キャラLoRAのベースをWAI-Animaから本家Anima-Baseに変えて焼き直す
 目次
目次

追記 (2026-06-05): この Anima-Base 版 LoRA に残っていた「standing でも脚が曲がる」癖を、素材を足さず引いて直した続編を書いた。→ キャラLoRAの「変なポーズ」は素材を足さず引いて直す
前回 けいちゃん LoRA v1 は WAI-Anima v1.0 上で、WAI-Anima 自身が生成した91枚を学習素材にして焼いた。結果は「自家中毒(学習素材とベースが同分布)で ep20 で頭打ち、ただし顔の一貫性は Anima 由来の弱さをそのまま継承して揺れる」というものだった。
その v1 記事が明示的に次回送りにした疑問が2つある。
- 分布のズレた素材で焼いたら顔が締まるのか(v1 は自家中毒で収束は速いが顔が揺れた。外部分布ソースなら?)
- (Anima-Base v1.0 比較記事の結論より)Anima-Base 本体で運用したいなら、その上で LoRA を再学習する必要がある。では実際に Anima-Base 直で焼いたらどうなるか
v2 はこの2つに同時に答える。変えるのは2点だけ。
- ベースは WAI-Anima → Anima-Base v1.0(CircleStone Labs 本家、美的チューニングなし)
- 素材は Anima自家生成91枚 → Qwen Image Edit AIO 生成の70枚(Anima系の外=分布ズレ)
動機は単純で、派生6種にLoRAを当てた記事まで全部 WAI-Anima を土台にしてきたので「WAIばっかりでもな」という話。
v2 は v1 より良くできた。トリガー単体で keichan が出る実用 LoRA になり、顔の目標忠実度も v1 を上回った。ただしインテークの天井と、ポーズ・アングルが学習分布に縛られる癖は残った。
学習中の経過(内蔵サンプル)
run1(keichan v2, Anima-Base, ep180 = 12,600 step)は RunPod RTX 4090 で回した。0.34 it/s(v1 の RTX 6000 Ada と同等)、VRAM 約11GB。save_every:1 で全エポック保存し、ローカルへ自動同期した。
学習元(目標)/ ベースライン(step0 = LoRA未適用の素 Anima-Base)/ ep10 / ep50 / ep88 の顔比較。
| 段階 | 状態 |
|---|---|
| 学習元(緑枠) | 目標。濃い金髪・碧眼・太いインテーク・青リボン |
| ベースライン (step0) | 茶髪・茶目。keichan 未学習なので素の Anima-Base が出る(プロンプト記述の前髪・青リボンだけ拾う)。美的チューニングなしなので塗りも地味 |
| ep10 | 金髪+碧眼がロック(碧眼は ep6 付近で固定)。顔はまだ「整った金髪碧眼の別人」。前髪は流し気味でぱっつんになりきらない |
| ep50 | ep10 とほぼ同じ。色は完成、顔・髪型構造の変化は乏しい |
| ep88 | 依然プラトー。金髪碧眼は安定だが、keichan 固有のぱっつん前髪・太い前向きインテークが内蔵サンプル上では弱いまま。顔は「無個性な金髪碧眼」ゾーンに留まる |
v1(Anima自家生成素材)は ep1 で金髪+碧眼まで乗ったが、v2(Gemini起点・分布ズレ素材)は色こそ ep6 でロックしたものの、顔は ep10〜88 でほぼ横ばい。色が決まった後の「顔・髪型構造の収束」が内蔵サンプル(N形式・seed42 固定の単一条件)では進みにくい。
ただし v1 の教訓で内蔵サンプラーは単一条件ゆえ実力を出し切れないことがあるので、この「プラトー」は確定ではなかった。実際、後述するローカル K/N/KT × 複数 seed マトリクスでは印象が変わる。内蔵サンプルだけ見ると Anima-Base 上では色は乗っても顔が keichan 固有まで締まりきらないように見えたが、これは内蔵サンプルの過小評価で、「Gemini 素材で顔が締まるか」の最終的な答えは Yes(後述)。
Codex(gpt-5.5)による客観採点
目視だと差が微妙で判定しづらいので、キリのいいエポック(ep20/40/60/80/90)の内蔵サンプルを学習元と一緒に Codex CLI(gpt-5.5)へ投げ、項目別に 0-5 で採点させた(v1記事の水着画像フレーミング検証と同じ手口)。
| epoch | 髪色(金) | 目色(青) | ぱっつん前髪 | エアインテーク | 顔/同一性 |
|---|---|---|---|---|---|
| 20 | 4 | 5 | 4 | 2 | 3 |
| 40 | 4 | 5 | 4 | 3 | 3 |
| 60 | 4 | 5 | 4 | 3 | 4 |
| 80 | 4 | 5 | 4 | 3 | 4 |
| 90 | 4 | 5 | 4 | 3 | 4 |
Codex の所見は 収束は頭打ち。ep20 以降で髪色・目色・前髪は安定するが、エアインテーク(前向きスクープ)は 3/5 で頭打ち、顔・同一性も 4/5 で頭打ち。最良は ep80(ep60〜90 はほぼ横並び)。「髪色と顔が完全に寄っているか」は No(髪色は近いが顔とインテーク形状が未完成)。
