Anima-Base v1.0をM1 Maxで動かしてWAI-Animaと比較、既存LoRA互換性とTurbo LoRA 5.7倍高速化を検証
 目次
目次
CircleStone LabsがAnimaシリーズの正式版 Anima-Base v1.0 をHuggingFaceに上げた。
split_files/diffusion_models/anima-base-v1.0.safetensors、サイズは4.18GBで preview3-base と同じ、アーキテクチャ(Cosmos-Predict2-2B + Qwen3 0.6B TE + Qwen Image VAE)も変わっていない。
今回の更新で preview の名前が外れたが、READMEには 「Anima-Base は真のbase model、aesthetic tuningされていない」 ことが明記されていて、quality tagsやartist tagsを使わないと地味な絵が出やすい設計は preview 時代と地続き。
姉妹バージョンとして Anima-Turbo が「Coming soon」として告知され、すでに Turbo LoRA がCivitAIに上がっている。
M1 Max 64GBのComfyUIで preview3-base / WAI-Anima v1 / Anima-Base v1.0 の3モデルを並べた結論を先出し。
- 生成時間は275〜285秒でほぼ同じ。アーキテクチャと推論コストは preview3-base から変わっていない
- 素の出力(プロンプト固定)はキャラ造形がほぼ同じで、衣装の細部と背景の描写に差が出る程度
- WAI-Anima向け既存 kanachan LoRA を v1.0 で読むと軽い指定では3シードとも崩壊する(青肌nude / ストレート化 / 茶色崩壊)。WAI-Anima / preview3-base はポニー方向は外しつつもキャラ造形は残るのに対し、v1.0 はキャラ自体を失う
- 物理特徴明示の spec / format-T 相当の重い拘束では v1.0 でも kanachan の主要要素は出るが、ポニー方向は seed 支配でモデル横断で揃わず、preview3 では腕が描けない seed もある
- Turbo LoRA を strength 1.0で被せると5.7倍高速化(275s → 48s)。Turbo 1.0 × kana 0.75 が軽い指定での実マトリックス上のスイートスポット(K=1.0 まで上げるとサイドポニーが消える)
- T=1.0 × K=0.75 を9シードで測ったヒット率は 22%(seed 42, 200 の2枚で kanachan の主要要素が揃う、残りはストレート化・狐耳化・兵装+血のシミ等で崩壊)
- 重い指定(衣装パーツや色を明示)+ Turbo + kana 1.0 を9シードで測ると 6/9 ≈ 67% で kanachan として認識可能。プロンプトを盛れば閾値を越える
- 差は WAI-Anima の aesthetic tuning と WAI 系追加学習データ が LoRA を「拾いやすい状態」に整えていたぶん。生の v1.0 base に戻ると同じ LoRA でも起動条件が厳しくなる。本格運用には v1.0 ベースでの LoRA 再学習が必要、というのが結論
モデル構成と立ち位置
| 項目 | Anima-Base v1.0 | Anima preview3-base | WAI-Anima v1 |
|---|---|---|---|
| 公開 | 2026-05 | 2026-04 | 2026-04 |
| サイズ | 4.18GB | 4.18GB | 4.18GB |
| 性格 | CircleStone Labs公式の真のbase model | 直前preview | preview3-base派生のWAI調整版 |
| aesthetic tuning | なし | なし | あり |
| アーキテクチャ | Cosmos-Predict2-2B + Qwen3 0.6B TE + Qwen Image VAE | 同左 | 同左 |
| 学習データ | アニメ数百万枚 + 非アニメアート800k枚 | 同左 | preview3-base + WAI追加調整 |
| アニメ知識カットオフ | 2025年9月 | 同左 | preview3-base継承 |
| ライセンス | CircleStone Labs Non-Commercial(Cosmos-Predict2派生) | 同左 | 同左(派生扱い) |
READMEの「base = aesthetic tuningされていない」点が本記事の検証範囲に直結する。WAI-Anima は派手寄りに調整した派生で、aesthetic tuningが乗っているぶん本記事のLoRA基準軸になる。
LLMアダプタについて
Anima系がSDXLと違うのは LLMアダプタ という中間層が挟まる点。
READMEでは「LLMアダプタはテキスト埋め込みを拡散モデルに渡す前に処理する層で、生成画像への影響が大きい。アダプタ自体が驚くほど多くの知識を持っていて、学習で簡単に劣化する」と明記されている。
