Character LoRA on Anima-Base vs WAI-Anima: face fidelity up, intakes capped
 Contents
Contents

The previous keichan LoRA v1 was baked on WAI-Anima v1.0 using 91 images WAI-Anima generated itself. The result: “self-poisoning (training data and base share the same distribution), so it plateaued at ep20, and face consistency inherited Anima’s native weakness and wobbled.”
That v1 article explicitly left two questions for next time.
- Does the face tighten up when you train on off-distribution material? (v1 converged fast via self-poisoning, but the face wobbled. What about an external-distribution source?)
- (Per the conclusion of the Anima-Base v1.0 comparison article) if you want to run on Anima-Base itself, you have to retrain the LoRA on it. So what actually happens if you bake directly on Anima-Base?
v2 answers both at once. Only two things change.
- Base: WAI-Anima → Anima-Base v1.0 (CircleStone Labs upstream, no aesthetic tuning)
- Material: 91 Anima self-generated → 70 from Qwen Image Edit AIO (outside the Anima family = off-distribution)
The motivation is simple: everything up through the article applying the LoRA to 6 derivatives used WAI-Anima as the base, so “enough with WAI all the time.”
v2 came out better than v1. Trigger-only, keichan reproduces as a usable LoRA, and face fidelity to the target beat v1. What’s left: the intake ceiling, and pose/angle being bound to the training distribution.
What the built-in samples showed during training
run1 (keichan v2, Anima-Base, ep180 = 12,600 steps) ran on a RunPod RTX 4090. 0.34 it/s (on par with v1’s RTX 6000 Ada), ~11GB VRAM. With save_every:1 every epoch is saved and auto-synced locally.
Face comparison: training target / baseline (step0 = bare Anima-Base, no LoRA) / ep10 / ep50 / ep88.
| Stage | State |
|---|---|
| Training target (green frame) | The goal. Deep blonde, blue eyes, thick intakes, blue ribbon |
| Baseline (step0) | Brown hair, brown eyes. keichan is untrained, so bare Anima-Base shows (it only picks up the bangs and blue ribbon from the prompt). No aesthetic tuning, so the coloring is plain too |
| ep10 | Blonde + blue eyes locked (blue eyes fix around ep6). The face is still “a polished blonde, blue-eyed stranger.” Bangs are swept, not fully blunt |
| ep50 | Almost the same as ep10. Color is done; the face/hairstyle structure barely moves |
| ep88 | Still plateaued. Blonde-with-blue-eyes is stable, but keichan’s signature blunt bangs and thick forward intakes stay weak in the built-in samples. The face stays in the “generic blonde-blue-eyes” zone |
v1 (Anima self-generated material) landed blonde + blue eyes by ep1, but v2 (Gemini-sourced, off-distribution material) locked the color by ep6 yet the face stayed roughly flat from ep10–88. Once the color is set, the “face/hairstyle structure convergence” is hard to push under the built-in samples’ single condition (N format, fixed seed42).
That said, v1 taught me that the built-in sampler can’t show full capability because it’s a single condition, so this “plateau” wasn’t final. In fact, the impression flips under the local K/N/KT × multi-seed matrix below. Looking only at the built-in samples it seemed like on Anima-Base the color lands but the face won’t tighten to keichan-specific, but that was the built-in samples underselling it — the final answer to “does the face tighten on Gemini material” is Yes (below).
Objective scoring by Codex (gpt-5.5)
Since the differences are subtle to eyeball, I threw the built-in samples at round epochs (ep20/40/60/80/90) into Codex CLI (gpt-5.5) alongside the target and had it score each attribute 0–5 (same trick as the v1 article’s swimsuit framing check).
| epoch | hair (blonde) | eyes (blue) | blunt bangs | air intake | face/identity |
|---|---|---|---|---|---|
| 20 | 4 | 5 | 4 | 2 | 3 |
| 40 | 4 | 5 | 4 | 3 | 3 |
| 60 | 4 | 5 | 4 | 3 | 4 |
| 80 | 4 | 5 | 4 | 3 | 4 |
| 90 | 4 | 5 | 4 | 3 | 4 |
Codex’s take is convergence plateaus. From ep20 on, hair color, eye color, and bangs are stable, but the air intake (forward scoop) caps at 3/5, and face/identity caps at 4/5. Best is ep80 (ep60–90 are about level). “Are hair color and face fully converged on the target?” is No (hair is close, but face and intake shape are unfinished).