目視の印象(色は乗ったが顔・インテークが keichan 固有まで締まらない)を外部評価が定量的に裏付けた形。Anima-Base × Gemini素材は「色は乗るが顔・インテークの作り込みに天井がある」という評価になった。ただしこれは内蔵サンプル基準で、フル推論での最終評価は後述で上方修正される。髪色すら 4/5 で満点でないのは、前述の後髪・毛先の二段トーンが影響している。インテークが 3/5 で止まるのは v1 の「素材のインテーク誇張が足りないと押し返せない」結論と一致する。
なお run1 完了後は同じ Pod で run2(kanachan を Anima-Base で焼き直し) を自動連鎖させた(併走実験。詳細は後述)。
なぜ Anima-Base v1.0 にするのか
Anima-Base v1.0 比較記事で、WAI-Anima 向けに焼いた既存 LoRA を Anima-Base v1.0 に載せると軽い指定では崩壊する(ヒット率22%、青肌/ストレート化/茶色崩壊)ことを確認した。そのときの結論が 「本格運用には v1.0 ベースでの LoRA 再学習が必要」。だから Anima-Base で使いたいなら Anima-Base で焼くのが筋になる。
技術的にはほぼ差し替えだけで済む。
| 要素 | WAI-Anima v1 | Anima-Base v1.0 |
|---|---|---|
| 性格 | preview3-base 派生の WAI 調整版(美的チューニングあり) | CircleStone Labs 本家の真のベース(美的チューニングなし) |
| DiT | Cosmos-Predict2-2B | 同左 |
| TE | Qwen3 0.6B | 同左(全派生共通) |
| VAE | Qwen Image VAE | 同左(全派生共通) |
| LLMアダプタ | 共通・学習中は凍結(llm_adapter_lr=0) | 同左 |
アーキは完全同一で TE/VAE/アダプタは共通。だから学習側で変えるのは transformer_path 一行だけ。公式の LoRA 学習推奨(rank32 / lr2e-5 / アダプタ凍結)も v1 の設定とそのまま一致する。
唯一差が出るのが 美的チューニングの有無。Anima-Base は素だと地味な絵が出る設計(クオリティタグ / アーティストタグ前提)。これは
- 学習中の内蔵サンプルが WAI 時代より地味に見える(が異常ではない)
- 推論時は
masterpiece, best quality等のクオリティタグ、必要なら@artist(@必須)を前提にする
という形で運用に出る。学習キャプション側は既に masterpiece, best quality, safe プレフィックス入りなので問題ない。
学習素材(70枚・Gemini起点の混合パイプライン=完全分布ズレ)
素材は単一モデル生成ではなく、Gemini を起点にした混合パイプラインで作った。Anima系の画像は一切使っていない。
| 区分 | 枚数 | ファイル | 出自パイプライン |
|---|---|---|---|
| バストアップ(真顔・元素材) | — | — | Gemini 生成 |
| バストアップ(表情差分) | 26 | 0001〜0026 | 上の真顔を Photoshop 生成塗りつぶし(Gemini Nanobanana Pro)で表情替え |
| 立ち絵(元素材) | — | — | Gemini 生成 |
| 立ち絵(最終・各種ポーズ衣装) | 44 | 01〜50(欠番あり) | 上を Qwen Image Edit AIO で出力 |
v1 の素材は WAI-Anima 自身の生成画像(=ベースと同分布=自家中毒)だったのに対し、v2 は Gemini 起点・Anima 不使用=ベースから見て完全に別分布。これが狙いの「分布ズレ素材」になる。
ここが重要で、前作 kanachan も Gemini 生成素材で、その場合の最適点は ep150 だった。v2 も同じ Gemini 起点なので、v1(Anima自家生成・ep20頭打ち)ではなく kanachan 寄りの深い収束(ep100〜150帯)になるという予測が立つ。混合パイプライン(Gemini + Photoshop生成塗り + Qwen Image Edit)なので分布が単一でない点も、収束カーブに影響するかもしれない。
注意点として、バスト26枚は実寸 ~495px と学習解像度 1024 より小さく、バケットで上にスケールされる。顔・インテークの最重要ディテールがここに集中するので、再現が甘ければ v3 で高解像に焼き直す余地がある。
キャプションは v1 設計を踏襲(触っていない)
v1 のキャプション設計(トリガー keichan 吸収+自然言語2文+構造タグ独立+品質プレフィックス)をそのまま使う。全身とバストアップ(表情)で構図整合は取ってあり、今回はキャプションは一切いじらない。hair intakes はタグ列に置かず自然言語でのみ言及するのも v1 と同じ。
v1 → v2 の設定差分