このため LoRA 学習でも llm_adapter_lr=0 でアダプタは固定したまま DiT 側だけ学習するのが公式推奨。手元の WAI-Anima 向け kanachan LoRA もこの設定で学習してある。preview3-base から v1.0 にベースが切り替わっても、アダプタが共通なら LoRA の互換性は維持されやすい、という構造的根拠がここにある。
ただし「構造的に読める」ことと「うまく当たる」ことは別で、本記事はそこを実機で確かめる話。
Animaのプロンプト規約(SDXLとの差)
WAI-Anima を動かしているときは「SDXL系と似たような感覚」で書けてしまうが、Anima公式READMEを読み直すと SDXLとは違うルール がいくつかある。
タグの順序が固定
[quality/meta/year/safety tags] [1girl/1boy/1other等] [character] [series] [artist] [general tags]各セクション内ではタグの並びは任意。前記事 12,000ステップ検証 の 形式T プロンプトはこの順序を守った構成になっている。
artist は @ プレフィックス必須
You must put @ in front of the artist. The effect will be very weak if you don’t.
@nnn yryr のように @ を付けないとアーティスト学習が反映されない。
プロンプト重みづけがSDXLより強い
(chibi:2) のように、SDXLで一般的な (chibi:1.3) より高い重みを推奨。
データセットタグ(非アニメ画像)
LAION-POPとDeviantArt画像はそれぞれ ye-pop / deviantart のデータセットタグを最初の行に置き、2行目に元画像のalt-textや作品タイトルを書く、という構文で学習されている。アニメ以外を出すときの特殊構文。
タグドロップアウト前提
学習時にランダムなタグドロップアウトが入っているので、関連タグを全部並べる必要はない。SDXLでよくやる「タグを全部列挙して安定させる」アプローチとは違う。
Quality tags の二系統
- Human score:
masterpiece, best quality, good quality, normal quality, low quality, worst quality - PonyV7 aesthetic:
score_9, score_8, ..., score_1
どちらか片方、両方、どちらも使わない、のいずれもOK。
入手とセットアップ
curl -L -o ~/ComfyUI/models/diffusion_models/anima-base-v1.0.safetensors \
"https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/diffusion_models/anima-base-v1.0.safetensors"テキストエンコーダ(qwen_3_06b_base.safetensors)とVAE(qwen_image_vae.safetensors)は preview 時代から共通。
公式README推奨値(preview3-baseと共通)。
| 項目 | 値 |
|---|---|
| 解像度 | 512²〜1536² |
| ステップ | 30〜50 |
| CFG | 4〜5 |
| サンプラー(中立) | er_sde |
| サンプラー(柔らかめ・CFG高めOK) | euler_a |
| サンプラー(多様性) | dpmpp_2m_sde_gpu |
| スケジューラ | simple または beta57 (RES4LYF、絵画調) |
| LoRA学習 | rank 32、学習率 2e-5、llm_adapter_lr=0 |
anima_comparison.json ワークフロー
リポジトリのルートに anima_comparison.json という ComfyUI ワークフローも置かれている。
グリッド出力で「列=モデル、行=seed」を組んで複数モデルを並列比較する作りで、デフォルトでは Anima / NetaYume / Newbie-Image を比較する。対応アーキテクチャは Anima / SDXL / Lumina / Chroma / Newbie-Image。
v1.0 と preview3-base の素の出力比較
ComfyUIで生成条件を揃えて2モデルを並べた。
| 項目 | 値 |
|---|---|
| 解像度 | 832×1216 |
| ステップ | 30 |
| CFG | 4.0 |
| サンプラー | er_sde |
| スケジューラ | simple |
| seed | 42(固定) |
| ネガティブ | worst quality, low quality, score_1, score_2, score_3, blurry, jpeg artifacts |
テスト1(棒立ち、白背景)
プロンプト: 1girl, solo, long blonde hair, blue eyes, white robe, gold embroidery, capelet, gold sash, long sleeves, long dress, standing, looking at viewer, full body, white background