The eyeball impression (color landed but face/intake won’t tighten to keichan-specific) was quantitatively backed by external evaluation. Anima-Base × Gemini material got the verdict “color lands, but face/intake detailing has a ceiling.” But that’s the built-in-sample baseline; the final call under full inference is revised upward below. The reason even hair color isn’t a perfect 4/5 is the two-tone gradient at the back hair/tips mentioned earlier. The intake stopping at 3/5 matches v1’s conclusion that “if the material doesn’t exaggerate the intake enough, you can’t push it back”.
For the record, after run1 finished I chained run2 (rebaking kanachan on Anima-Base) on the same Pod automatically (a parallel experiment; details below).
Why Anima-Base v1.0
In the Anima-Base v1.0 comparison article, I confirmed that an existing LoRA baked for WAI-Anima collapses on Anima-Base v1.0 under light prompting (22% hit rate, blue skin / straightening / brown collapse). The conclusion there was “serious use requires retraining the LoRA on the v1.0 base.” So if you want to use Anima-Base, bake on Anima-Base is the logical path.
Technically it’s almost just a swap.
| Component | WAI-Anima v1 | Anima-Base v1.0 |
|---|---|---|
| Character | WAI-tuned derivative of preview3-base (aesthetic tuning yes) | CircleStone Labs’ true upstream base (aesthetic tuning no) |
| DiT | Cosmos-Predict2-2B | same |
| TE | Qwen3 0.6B | same (shared across all derivatives) |
| VAE | Qwen Image VAE | same (shared across all derivatives) |
| LLM adapter | shared, frozen during training (llm_adapter_lr=0) | same |
The architecture is identical, and TE/VAE/adapter are shared. So the only training-side change is one line, transformer_path. The official LoRA training recommendation (rank32 / lr2e-5 / frozen adapter) also matches v1’s setup exactly.
The one difference is whether aesthetic tuning is present. Anima-Base is designed to output plain images bare (it assumes quality tags / artist tags). That shows up in operation as
- the built-in samples look plainer during training than the WAI era (but that’s not abnormal)
- at inference, you assume quality tags like
masterpiece, best quality, and@artist(the@is required) when needed
The training captions already have a masterpiece, best quality, safe prefix, so that side is fine.
Training material (70 images, Gemini-rooted mixed pipeline = fully off-distribution)
The material isn’t single-model output; it was built with a mixed pipeline rooted in Gemini. Not a single Anima-family image was used.
| Class | Count | Files | Origin pipeline |
|---|---|---|---|
| Bust-up (neutral face, source) | — | — | Gemini generated |
| Bust-up (expression variants) | 26 | 0001–0026 | the neutral face above, expression-swapped via Photoshop generative fill (Gemini Nanobanana Pro) |
| Full body (source) | — | — | Gemini generated |
| Full body (final, various poses/outfits) | 44 | 01–50 (with gaps) | the above, output through Qwen Image Edit AIO |
v1’s material was WAI-Anima’s own generated images (= same distribution as the base = self-poisoning), whereas v2 is Gemini-rooted, no Anima = a completely different distribution from the base’s point of view. That’s the intended “off-distribution material.”
What matters here: the earlier kanachan also used Gemini-generated material, and in that case the optimum was ep150. v2 has the same Gemini root, so the prediction is it lands not on v1 (Anima self-generated, ep20 plateau) but on a kanachan-like deep convergence (the ep100–150 band). The mixed pipeline (Gemini + Photoshop generative fill + Qwen Image Edit) means the distribution isn’t single, which may also affect the convergence curve.
One caveat: the 26 bust-ups are ~495px at native size, smaller than the 1024 training resolution, so the bucket scales them up. The most critical face/intake detail concentrates there, so if reproduction is weak there’s room to rebake at higher resolution in v3.