- transformer_path: "models/transformers/waiANIMA_v10.safetensors"
+ transformer_path: "models/transformers/anima-base-v1.0.safetensors" # ★本家ベース
- data_dir: "/workspace/datasets/keichan" # 91枚(Anima自家生成)
+ data_dir: "/workspace/datasets/keichan-v2" # 70枚(Qwen Image Edit AIO素材)
- output_name: "keichan-waianima-v1"
+ output_name: "keichan-animabase-v2"
rank 32 / alpha 32 / lr 2.0e-5 / repeats 4 / bf16 / xformers:false
save_every:1 / sample_every:1 / seed:42 # ← 全部据え置きTE/VAE パス・アダプタ凍結・サンプルプロンプト(v1 と同じ N 形式・seed 42)は変更なし。ベースとデータと出力名以外は完全に v1 と同条件にして、差を「ベースと素材の違い」に絞り込む。
エポック方針
- v1(自家中毒・分布ズレ無し)は ep20 頭打ちだった。
- v2 は 素材が分布ズレ(Qwen Image Edit AIO)+ ベースが素の Anima-Base(WAI より「親切でない」)。両方とも収束を遅くする方向に働くので、ep20 では足りない見込み。
- 比較になるのが kanachan v4。Gemini 生成(分布ズレ)素材は ep150 が最適点 だった。v2 もこの帯に寄る可能性がある。
- ただし2変数を同時に変えるので最適点は未知 → ep180 フルで回し、
save_every:1で全エポック保存してローカルでスイープ。
RunPod セットアップ
ツールは v1 と同じ AnimaLoraToolkit。Volume は前回分が無いのでイチから構築した。
GPU 選定(6000 Ada 在庫切れ → 4090 で十分)
RTX 6000 Ada が在庫切れ・出ては消えるを繰り返したので、RTX 4090 (24GB) に切り替えた。
- v1 実測の VRAM 使用は 10.89GB。4090 の 24GB に対して半分以下で余裕。6000 Ada の 48GB は過剰だった。
- 4090 は Ada 世代=6000 Ada と同じ cu124 スタックなので、セットアップは無変更。
- 結果は GPU 非依存(総 step・seed・bf16 固定)。GPU が変わっても焼き上がる LoRA は同じで、変わるのは it/s(時間・コスト)だけ。
- Blackwell(RTX 5090 / RTX PRO 6000 / B200)は避ける。sm_120 が cu124 で動かず、cu128 セットアップ地獄になる。
テンプレは torch 2.4 → 2.5.1+cu124 にアップグレード
RunPod テンプレは torch 2.4 / 2.8 しか出なかったので 2.4(cu124)を選択。最終的に乗せたいのは v1 で確定した torch 2.5.1+cu124 × transformers >=4.51,<5.0。
理由(v1 で2回燃やして確定したやつ)。
- Qwen3 TE には
transformers >= 4.51が要る(4.45 だとmodel type qwen3 を認識できない) - 素の
pip install transformersは 5.x を引き、それはtorch.distributed.tensor.device_meshを要求 → torch 2.5+ 必須 - → 当たりは torch 2.5.1+cu124 × transformers
>=4.51,<5.0
2.8 テンプレ(cu128)を選ばないのは、toolkit + transformers 5.x が未検証スタックになり破壊的変更を踏むリスクがあるため。
# requirements.txt は使わない(xformers が torch を cu130 に置換して Ada が死ぬ)
pip install --upgrade torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 \
--index-url https://download.pytorch.org/whl/cu124
pip install --upgrade "transformers>=4.51,<5.0" \
einops safetensors diffusers accelerate peft lycoris-lora omegaconf \
tqdm Pillow numpy lpips pytorch-fid pytorch-msssim scipy scikit-image \
matplotlib pandas pyyaml psutil rich tiktoken sentencepiece protobufモデルは Pod 上で直DL(家の上りより桁違いに速い)