衣装系は違うが大枠は似ている。preview3-baseのほうが多少造形が細かく見える程度で、preview段階でこの出力ならどっちでも好み。
テスト2(動的シーン、背景あり)
プロンプト: 1girl, solo, long blonde hair, blue eyes, white robe, gold embroidery, capelet, gold sash, long sleeves, long dress, running, wind, hair blowing, dynamic pose, fantasy landscape, castle in background, sunset sky, dramatic clouds, grass field


キャラ造形はほぼ同じで、差は背景に出る。城の描写は preview3-base のほうが好み、草原は v1.0 のほうがやや細かい。甲乙つけがたい。
生成速度(M1 Max 64GB)
| モデル | 棒立ち | 動的 |
|---|---|---|
| preview3-base | 285s | 277s |
| Anima-Base v1.0 | 275s | 275s |
ほぼ同じ。アーキテクチャと解像度・ステップが揃っているので差は出ない。
既存kanachan LoRAを3モデルで読んだときの互換性
ここが本記事の本題。
WAI-Anima は preview3-base のファインチューンなので、その上で学習した kanachan-waianima-rework-v4_epoch180.safetensors(rank 32、llm_adapter_lr=0、12,000ステップ検証で出した sweet spotエポック)を、waiANIMA_v10 / preview3-base / Anima-Base v1.0 の3モデルにそのまま当てて挙動を見る。
前記事で論じたとおり、Animaアーキテクチャは CLIP-less設計 + Qwen3 0.6B TE のcatastrophic forgetting で、LoRA単体での造形固定が苦手という構造的制約を持つ。
今回の比較は「ベースが変わるとLoRAが完全に動くか」ではなく「ベース固有のドリフトをLoRAがどれだけ抑え込めるか」を見る話になる。
注意: 以下に出てくる青肌・灰色肌の崩壊出力は、completely nude 等の指定なしでも全裸ふうの肌色塊として出てきたもの。人型をしているが、人間判定として境界にある(青/灰色の肌、性的描写の意図はない)。それでもプラットフォーム側のフィルタに引っかかる可能性があるため、本文中の崩壊画像は軽めのぼかしを入れている(記事末尾の NSFW 検証画像より弱い)。
軽い指定(ベース挙動を可視化)
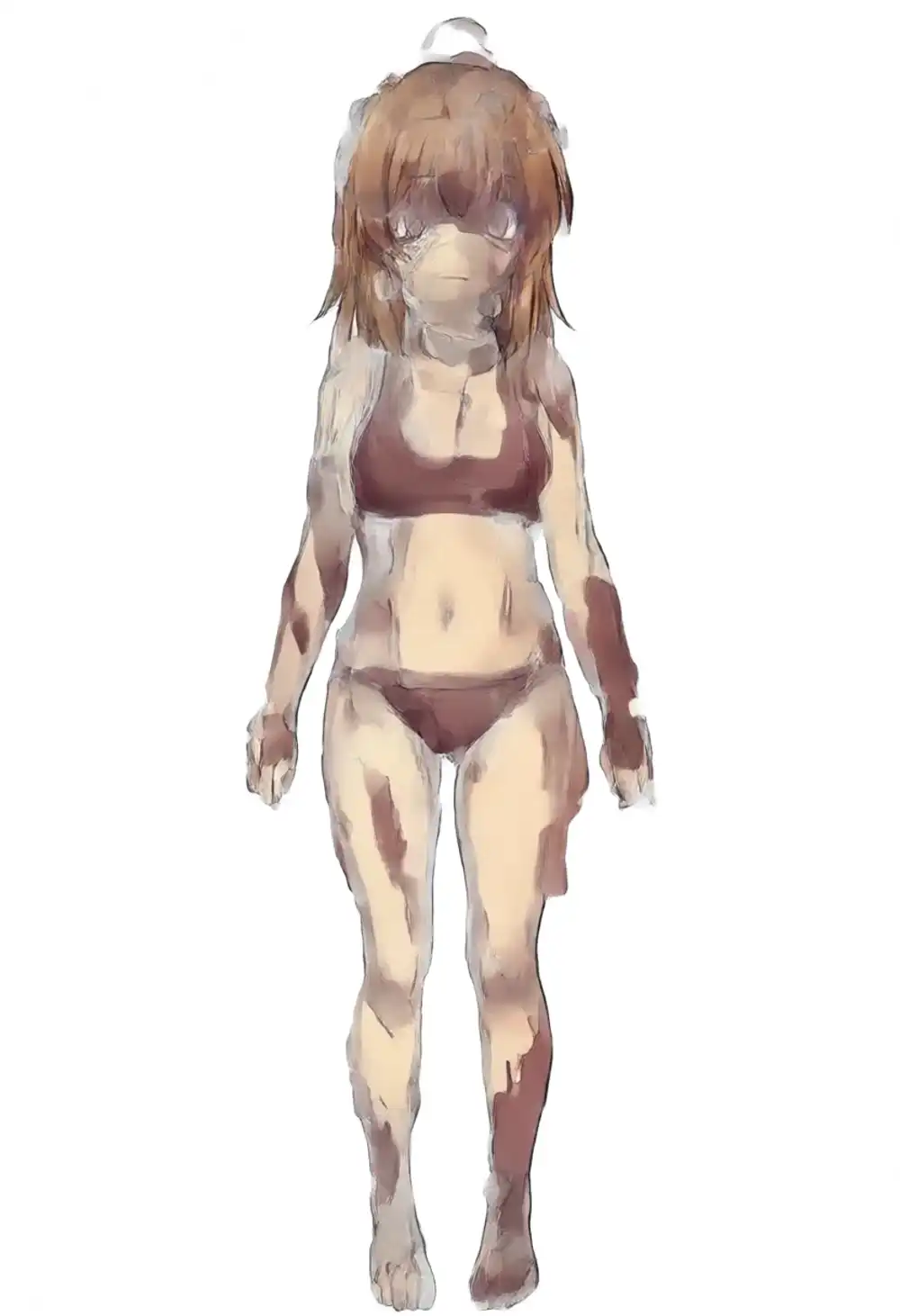
プロンプト: kanachan, 1girl, solo, standing, looking at viewer, full body, white background
LoRA strength: 1.0



