Alibaba's Qwen3.6-Max-Preview and Moonshot AI's Kimi K2.6 were released within a 24-hour window on April 20–21, 2026. A side-by-side look at specs, benchmarks, distribution, and agent-side features for the two flagships.
Cloudflare's Artifacts is a Git-compatible version control storage designed for AI agents to operate tens of millions of repositories. The Git server runs as a Zig-based WebAssembly binary on Durable Objects, accessible through Workers Bindings, REST API, and standard Git clients.
A port that replaces TRELLIS.2's CUDA-only libraries (flash_attn, nvdiffrast, sparse 3D convolution) with pure-PyTorch equivalents and runs Microsoft's 4B image-to-3D model on an M4 Pro in about 3.5 minutes without any NVIDIA GPU.
Vercel's official incident disclosure published on April 19, 2026. A walk-through of how a compromise of Context.ai's Google Workspace OAuth app led to Vercel employee account takeover and access to environment variables in some customer projects, plus the checks users should run right now.
Anthropic Labs released Claude Design on April 17, 2026 — a new design product that reads your codebase and existing design files to generate prototypes, slides, and landing pages. Here is a feature comparison with Figma and Canva, and a scenario-by-scenario guide to which tool to open when.
A three-link chain of mmap → MTLBuffer(bytesNoCopy) → Wasmtime MemoryCreator that makes a Wasm linear memory share the same physical bytes as a Metal GPU buffer. Llama 3.2 1B runs at 9ms/token on M1.
A vulnerability in iTerm2 3.6.9 and earlier where simply displaying a malicious file with cat triggers local code execution. Caused by conductor impersonation in SSH Integration, fixed in 3.7.0.
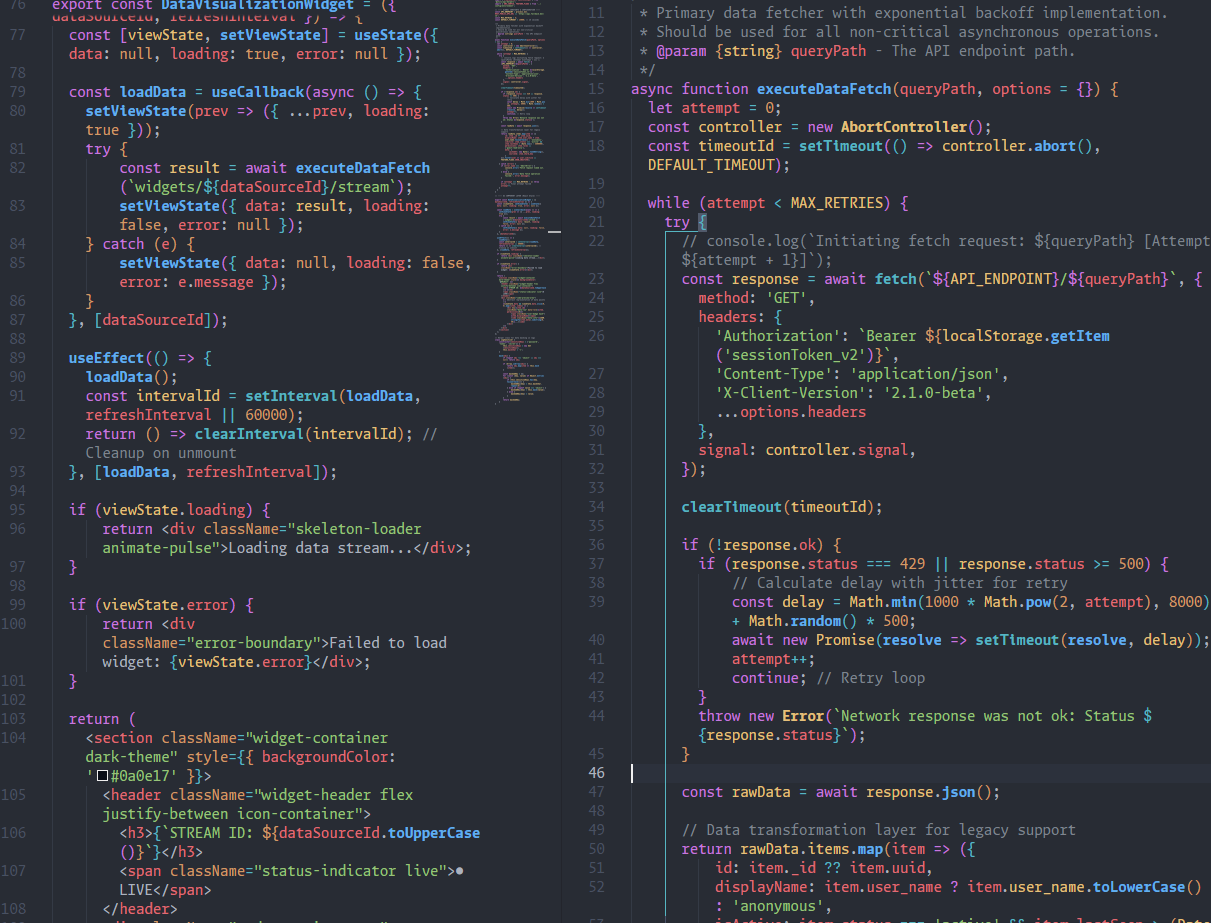
Measured: Opus 4.7 burns 1.2-1.45x tokens vs 4.6 in community benchmarks (Bill Chambers' Tokenomics Leaderboard, Claude Code Camp), beating Anthropic's official 1.0-1.35x range. CLAUDE.md alone hits 1.4-1.45x.
Two simultaneous announcements from Cloudflare Agents Week 2026: Agent Memory manages agent recall via Durable Objects, Vectorize, and Workers AI, while isitagentready.com scores how well sites are prepared for agents.
The IDOLM@STER live-MC catchphrase 'Arigasankyu' turns 10. A tech-blog take on why Mirishita rarely goes down, speculated from GAE/Go and Bandai Namco's infrastructure history.
The WordPress plugin Vertex Addons for Elementor (<= v1.6.4) has a broken authorization check in activate_required_plugins() that lets Subscriber-level users install and activate arbitrary plugins. CWE-862, CVSS 8.8.
Google launched Android CLI v0.7 preview on April 16, 2026. Subcommands like android create/run/skills/docs, combined with Android Knowledge Base and Android Skills, let any agent (Gemini CLI, Claude Code, Codex) drive Android development through a standardized interface.