# Anima-Base v1.0 (4.18GB) / VAE (243MB) を HF から直 curl(トークン不要)
curl -sL -o models/transformers/anima-base-v1.0.safetensors \
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/diffusion_models/anima-base-v1.0.safetensors
curl -sL -o models/vae/qwen_image_vae.safetensors \
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/vae/qwen_image_vae.safetensors
# TE は Qwen3-0.6B-Base を models/text_encoders/ にマージ(config類は toolkit 同梱)
hf download Qwen/Qwen3-0.6B-Base tokenizer.json vocab.json model.safetensors \
--local-dir models/text_encodersスモークテスト → 本番
Transformer の7分ロード前に TE ロードをスモークテストで先に通す(v1 で踏んだ「7分待ち→TEで落ちる」を回避)。
python -c "
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, T5Tokenizer
from transformers.models.auto.configuration_auto import CONFIG_MAPPING
print('torch:', torch.__version__, '| cuda:', torch.cuda.is_available())
print('qwen3:', 'qwen3' in CONFIG_MAPPING)
AutoModelForCausalLM.from_pretrained('models/text_encoders', torch_dtype=torch.bfloat16, device_map='cpu')
print('>>> SMOKE TEST PASSED <<<')
"
# 通ったら tmux で起動
tmux new-session -d -s train "python anima_train.py --config ./config/train_keichan_v2.yaml 2>&1 | tee /workspace/output/keichan-v2/train.log"既知の地雷リファレンス
| 罠 | 対処 |
|---|---|
requirements.txt の xformers が torch を cu130 に置換 → Ada 即死 | 手動依存。xformers: false |
| transformers 5.x は device_mesh 要求 / 4.45 は Qwen3 未対応 | >=4.51,<5.0 に固定 |
| Transformer 7分ロード後に TE で落ちる | 起動前にスモークテスト |
| 家からの scp が激遅 | モデルは pod 直DL(240Mbps)、データセットだけ scp(88MB) |
huggingface-cli download 非推奨 | hf download <repo> <files> --local-dir |
| Anima-Base は素だと地味 | 推論はクオリティ/アーティスト(@)タグ前提 |
結果検証(K / N / KT マトリクス)
v1 と同じ3形式 × seed 42/100/200 でスイープ。検証ベースは Anima-Base v1.0(学習元と揃える)、Turbo LoRA 併用 8-step。
| 形式 | 内容 |
|---|---|
| K(トリガーのみ) | keichan + 構図タグ |
| N(自然言語併用) | 学習キャプションの自然言語を足す |
KT(hair intakes タグ補助) | 推論で補助線を引く |
成功基準(トリガー keichan だけで6点)は、金髪 / ぱっつん前髪・非姫カット / 長いインテーク / ハーフブレイド / 青リボン / 青目。
完走後、全エポックがローカルに揃ったので、Anima-Base v1.0 + Turbo LoRA 8-step(er_sde/simple, CFG 1.0, 832×1216)で ep20/50/80/120/180 × K/N/KT × seed42/100/200 = 45枚を生成した。下は seed42 のグリッド(行=形式、列=epoch、掲載は制服を指定した着衣版)。

これを目標デザインと並べて Codex(gpt-5.5) に評価させた。
- K(トリガーのみ)で主要デザインが安定再現。金髪・碧眼・ぱっつん前髪・編み込み・青リボンは全 epoch でトリガー単体で出る。つまりAnima-Base 上でも実用域。衣装はトリガー単体だとバラつく(裸〜ランダム私服)が、指定すれば制服で安定する(掲載グリッドは制服指定の着衣版)。一方 エアインテークの太さ・向きは完全固定ではない(epoch・構図で細くなったり横髪寄りになる)。