3モデルとも「kanachan キーワードだけでは学習素材通りの造形は完全には引き出せない」が、ドリフトの大きさは違う。
WAI-Anima は茶髪 + ahoge + サイドポニー(ただし位置は学習素材の右側と逆、viewer 左)+ 黄色scrunchie で kanachan の雰囲気は出る。preview3-base も茶髪 + ahoge + サイドポニー(同じく viewer 左で逆)が出るが衣装はTシャツ+紺ショートパンツ+白ハイソックスに変化。v1.0 は seed 42 で完全に別物で、青い肌・青い髪・サイドポニー消失の崩壊出力(上記の警告通り軽くぼかしている)。
この段階で見えてくるのは、WAI-Anima と preview3-base は方向を外しつつもキャラ造形は残しているのに対し、v1.0 ではキャラ自体が出てこない、という違い。
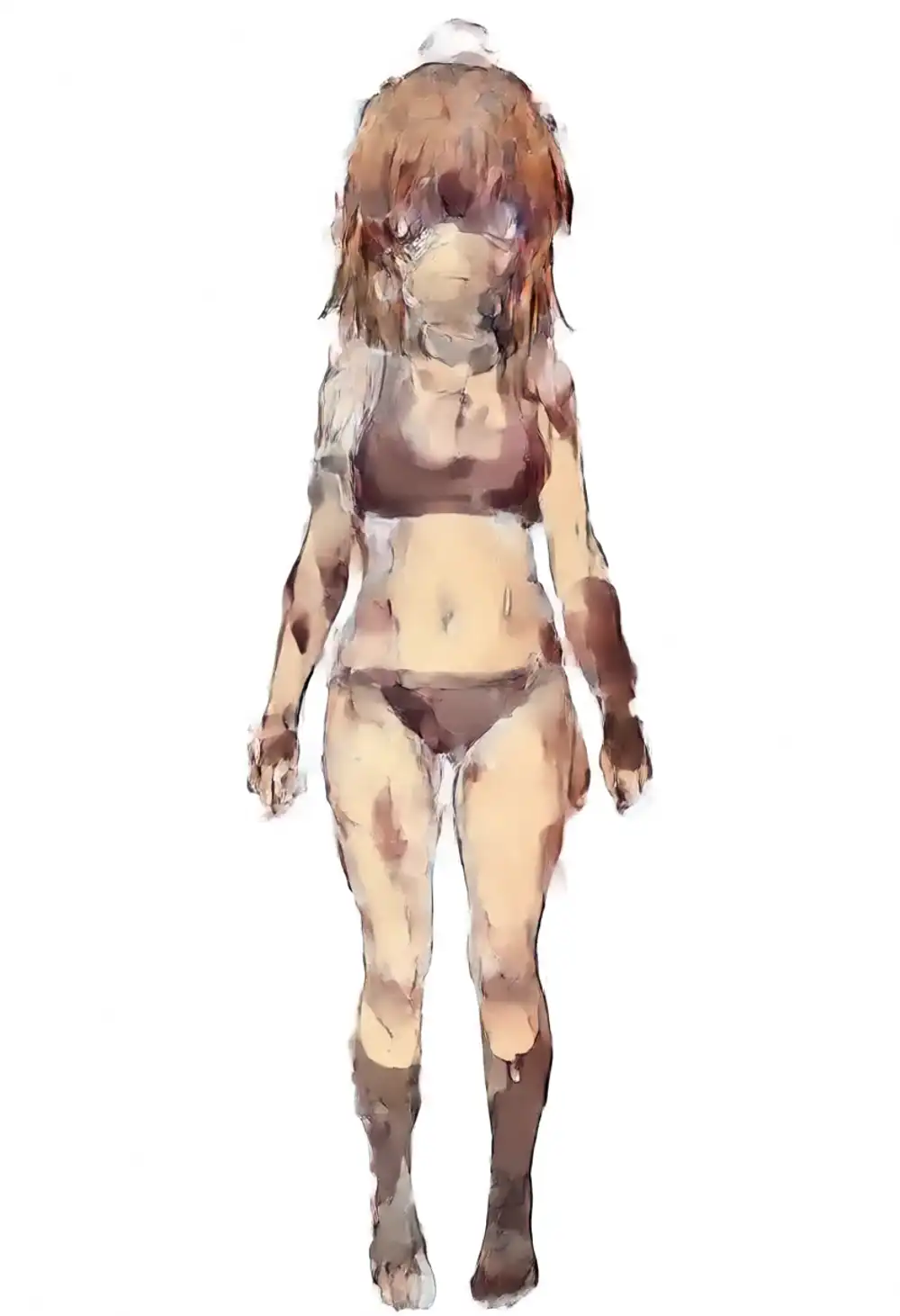
v1.0 + kanachan の seed特性(軽い指定では3シードとも崩壊)
軽い指定で v1.0 が崩壊するのが seed 依存か恒常的か、別 seed で検証した。


