PA-Series and VM-Series with User-ID Authentication Portal exposed to untrusted traffic. CL-STA-1132 achieved root RCE, wiped crash logs, enumerated AD, and deployed EarthWorm and ReverseSocks5. Patches start May 13; interim mitigations and forensic indicators for exposed portals.
Went through Thariq's 20 HTML examples for practical Claude Code use. Throwaway editing UIs for ticket triage and annotated code diffs stood out. The deciding factor is whether the output's reader is human or AI.
Dirty Frag is a local privilege escalation that writes to the Linux page cache via ESP-in-UDP and RxRPC receive paths. The algif_aead workaround from Copy Fail doesn't help, and the two attack paths complement each other to bypass Ubuntu's AppArmor restrictions on user namespaces.
Android's May 2026 bulletin patches CVE-2026-0073, a Wireless ADB auth bypass from mishandled EVP_PKEY_cmp return values. Adjacent network attackers bypass mutual TLS and get shell-level RCE on Android 14 through 16-qpr2. AOSP diff and impact breakdown included.
Checked Fortress Token Optimizer's DEV article and npm/PyPI packages. Polite filler words shrink 11-22%, but running it blindly on system prompts or RAG context can strip constraints that control model output.
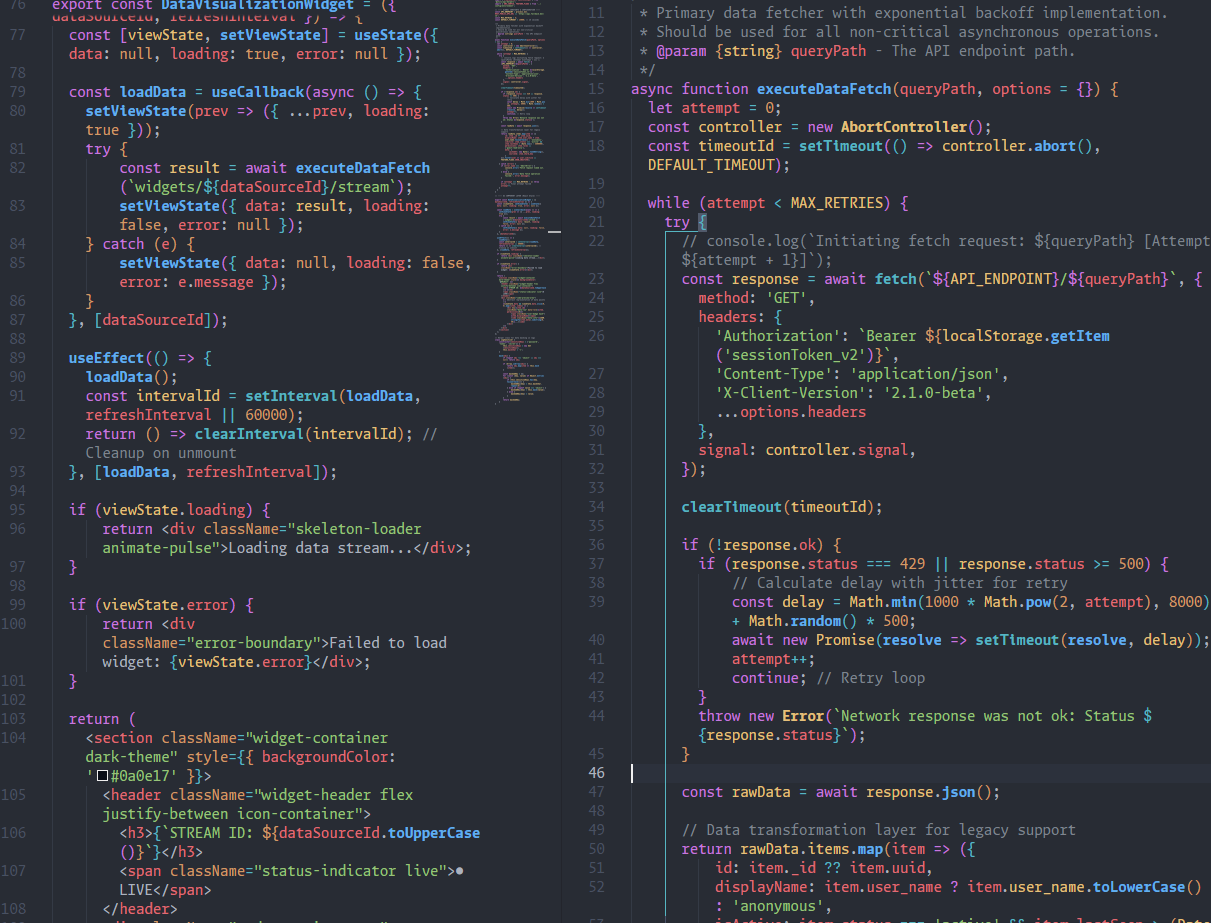
158K lines of AI-generated C# for a Cities: Skylines II total conversion mod. CivicRAG for codebase indexing, 300+ custom Roslyn analyzers as compile-time design rules, and manual visual debugging for render bugs AI couldn't see.
Tested Klein 9B + 9B NSFW LoRA on M1 Max 64GB via mflux 0.17.5: 1m51s/512, 5m37s/1024 q4, 224/224 LoRA keys match, NSFW prompts uncensored, Japanese subjects work with helper tokens.
Next.js 16.2.6 / 15.5.18 dropped 13 security advisories at once. The impact depends on whether you use App Router, Middleware, RSC, or self-hosted Node.js server — here's where to look before upgrading.
Vektor Memory v1.5.4 supersession chains positioned against YourMemory decay, Cloudflare key-overwrite, and CTX, with a BM25 vs cosine threshold trap and a 5-field minimum schema for agent memory.
uv 0.9.21 as the entry for small Claude SDK Python experiments: uv init, uv add, uv run, uv.lock keep agent projects reproducible across machines and Codex/Claude Code sessions. Operational notes, not a benchmark of the DEV article's uv 0.11.11.
The paper argues that RAG, vector stores, and scratchpads are retrieval, not learning. Read alongside CTX and OCR-Memory, the gap between 'better search' and 'weight-level learning' becomes concrete.
Tested Gemma 4 MTP drafter on M1 Max 64GB with mlx-vlm 0.5.0. Only the 26B A4B MoE got +13%; 31B Dense and E4B got slower. Code gen vs short haiku prompts flip the result.