- N(自然言語併用)が最良。K より顔の安定感が増し、インテークも整理されて目標顔に近い。破綻が少ない。
- KT(タグ補助)は衣装・構造指定には効果が出るが、顔・インテークは N より良くない。ep120 KT は質感が崩れ気味で、キャラ評価には不利。
- エポックは ep80〜180 でほぼ頭打ち。Codex のマトリクス採点では ep180 が僅差で上に出たが、目視で差が分からず再テストしたところ実質 ep120〜150 で十分だった(後述)。
- 総合判定は 「使えるキャラ LoRA」。トリガーだけで主要デザインが出るので実用域。インテークの太さ・向きを厳密に固定したいならプロンプト補助前提。
推奨運用は ep120〜150 + N 形式(ep180 を推さない理由は後述の再テスト)。インテークを強調したい時だけ hair intakes 等を足す(KT は服指定に回す)。
注目すべきは、内蔵サンプラー(N形式・単一seed・25step)で見えた「無個性プラトー」が、Turbo 8-step のフル推論ではトリガー単体でも安定して keichan が出る点。内蔵サンプルは実力を過小にしか映さない(v1 で記録した「内蔵サンプラーは単一条件ゆえ判断材料が薄い」の再確認)。「色は乗る・顔も実用十分・インテークだけ天井」が keichan v2 の結論。
ポーズ・アングル&背面リボン検証(制服・ep180)
正面ポートレートが良くても、横・後ろ・全身まで安定して出るかは別問題だ。学習データに構図の偏りがあるとそこが崩れる恐れがあるので、ep180 で全身・横顔・3/4・後ろ姿・座り・走り・あおり・ふかんを振った(制服指定、Anima-Base + Turbo)。

キャラ造形(制服・金髪・リボン)はどのアングルでも堅牢に出る。ただし精密な角度制御は別問題で、弱い指定は Anima の「3/4正面アトラクタ」に引き戻される(横→3/4横、後ろ→3/4後ろ、あおり→正面、3/4→なぜか膝立ちに化ける)。派生記事で記録した「Anima の最強アトラクタは3/4」が、新キャラ+Anima-Base でも再現した。
強い重み(Anima は重み高め推奨)で撃ち直すと切り分けられる。

| 角度 | 強指定の結果 |
|---|---|
| 立ち3/4 | standing で膝立ちは直るが、3/4というより正面寄り+脚が曲がった「可愛い立ち」(綺麗な直立3/4ではない) △ |
| 真後ろ | (from behind:1.6) で真後ろ=アングルは出る(背面リボン見える)。ただし脚は歩き姿勢で曲がる |
| 真横 | 正面からは離れるが純プロファイルにはなりきらない △ |
| ふかん | (from above:1.7) で寄り+見下ろし角+見上げ顔まで出る(上半身なので脚問題なし) ✅ |
| あおり | 重み 1.7 でも完全に正面で変わらない ❌ |
そして全身を撃つと、ふかん(上半身)以外ほぼ全部で脚が曲がった「ポーズ立ち」になり、まっすぐ直立しない。「普通こんなに脚が曲がるか?」と思うが、素のモデルなら曲がらないので、これはこの LoRA 固有。原因は学習素材の全身44枚が Qwen Image Edit 生成の「キャラ立ち絵」ポーズ(歩き・体重移動・3/4スタンス)ばかりで、棒立ち(直立・両足揃え)が1枚も無かったこと。LoRA は「keichan の全身=ポーズ脚」を学習したので、standing と言ってもポーズ脚で出る(Anima のモエ立ちポーズ嗜好も上乗せ)。出力のポーズ分布は学習のポーズ分布をそのまま写す。これも「学習/ベースに無いものは出ない」の一例。
つまり学習データ・ベースにある構図は明示+強指定で制御できる(特に standing 必須、入れないと膝立ち等に化ける)。無い構図は重みで殴っても湧かない。「全アングル自由」ではなく「分布内の角度は強指定で制御可、分布外は不可」が正確。
面白いのが ふかんは出るのにあおりは完全に出ない非対称。これはアニメ美術の構図分布の反映と思われる。「ふかん=見上げてくる可愛い子」は萌え絵の超定番でベースが大量に持っているが、「あおり=見上げる構図」は萌え系に乏しく(アクション寄り)、ベースも LoRA 素材も持っていない。だからふかんは強指定で湧き、あおりは何をしても湧かない。「分布外は不可」の中でも、ベースの既定知識の有無でさらに割れる。
後ろのリボン結びが見えるか(keichan の核心)
keichan はハーフブレイドアップで、後ろを青リボンで結んでいるのが見分けの決め手。これは背面アングルでしか確認できない。後頭部クローズと振り返りで確認した。

後頭部に青リボンの蝶結び+ハーフアップの編み込みが正しく出る(結び目から変に毛が垂れる失敗もない)。学習データに後ろ姿はわずかしか入れていないのに背面構造が出たのは、ブレイド・リボン結びが Anima のデフォで描ける意匠だから(LoRA はキャラに紐付けて呼び出すだけで済む)。これはインテークが天井な理由の裏返しで、同じ原理になる。
ベースがデフォで持っている造形(ブレイド・リボン・サイドポニー)は少数データでも焼ける。持っていない造形(エアインテーク)は大量データでも天井。 必要学習量と天井はベースの既定知識の有無で決まる。