3シードとも崩壊している。
- seed 42: 青肌の全裸出力(ぼかし)
- seed 100: ahoge は残るがサイドポニーは消えてストレートヘア、kanachan の特徴の一つが落ちている
- seed 200: 見るに耐えないレベルの灰色 / 茶色の崩壊
つまり v1.0 + WAI-Anima向けLoRA は軽い指定では恒常的に崩壊する 側で、WAI-Anima / preview3-base のように「方向は外すが造形は残る」状態にすら持ち込めない。これが v1.0 固有のリスク。
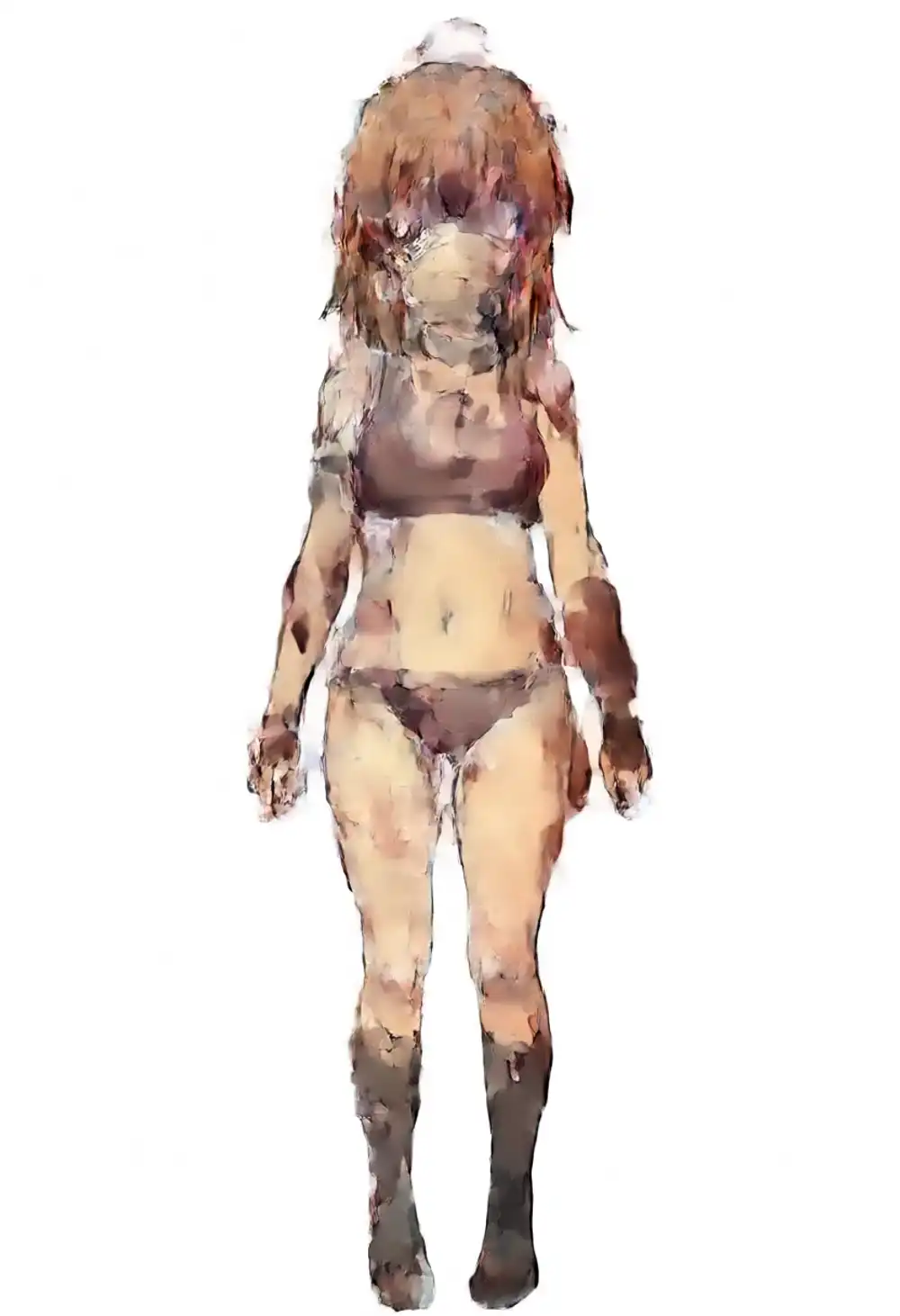
強度sweep on v1.0(軽い指定)
v1.0でLoRA強度を変えて、軽い指定で持ち直すか確認。



