An experiment log investigating USB/WiFi/BLE connection specs of the Nikon COOLPIX A1000 and attempting PC connection via OSS tools. PTP/IP protocol analysis and gphoto2 testing results.
Alibaba's Qwen team released Qwen3.6-35B-A3B as open weights. A 40-layer hybrid of Gated DeltaNet, Gated Attention, and MoE hits 73.4 on SWE-bench Verified, 37.0 on MCPMark, and 1397 on QwenWebBench.
Anthropic released Claude Opus 4.7 on April 16, 2026. The staged rollout adds an xhigh effort tier, self-verification before returning, and roughly 3x higher-resolution image input, while intentionally capping cyber capability under Project Glasswing.
Cloudflare Email Service reached public beta. Workers bindings for sending, onEmail hooks on top of Email Routing for receiving, and Agents SDK integration make it straightforward to give agents an email channel.
CVE-2026-34197 (CVSS 8.8), an RCE in Apache ActiveMQ Classic that lurked for 13 years, was added to the CISA KEV catalog. Authenticated attackers can achieve remote code execution via the Jolokia API. Affects versions below 5.19.4 and 6.0.0–6.2.2.
On April 14, 2026, Jamie Thain submitted draft-thain-ipv8-00 to the IETF. It proposes an internet-layer protocol that wraps all of IPv4 inside a 64-bit address and bundles DHCP, DNS, auth, and logging into a single Zone Server. Contrasting it with how IPv6 was built by WG consensus, I walk through the 'no flag day, just software update' design.
The BASE collaboration, with RIKEN as a core member, physically moved antiprotons from the CERN AD hall to a separate lab while keeping them confined inside BASE-STEP. For readers who picture antimatter as 'everything reversed,' this sorts out how it differs from isomers, what annihilation actually does, how Penning traps work, and why you would want to move antiprotons at all.
Developer-focused notes on Supabase's April 2026 update — which changes are actually useful in practice. Multigres Operator going open source, docs accessible via ssh supabase.sh, and GitHub integration finally landing on the free plan.
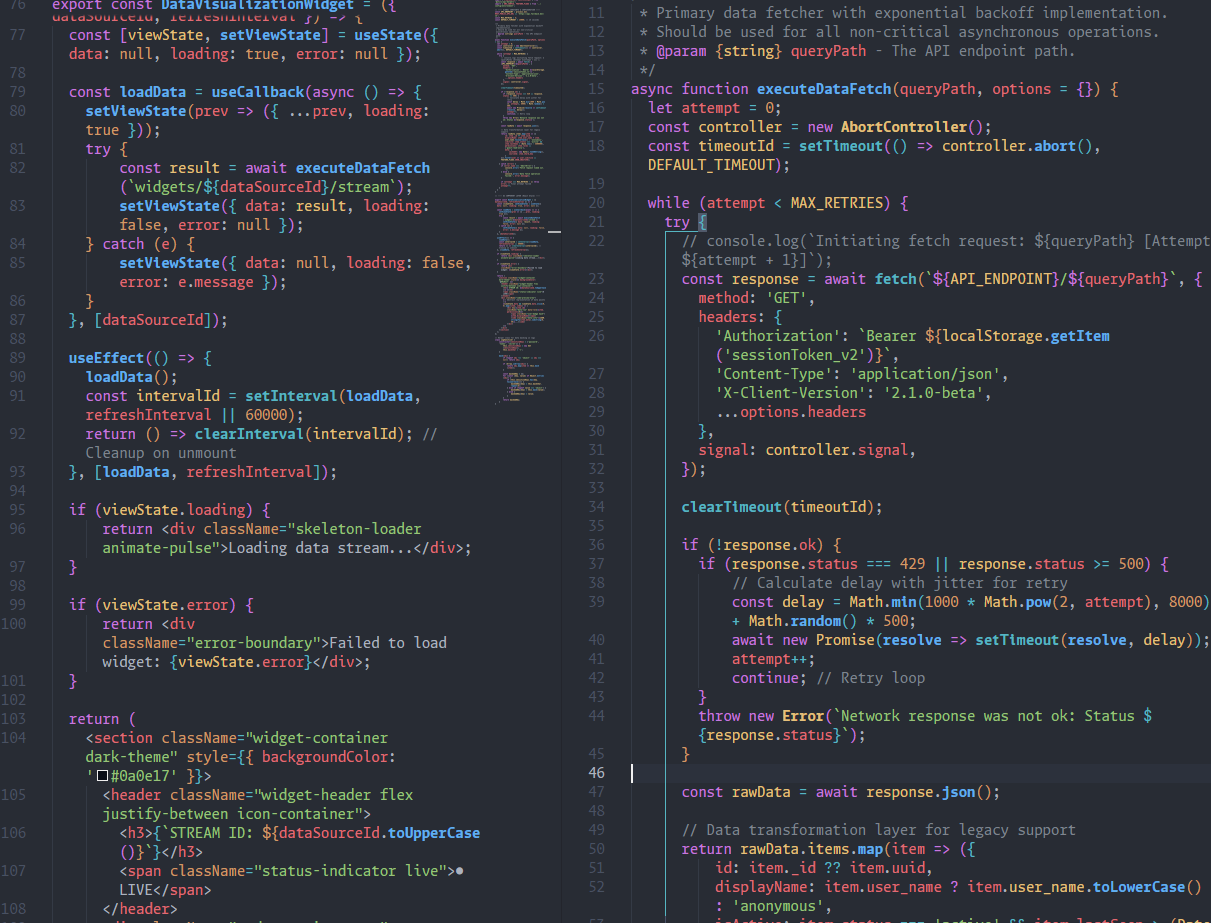
An Astro 6 build on Vercel started failing because a generated `_astro/*astro_type_script*` chunk hit an esbuild parse error. Stripping TypeScript syntax was not enough. The stable workaround was to bypass Astro's script transformation path with page-local imports from `public/vendor`.
Z-Image has its own pixel art LoRAs, but can they actually convert photos to pixel art via i2i? Tested Z-Image Turbo, base model, and compared with Illustrious on M1 Max 64GB.
Tested WAI-Anima v1 on Windows + RTX 4060 Laptop GPU (8GB VRAM). Headless execution via ComfyUI API hit a tqdm OSError on startup, but launching ComfyUI normally generates a single image in 55 seconds. Includes the workaround and timing notes.
Three announcements from Day 3 of Cloudflare Agents Week 2026. Project Think is a batteries-included agent framework built on Durable Objects. Browser Run adds Live View, Human in the Loop, and WebMCP. Workflows v2 redesigns the control plane for 11x concurrency.