細部のサイズは「構図内の見かけサイズ」に比例(フレーミング原理)
ただし後ろ構図にすると青リボンが小さくなる。同 seed・同 LoRA で構図だけ変えると、リボンサイズが後頭部の見かけサイズに完全比例する。
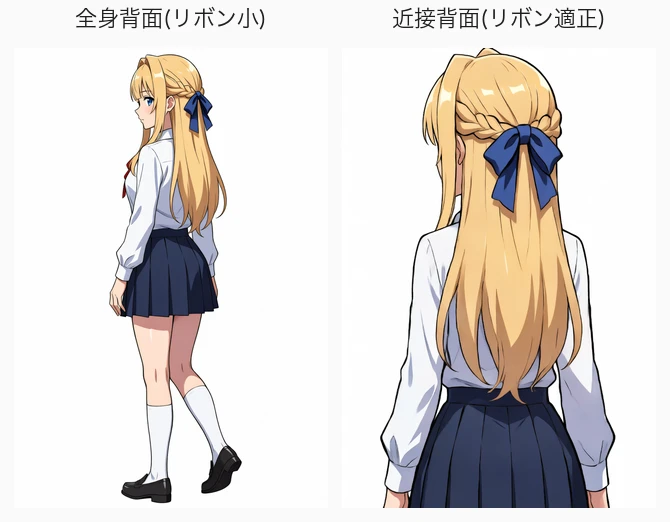
v1 で記録した「インテーク強度は顔の見かけサイズに比例」と同じフレーミング原理で、keichan の特徴(インテーク・リボン)が全部この法則に乗る。見分けのつく特徴は、それが大きく写る構図で撮るのが運用則。
サイズタグ((blue ribbon:1.6), large bow)で殴ると、Anima-Base + LoRA では意外と反応してリボンが大きくなった。アクセサリのサイズ制御は全モデル共通の弱点で失敗の出方がアーキごとに分かれる(QIE=効かない / Gemini=盛りすぎ / 素の Anima・IL=適当)が、本ケースは LoRA がリボンを学習済みのぶんほどほどに反応した(フレーミングの寄与も混ざるので、確実なレバーはやはり構図)。
ポーズ・アングルはトリガーが学習分布を体現する
ポーズ/アングルの挙動を追い込むと、一つの原理に収束した。トリガーワードが学習素材のポーズ・アングル分布をそのまま体現し、分布外は抑制する。
(1) standing は無関係、ポーズはトリガーが運んでいる。 standing の有無で立ち姿は変わらない(同 seed で同じポーズ脚)。keichan はポーズ付き全身44枚すべてに常駐するのでポーズ信号を一番濃く吸う=ポーズ立ちの真犯人はトリガー keichan 自身。standing は薄い受け皿で、付けても外してもトリガーのポーズ立ちに支配される。
(2) ポーズ立ちか直立かはデータ分布で決まる(ベース非依存)。 keichan v2 / kanachan v2 / kanachan v1 を同一中立プロンプト(full body, standing, front view、強制なし)で並べた。

keichan v2(Anima-Base, 動きデータ)は脚曲げポーズ、kanachan v2(Anima-Base, 直立ターンアラウンドデータ)はまっすぐ立つ、kanachan v1(WAI, 同データ)もまっすぐ。同じ Anima-Base 上で keichan はポーズ立ち、kanachan は直立。これはデータ効果(ベースの差ではない)。kanachan の全身が「直立ターンアラウンド(前後左右斜め)」で standing をクリーンに貼っていたから、トリガーも standing も「直立」を学習した。
(3) あおりはベースが出せるのにトリガーが抑制している。 (from below) であおりが出ない件を、トリガー無し(ベースのみ)で撃って切り分けた。

ベース単体(トリガー無し)→ あおり 普通に出る(スカートでもズボンでも。当初疑った NSFW回避でもなく、スカートで上向き角でも普通に描く)。ところが keichan トリガーを乗せると あおり 抑制。ベースはあおりを出せるのに、トリガーが学習分布(あおり無し)で上書きして消している。LoRA 強度を 0.3 まで下げると あおりが戻る代わりに同一性が崩れる(あおりと keichan性が密結合)。kanachan も全く同じ挙動(あおり無し→抑制、0.3で戻る)。
一方 ふかんはトリガーを乗せても出る。ふかんはベースが元から強く出すので、トリガーの抑制を上回って出る。あおりはベースが元から弱く、抑制に消されて出ない。抑制を上回れるかは「ベースがその構図をどれだけ強く持っているか」で決まる(ふかん=萌え絵の定番でベースが強い、あおり=萌え系に乏しくベースが弱い)。
(4) トークン汚染の一般則。 standing がポーズ立ちになったのは、standing を貼った画像が 3/4・腕上げ等のポーズ付きで、standing がそれと同居したから。タグ→特徴の結合は排他でなく共起の統計(複数トークンで分配)なので、three-quarter 等を別に振っても standing は漏れ受けする。だから同じタグを貼る画像の中身を揃えないと、一般タグが意図しない属性で汚染される。
再テストでep180推奨を取り下げ(ep120〜150で十分)
Codex はマトリクスで keichan の総合ベストを ep180 としたが、目視では ep120〜180 の差が分からなかった。そこで ep100/120/150/180 を中立プロンプト(強制なし)で並べ直した。
結果、全エポックで脚が曲がったポーズ立ちのままで、ep100/120 と ep180 でポーズの強さに差は無い(ep100 の時点で既にしっかり脚が曲がる)。つまりポーズ立ちはエポックで強まるのではなく ep100 で一定。ポーズ付き全身データが早期に焼き付くデータ駆動で、深く焼いても増減しない。「ポーズは過学習で深いほど強まる」という見立ては外れだった。
そうなると ep180 を推す根拠も消える。顔は ep80 でプラトー、ポーズ立ちは ep100 で一定なので、ep180 は ep120〜150 に対して得が無い(顔も立ち姿も変わらない)。