強度を上下させても軽い指定では非単調に崩壊する。
0.5 ではベースが完全勝利して別キャラ(黒髪+獣耳+軍装)になり、0.75 で kanachan に寄った造形が出てくる(小さなサイドポニー風の結び+ahoge+茶目、ただし髪色は学習素材より暗め)。1.0 はそのまま seed 42 の青肌出力に崩壊し、1.25 では灰色の汚れた肌で水着レオタード風のアーティファクト。
強度sweepで救える幅は 0.75 で出る「マシな崩れ方」のところだけ で、ヒット率を確保したいならプロンプトを盛る方向で対処する形になる。
物理特徴を明示した中拘束プロンプト(spec)
軽い指定で v1.0 が崩壊するなら、髪型・髪色を明示すれば持ち直すかをまず確認。
プロンプト: kanachan, 1girl, solo, brown hair, side ponytail, yellow scrunchie, brown eyes, standing, looking at viewer, full body, white background



3モデルとも茶髪 + サイドポニー + ahoge + 体育服系で、軽い指定での崩壊からは持ち直している。
ポニー位置で比較すると、学習素材通り(viewer 右側)に出るのは v1.0 のみで、WAI-Anima と preview3-base は viewer 左側に流れている。物理特徴を明示すれば v1.0 側でも LoRA は拾えるようになる。
重い拘束プロンプト(前記事の 形式T)3モデル × 3シード
ここは「縛れば出るのか」の本筋テスト。前記事で使っていた format-T をそのまま流した。
masterpiece, best quality, score_7, safe, 1girl, solo, kanachan,
side ponytail, ahoge, double parted bangs, medium hair, blue scrunchie,
white collared shirt, red necktie, looking at viewer, front view,
white background, simple background, full body, standingv1.0 × seed 42 / 100 / 200



preview3-base × seed 42 / 100 / 200



WAI-Anima v1 × seed 42 / 100 / 200



9枚とも茶髪 + ahoge + 青scrunchie + 制服のスケルトンは出るが、完全に学習素材通りに揃ったわけではない。
| 軸 | 観察 |
|---|---|
| ポニーの方向 | seed 支配。seed 42 / 100 は3モデルとも viewer 左側、seed 200 だけが viewer 右側(学習通り)。モデルではなく seed が方向を決めている |
| 髪色 | 9枚で明るめ茶色〜暗め茶色まで揃わず微妙にばらつく |
| 解剖学 | preview3-base × seed 100 / 200 は両腕が背中側に消えていて、ポーズというより腕が描けていない |
| 表情 | seed ごとに変わる |
重く縛れば kanachan の主要要素は出るが、「3モデル × 3シードで安定」というわけではない。前記事 12,000ステップ検証 で WAI-Anima 上ですら方向ヒット率49%だったセオリーが、v1.0 で改善も悪化もせず、ベース変えても同じ非単調曲線の上に乗っている。
方向制御テスト(side ponytail on the left/right side)
サイドポニーの位置を明示プロンプトで強制した場合の挙動。プロンプトは kanachan, 1girl, solo, side ponytail on the (left|right) side, standing, ...、3モデル × LEFT/RIGHT 指定。
LEFT 指定



