Microsoft's 2011 Secure Boot CAs expire June and October 2026. Secure Score check MC1293483 tracks fleet readiness; KB5025885 applies a two-phase rollover via the AvailableUpdates registry (0x140 → 0x280). BlackLotus-driven 2023 CA migration finally collides with the natural 15-year cert expiry.
Claude's new Microsoft Purview connector surfaces ~30 audit event types and on-demand chat/file access — but not prompts, model names, or tool calls. Claude Code goes through OpenTelemetry separately. Enterprise plan only; Team and consumer plans excluded.
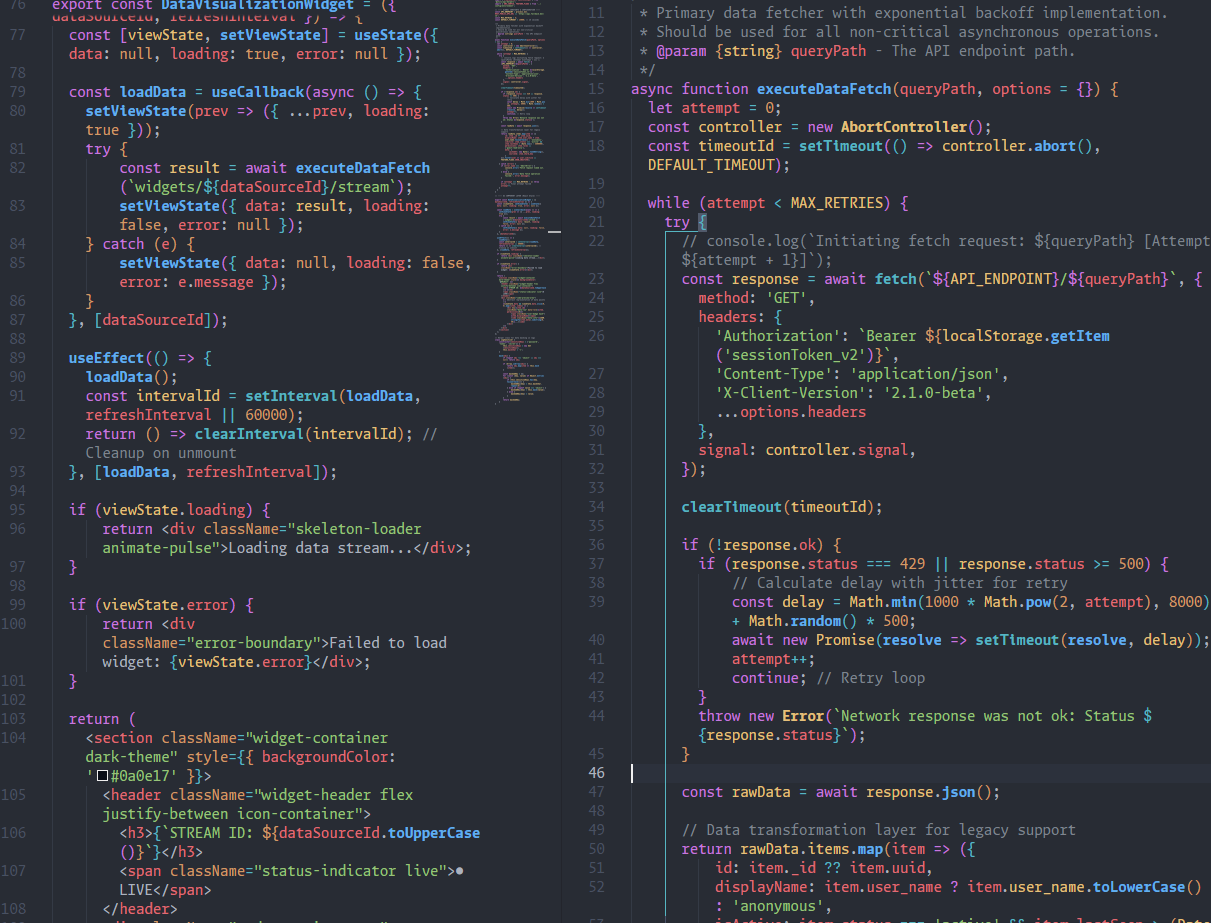
After Rift, two more nginx CVEs landed in late May 2026: njs js_fetch_proxy heap overflow CVE-2026-8711 and a second rewrite-module heap overflow CVE-2026-9256. Both pre-auth, CVSS v4.0 9.2, config-specific. Concrete grep checks and patch paths.
Hands-on with Tencent Hy-MT2 1.8B Q4_K_M (1.08GB) on M1 Max 64GB via llama-server. JSON, SRT, HTML, glossary, and minority-language prompts with full input-output pairs. The 1.25bit 440MB build does not load on stock llama.cpp 8990, and 30B-A3B (hy_v3) is not in the Mac route yet.
Tested on ComfyUI with Anima Turbo LoRA: hair intakes don't fire from the single tag. The 27-condition recipe — character NL reference + negative identity strip + (hair intakes:1.5) + 22.5° upper-front camera — also revealed the generic prompt was accidentally a Blue Archive character spec, and that Kanon's whole female cast has intakes as a cluster prior.
On M1 Max with Anima-Base v1.0 and WAI-Anima v1: the official negative is short. Trim the long Illustrious bad-hands list, move structure to positive tags, keep `safe` upfront.
Ran WAI-Anima v1.0 with a custom character LoRA on an M1 Mac to see if 2- and 3-character compositions actually hold up. Notes on what breaks and what holds at different LoRA weights, with practical settings that stay stable.
Walking through Dirty Pipe (CVE-2022-0847) from a 2026 angle: one uninitialized pipe_buffer.flags bit kept PIPE_BUF_FLAG_CAN_MERGE alive into splice'd pages, plus patched-kernel checks for distros and containers.
Tested on M1 Max 64GB ComfyUI: SetLatentNoiseMask silently fails on Anima + Anima-Turbo. LanPaint runs Example_26 in 32 min/image; Inpaint-CropAndStitch drops that to 2:31 for text inpaint and ~7 min for clothing replacement.
Microsoft assigned CVE-2026-45585 to YellowKey: strip autofstx.exe from WinRE BootExecute and move TPM-only BitLocker to TPM+PIN. No patch ETA; Chaotic Eclipse claims a TPM+PIN bypass PoC.
DirtyDecrypt PoC proves local root via Linux RxGK page cache writes on Fedora, Arch, and Tumbleweed with CONFIG_RXGK=y. NVD describes CVE-2026-31635 only as a DoS; Ubuntu LTS and Debian stable stock kernels are not affected. Check commands and container mitigation included.
The May 19 Mini Shai-Hulud wave compromised 314 npm packages under @antv via the `atool` maintainer account. After rolling back lockfiles, payload entry points stay behind in .claude/settings.json SessionStart hooks, .vscode/tasks.json folderOpen tasks, systemd user services, and .github/workflows/codeql.yml. Concrete IoCs and the gh-token-monitor wipe ordering before rotation.