だから keichan の推奨は ep180 から ep120〜150 に下げる。理由は ep180 が壊れるからではなく、深く焼いても得が無いから。同じ Gemini 素材で kanachan が ep150 最良だったこととも整合する(当初疑った ep180 の過学習は、後述の多 seed 検証で否定された)。
分布ズレ素材で顔は締まったか → Yes(目標忠実度で v2 が勝つ)
v1(学習素材 = Anima 自家生成)と v2(= Gemini 起点)を同 seed で並べた(v1 は学習元の WAI-Anima 上、v2 は Anima-Base 上)。最初は口の出ない calm 顔で比較していたが、口が無い顔で「顔の忠実度」を判定するのは不適切なので、笑顔(smile, open mouth)で口を出した版で評価し直した。

Codex(gpt-5.5) に評価させた。
- 目標への顔の忠実度は v2 が上。v2 は目標の細め目・顔の縦横バランス・中央前髪に寄る。v1 は目が大きく丸く幼く、安定だが「別のアニメ顔」に収束。
- 口元も v2 が近い。目標は「歯を見せた控えめなスマイル」で v2 の口形が一致するが、v1 は口が大きく開いて別種の笑顔になる。
- 一貫性は v1(seed 間で安定)だが、その安定顔が目標からズレている。
- インテークは v1 が強め、v2 は弱め〜中。v2 は素の Anima-Base ぶん生成品質は粗い。
- 結論(Codex)。口あり条件でも目標に忠実なのは v2(口を含めるとむしろ優位が強まる)。
つまり「分布ズレの高一貫ソース(Gemini)は顔を目標に寄せる」が支持された。v1 の自家中毒素材は「安定だが目標とは別の顔」に固まったのに対し、v2 は目標方向に締まった。トレードオフは v2 のインテーク弱さと素の品質の粗さ(地味な Anima-Base 由来)。本文前半で内蔵サンプルを見て「顔は締まりきらない」と渋く評価した中間結論は、顔の「質」ではなく「目標忠実度」で見れば v2 ポジティブに上方修正する。
kanachan を Anima-Base で焼き直す(併走実験)
keichan と同じ「Gemini 素材 × Anima-Base」を別キャラ kanachan(茶髪・サイドポニー・アホ毛)でも焼いた。狙いは2つ。keichan の早いプラトーが「ベースの差」か「特徴の差」かの切り分けと、Anima-Base で kanachan 最大の難所であるサイドポニーの向きが出るかの確認。
T/N/TN マトリクス(トリガー単体で安定、最良 ep150)
ep30/60/100/150/180 × T/N/TN(seed42、制服指定)。

Codex(gpt-5.5) の評価では、T(トリガーのみ)でも茶髪・アホ毛・サイドポニー・青シュシュが全 epoch で出てキャラは安定し、最良は ep150。ep180 は seed42 の TN で手・棒状の小物・口元の液体っぽい描写が勝手に混入し、当初これを過学習と判定した(ただし後述の多 seed 検証で覆る)。

当初はこれをプラトー後の終盤劣化(=過学習)と見て、kanachan を ep180 まで回すのは過剰と判断した。デフォルトは ep150。ただしこの「ep180 過学習」判定は seed42 の1枚に依存していて、次の多 seed 検証で覆る。
「ep180過学習」は単一seedの誤判定だった(多seed検証)
seed42 の1枚で「ep180 は過学習」と断じたのが気になり、ep180 と ep150 の TN を seed 100/200/300 で撃ち直した。結果、ep180 は seed42 以外(100/200/300)では破綻しない。s42 だけがタイを口元に寄せる変ポーズ+手の破綻という最悪のロールで、ep150 の TN にも同じ「手を胸・口元に寄せる」傾向は出る。keichan の ep150 も手が写らない構図の3 seed はすべてクリーン(ep120 も同様)。
つまり s42 の崩れは過学習による一貫した劣化ではなく、Turbo 低ステップの単発の生成事故(手の破綻と、タグ盛りが誘発する変ポーズ)だった。同じ epoch でも seed を変えれば大半クリーンに出る。過学習なら同 epoch の多 seed で一貫して崩れるはずだが、それは起きていない。
ここは方法論の戒めでもある。単一 seed のアーティファクト(手の破綻・変ポーズ)では、過学習と生成ガチャを切り分けられない。Codex も自分も seed42 の1枚から「過学習」と断じていたが、それは誤りだった。判定は同 epoch の複数 seed で一貫して崩れるかどうかで見る。
結局 ep150 と ep180 に確認できる品質差は無い(どちらも多 seed でクリーン、顔は早期プラトー)。ep150 を推す理由は「ep180 が壊れているから」ではなく「深く焼いても得が無い」から、それだけ。
サイドポニーの向き(Anima-Base でも向かって右で安定)
kanachan の最大の難所はサイドポニーの向き(WAI では ep150 を要して 100% になった)。Anima-Base ep150 と WAI ep150 を同一プロンプト・同 seed で並べた。