RIGHT 指定



前記事で WAI-Anima 上の方向ヒット率を約49%(ガチャ)と計測済み。今回 v1.0 でも方向プロンプトを明示しても安定しないのは想定の範囲内で、v1.0 だから悪化したという話ではない。
Turbo LoRA 実適用
Anima公式から告知されている Anima-Turbo は未公開だが、先行で Turbo LoRA v0.1 がCivitAIに上がっている。
CivitAI記載の推奨値。
| 項目 | 値 |
|---|---|
| ステップ | 8〜12 |
| CFG | 1 |
| LoRA strength | 1.0(多様性が欲しいときは下げる) |
| 適用先 | Anima-Base以外のAnimaチェックポイントでも動く |
単体での適用
v1.0 + Turbo 1.0、8steps、CFG 1。


通常 275s かかっていたところが 46〜48s に短縮、約 5.7倍 の高速化。
画質はCivitAI記載の通り、細部のクオリティはやや落ちるが大枠は崩れない。M1 Max でイテレーションを回したいときの実用的な選択肢。
Turbo + 既存kanachan LoRA を併用(高速LoRAが v1.0 ベースバイアスを抑制する仮説)
Turbo を被せた状態で kanachan キーワード入りプロンプトを通すと、軽い指定の kana 単体で seed 42 が完全破綻していた v1.0 でも、4シード中2シードで kanachan のサイドポニーが出る。
仮説: 高速LoRA(少ないステップ・低CFG)だと、各denoising stepでのキャラLoRAの相対影響が大きくなり、30step CFG 4 で起動する v1.0 のベース傾向が画像確定前にキャラLoRAの誘導に押し負ける、という機序が考えられる。
ガチャの数値検証は後段の強度マトリックス + 9シード測定で行う。
Turbo × kanachan 強度マトリックス on v1.0
Turbo と kanachan の強度を組み合わせて、軽い指定でのスイートスポットを探した。プロンプトは軽い指定固定、seed 42 固定。
| K=0.5 | K=0.75 | K=1.0 | K=1.25 | |
|---|---|---|---|---|
| T=0.5 | 画像1 | 画像2 | 画像3 | 画像4 |
| T=0.75 | 画像5 | 画像6 | 画像7 | 画像8 |
| T=1.0 | 画像9 | 画像10 | 画像11 | 画像12 |
T=0.5 行


T=0.75 行



T=1.0 行



マトリックスから見える挙動(seed 42 単発の所見)。
| Turbo \ kana | 0.5 | 0.75 | 1.0 | 1.25 |
|---|---|---|---|---|
| 0.5 | ベース勝ち、別キャラ | ベース勝ち | 灰色全裸崩壊 | 油絵アーティファクト |
| 0.75 | ベース勝ち、別キャラ | ベース寄り | ストレート、ポニーなし | アーティファクト |
| 1.0 | kana薄、ベース寄り | kanachan要素揃う | ahogeは残るがポニーなし | 油絵アーティファクト |
軽い指定下で kanachan の主要要素(茶髪・サイドポニー・scrunchie・ahoge)が揃う唯一の組み合わせが T=1.0 × K=0.75。 K=1.0 まで上げるとサイドポニーが消えて灰色セーターになり、K=1.25 で油絵アーティファクト、T を下げると kana の影響が画像に乗らなくなる。
T=1.0 × K=0.75 を 9シード(42 / 7 / 100 / 200 / 300 / 400 / 500 / 600 / 700)でガチャ率を測った。









サイドポニー+scrunchie+ahoge+制服系で kanachan として認識できるのは seed 42 と seed 200 の2枚。ヒット率 2/9 ≈ 22%。残り7枚はストレートヘア化(4枚)、狐耳化(2枚、内1枚は血のシミ付き)、兵装+血のシミ(1枚)と多様に崩れる。
学習素材通りの体育服は0枚(プロンプトに衣装指定がないため、制服系に流れる)。出る絵の品質としては kanachan として識別はできるが、制服にホルスターやベルトポーチが乗る etc の細部はベース側のバイアスが残る。
前記事 12,000ステップ検証 で計測した WAI-Anima 上での方向制御ヒット率 ≈ 49% から半分以下まで落ちる。Anima-Base v1.0 ベースだと軽い指定では既存LoRAの当たり率は2割、というのが本マトリックスの結論。
重い指定で Turbo + kana を併用するとどうなるか(9シード再現性)
プロンプトに衣装パーツや色を明示した重い指定 + Turbo 1.0 + kana 1.0 を、軽い指定と同じ9シード(42 / 7 / 100 / 200 / 300 / 400 / 500 / 600 / 700)で測定した。
プロンプト: kanachan, 1girl, solo, long blonde hair, blue eyes, side ponytail, scrunchie, hood, white robe, gold embroidery, standing, looking at viewer, full body, white background、8steps CFG 1。









