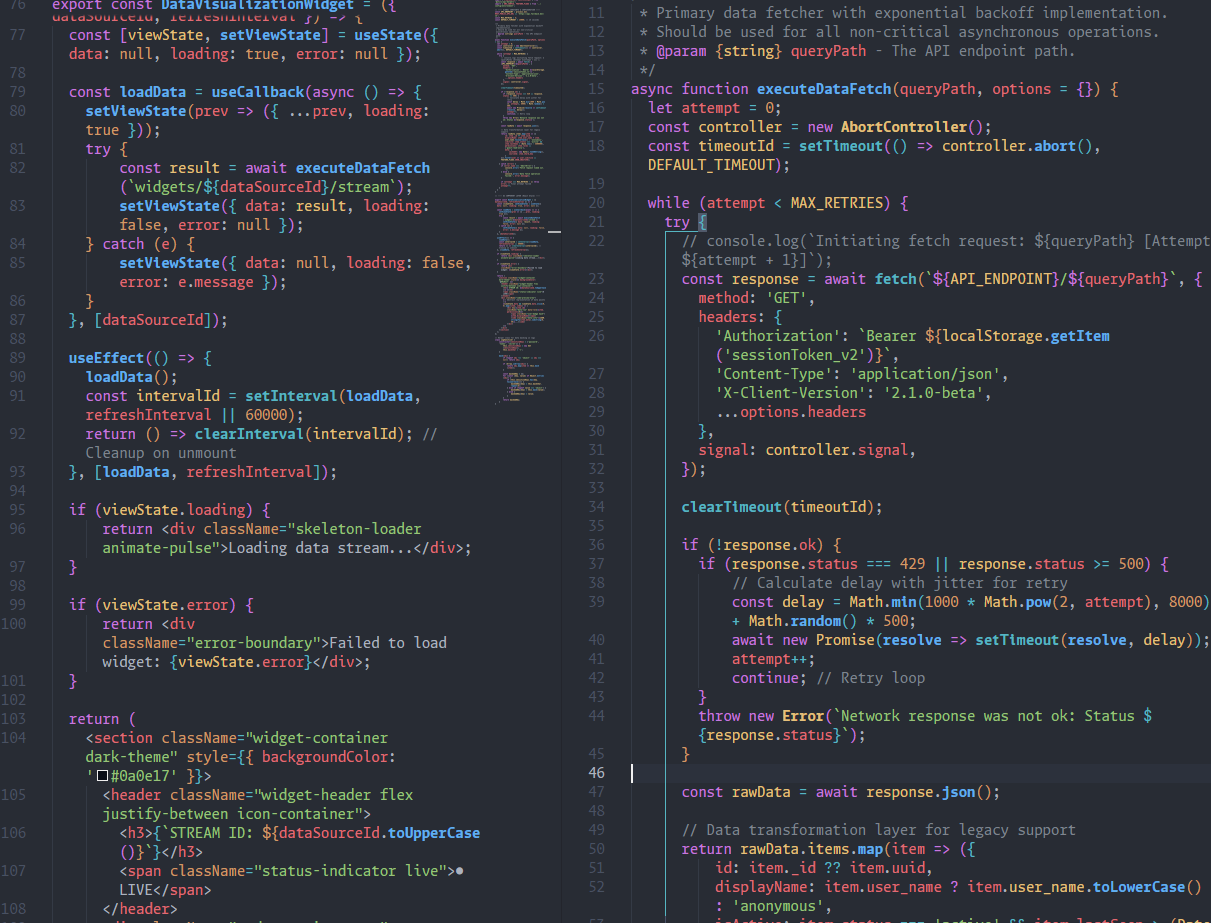
Out-of-bounds read in Ollama's GGUF loader before 0.17.1. If your Ollama API is network-accessible, a crafted model file can exfiltrate env vars, API keys, system prompts, and conversation fragments from process memory.
Tested Orbis in Docker: psf/requests (35 modules) makes a clean 3D graph, expressjs/express (98 modules) collapses into one giant sphere. Notes on what tree-sitter actually captures for code-review prep.
Google extended Binary Transparency to its Android apps and Mainline modules starting May 2026. How the public log and verification tools differ from code signing, what's actually covered, and what the ADB-based verification workflow looks like for researchers.