どちらも 3 seed すべてで向かって右(学習方向)に出る。Anima-Base は向き制御を WAI ep150 と同等にこなした。サイドポニーとアホ毛がベース得意(Anima が既定で大きく描く)なので向きもそのまま乗る。keichan のインテーク(ベース苦手)が天井だったのと対照的。
ep150 をポーズ・アングルで検証
「マトリクス1枚で ep150 最良」だけでは構図耐性が分からないので、ep150 で全身・横・3/4・後ろ・座り・走り・あおり・ふかんを振った(制服、seed42/100)。

各構図で破綻なく kanachan が出て、サイドポニー+アホ毛もポーズを通して保たれる(ベース得意の堅牢さ)。注目は全身正面で、kanachan は脚がほぼ直立=keichan の脚曲げポーズと対照的で、直立ターンアラウンド主体のデータがそのまま自然な立ち姿に出ている。3/4 が膝立ちになるのと、あおりが弱いのは keichan と同じ(前者は cowboy shot+three quarters プロンプトの癖、後者はトリガーによるあおり抑制でキャラ非依存)。
顔の収束を学習元と比較
keichan で見た「顔は学習元そのものではなく Anima 画風に寄る」が kanachan でも起きるかを、学習元(Gemini 生成のバスト)と出力 ep100/150 で並べた。表情がバラつくと顔の比較にならないので、学習元・出力とも笑顔(smile)に揃えてある。

Codex(gpt-5.5) 評価では、忠実度は約 3/5 で ep100 付近で頭打ち。茶髪・茶目・アホ毛・右サイドポニー・前髪密度は再現できるが、顔は学習元の丸く素朴な造形より縦長・V字寄りで、目が Anima 的に整いすぎる。さらにサイドポニーが学習元より長く大きくなり(ベース得意の特徴を Anima の既定が誇張)、青シュシュが黄色寄りに色ズレした。
keichan の「後髪の二段トーン」と同じく、小さなアクセサリの色はトリガーやタグで保持しきれずベース寄りにズレる。結局 keichan と同じく「見分けはつくが顔は Anima 画風に収束、小物の色はズレる」で、Gemini 素材 × Anima-Base の顔の振る舞いは2キャラで一致した。
2キャラで確定したこと
| keichan | kanachan | |
|---|---|---|
| 見分けの決め手 | インテーク(ベース苦手) | サイドポニー+アホ毛(ベース得意) |
| トリガー単体 | 出る(インテークは弱い) | 出る(特徴も強い) |
| 最良 epoch | ep120〜150(ep80 でプラトー、ep180 は得なし) | ep150 |
| ep180 | ほぼプラトー | 崩れず(s42 は単発の生成事故) |
決定的なのは、kanachan の最良 ep150 が WAI でも Anima-Base でも同じだったこと。最適点のエポックは「データと特徴」で決まり、ベース(WAI か Anima-Base か)では変わらない。keichan が早くプラトーしたのは深い epoch で伸びる特徴を持たないから、kanachan が ep150 を要したのはサイドポニーの向きが深い epoch で改善するから。つまり「keichan の収束が速いのはベースの差か特徴の差か」の答えは特徴の差で、同じ Anima-Base 上でも keichan は早く、kanachan は ep150 だった。
データ設計の指針(v3案 / Anima系キャラLoRA一般則)
ここまでの全知見を整理すると、キャラ LoRA のデータ設計則が出る。
- 直立ターンアラウンド(前後左右斜め)を少数。
standingをここにだけクリーンに貼る。良いデフォルト(棒立ち)+等身+多方向の同一性。kanachan が制御しやすかった核。 - バストアップ+衣装バラし。顔・前髪・ベース苦手な特徴(インテーク)の焼き付けで、同一性の本体になる。インテークはフレーミングで大きく写るバストで強く焼く(細部サイズは見かけサイズに比例)。衣装をバラして1着固定を防ぐ。
- キャプション衛生。一般タグ(
standing等)に意図しないポーズ・属性が紐づかないよう、同じタグを貼る画像の中身を揃える。核心(色・インテーク)はタグから抜いてトリガー吸収、独立構造(リボン・ブレイド)はタグで残す。 - 「ベースが出せないものだけ入れる」。ベース得意(ブレイド・リボン・ポニー・ふかん・一般ポーズ)は少数か不要(盛るとデフォルト汚染で損、ベースが勝手に出す)。ベース苦手(インテークは素材で誇張して入れる・それでも天井あり、あおりは欲しいなら必須で、入れないとトリガーが抑制)は入れる。
- 素材の出自。分布ズレ高一貫ソース(Gemini)> 自家中毒(Anima 自家生成)。顔忠実度で v2>v1 を実証。
要するに、同一性はバストで濃く焼く+トリガー吸収。構図はベースが出せない分だけ入れる。クリーンな直立ターンアラウンドで既定と等身を整える。一般タグを汚さない。素材は高一貫の分布ズレソース。
v2 の反省点を具体化すると、全身44枚のポーズ付き立ち絵 → 直立ターンアラウンド数枚に置き換えて全体を軽くするのが次の最適解(kanachan の構成に寄せる)。