6/9 ≈ 67%。茶髪 + サイドポニー(学習素材通りの viewer 右側)+ ahoge + cleric/僧侶風衣装が出るのは6シード(42, 7, 200, 300, 400, 700)。残り3シード(100, 500, 600)はフードで隠れる・サイドポニーが立たない・髪が流れるだけ等で kanachan としての認識ラインを越えない。
それでも軽い指定の K=0.75 で 2/9 = 22% だったヒット率が、hood, white robe, gold embroidery 等のプロンプトを盛るだけで 6/9 ≈ 67% まで跳ね上がる。「v1.0 ベースの raw さは、プロンプトを盛ることである程度補える」という閾値が見えた。
代償は衣装の固定で、学習素材の体育服にはならない(プロンプト指定通りの cleric衣装に流れる)。多様な衣装でかつ高ヒット率を狙うなら結局 v1.0 ベース再学習しかない。
NSFW出力テスト(おまけ)
ここから先はテスト出力した画像がセンシティブな可能性があるため、画像自体をぼやかしています。出力のちゃんとした結果が見たい場合には、手元の環境でお試しください。
3モデル × nsfw タグ on/off で、v1.0 が preview3-base や WAI-Anima と同等にNSFWを出せるかを確認した。プロンプトは前回 WAI-Anima記事 と同じ構造。
nsfw タグなし
プロンプト: kanachan, 1girl, solo, long blonde hair, blue eyes, completely nude, naked, bare skin, standing, looking at viewer, full body, white background



3モデルとも nsfw タグ無しでも completely nude, naked の直接指示で全裸出力。前回記事の preview3-base 時代の「nsfw タグなしだと隠す方向に寄る」傾向は再現せず、今回の3モデルとも素直に裸を出してきた。プロンプトの強度差で挙動が変わる例として扱う。
nsfw タグあり
プロンプト: kanachan, 1girl, solo, long blonde hair, blue eyes, completely nude, naked, bare skin, nsfw, straight-on, full body, standing, white background



nsfw タグありでも off と大きな差は出ず、3モデルとも全裸出力。v1.0 でセーフティフィルタが追加された挙動は今回の3モデル比較では出ていない。
残課題と続編
ここまでで見えたこと。
- v1.0 の素の出力は preview3-base から大きく変わっていない(衣装と背景に細かな差)
- WAI-Anima向け既存LoRAを v1.0 に当てると、軽い指定では3シードとも崩壊する。WAI-Anima / preview3-base ではポニー方向は外しつつもキャラ造形は残っていた領域で、v1.0 はキャラそのものを失う
- spec / format-T 相当の重い拘束をかければ kanachan の主要要素は出るが、ポニーの方向は seed 支配で安定せず、preview3-base × seed 100/200 では腕が描けないなど解剖学的崩れも出る
- 強度 sweep は非単調曲線で、軽い指定の救済として一番マシなのは strength 0.75(小さなサイドポニー風+ahoge)だが学習素材通りには届かない
- Turbo LoRA は5.7倍の高速化に有効。Turbo 1.0 × kana 0.75 がマトリックス上のスイートスポットで、9シードで2枚(seed 42, 200)が kanachan の主要要素揃いまで到達。ヒット率約22%
- 重い指定(衣装パーツや色を明示)+ Turbo + kana 1.0 を9シードで測ると 6/9 ≈ 67% で kanachan として認識可能。閾値はプロンプト側にある
- NSFW 出力可否は preview3-base 時代から変わらない
WAI-Anima では kanachan キーワードだけでもキャラ造形が残ったのに、v1.0 では崩れる。WAI-Anima の aesthetic tuning と WAI 系の追加学習データがLoRA の起動を助けていたぶん、生のベースに戻すと同じ LoRA でも条件が厳しくなる、という見立て。
推論側のチューニングだけでこの差を埋めるのは難しい(軽い指定は K=0.75 帯でも 22%、重い指定なら seed支配の方向ガチャ)ので、続編は v1.0 ベースで kanachan LoRA を再学習して、軽い指定でもキャラが起動するか、方向制御の非単調曲線がクリアになるか を見る。前回の WAI-Anima 学習と同じく RunPod で rank 32 / lr 2e-5 / 12,000ステップ前後を回す。M1 Max でローカル学習環境を整えていないので、これだけはローカルでは答えが出ない。
実用面では当面、以下のいずれかで運用するのが現実的。
- WAI-Anima v1(preview3-baseベースの aesthetic tuning モデル)を引き続き使う
- v1.0 を使う場合は spec相当(最低でも髪型・髪色を明示)以上の拘束プロンプトで叩く
- 速度が必要なら v1.0 + Turbo LoRA を併用、ただしキャラLoRAの安定性は別途プロンプトで担保