Captions follow the v1 design (untouched)
I reuse the v1 caption design (trigger keichan absorption + 2 natural-language sentences + independent structure tags + quality prefix) as-is. Composition is aligned between full body and bust-up (expressions), and this time I don’t touch the captions at all. Keeping hair intakes out of the tag list and only mentioning it in natural language is also the same as v1.
v1 → v2 config diff
- transformer_path: "models/transformers/waiANIMA_v10.safetensors"
+ transformer_path: "models/transformers/anima-base-v1.0.safetensors" # ★ upstream base
- data_dir: "/workspace/datasets/keichan" # 91 imgs (Anima self-generated)
+ data_dir: "/workspace/datasets/keichan-v2" # 70 imgs (Qwen Image Edit AIO material)
- output_name: "keichan-waianima-v1"
+ output_name: "keichan-animabase-v2"
rank 32 / alpha 32 / lr 2.0e-5 / repeats 4 / bf16 / xformers:false
save_every:1 / sample_every:1 / seed:42 # ← all left as-isTE/VAE paths, frozen adapter, and sample prompts (same N format, seed 42 as v1) are unchanged. Everything except base, data, and output name is exactly the same as v1, to narrow the difference down to “base and material.”
Epoch plan
- v1 (self-poisoning, no off-distribution) plateaued at ep20.
- v2 has off-distribution material (Qwen Image Edit AIO) + a bare Anima-Base (less “helpful” than WAI). Both push toward slower convergence, so ep20 likely isn’t enough.
- The comparison point is kanachan v4. Gemini-generated (off-distribution) material had ep150 as the optimum. v2 may land in that band.
- But since two variables change at once, the optimum is unknown → run the full ep180, save every epoch with
save_every:1, and sweep locally.
RunPod setup
Tooling is the same AnimaLoraToolkit as v1. There was no volume left from last time, so I built it from scratch.
GPU choice (6000 Ada out of stock → 4090 is plenty)
The RTX 6000 Ada kept going out of stock and flickering in and out, so I switched to an RTX 4090 (24GB).
- v1’s measured VRAM use was 10.89GB. Less than half of the 4090’s 24GB, plenty of headroom. The 6000 Ada’s 48GB was overkill.
- The 4090 is Ada generation = the same cu124 stack as the 6000 Ada, so setup is unchanged.
- Results are GPU-independent (total steps, seed, bf16 fixed). Even if the GPU changes, the baked LoRA is the same; only it/s (time/cost) changes.
- Avoid Blackwell (RTX 5090 / RTX PRO 6000 / B200). sm_120 doesn’t run on cu124 and you fall into cu128 setup hell.
Upgrade the template from torch 2.4 → 2.5.1+cu124
The RunPod template only offered torch 2.4 / 2.8, so I picked 2.4 (cu124). What I ultimately want is the torch 2.5.1+cu124 × transformers >=4.51,<5.0 combo confirmed in v1.
The reasons (confirmed by burning it twice in v1).
- Qwen3 TE needs
transformers >= 4.51(4.45 givesmodel type qwen3 not recognized) - a bare
pip install transformerspulls 5.x, which requirestorch.distributed.tensor.device_mesh→ torch 2.5+ required - → the winner is torch 2.5.1+cu124 × transformers
>=4.51,<5.0
I avoid the 2.8 template (cu128) because toolkit + transformers 5.x becomes an unverified stack with a risk of hitting breaking changes.
# Don't use requirements.txt (xformers replaces torch with cu130 and kills Ada)
pip install --upgrade torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 \
--index-url https://download.pytorch.org/whl/cu124
pip install --upgrade "transformers>=4.51,<5.0" \
einops safetensors diffusers accelerate peft lycoris-lora omegaconf \
tqdm Pillow numpy lpips pytorch-fid pytorch-msssim scipy scikit-image \
matplotlib pandas pyyaml psutil rich tiktoken sentencepiece protobufDownload models on the Pod directly (orders of magnitude faster than home upload)
# curl Anima-Base v1.0 (4.18GB) / VAE (243MB) straight from HF (no token needed)
curl -sL -o models/transformers/anima-base-v1.0.safetensors \
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/diffusion_models/anima-base-v1.0.safetensors
curl -sL -o models/vae/qwen_image_vae.safetensors \
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/vae/qwen_image_vae.safetensors
# Merge Qwen3-0.6B-Base into models/text_encoders/ for the TE (configs ship with the toolkit)
hf download Qwen/Qwen3-0.6B-Base tokenizer.json vocab.json model.safetensors \
--local-dir models/text_encodersSmoke test → production
Pass a TE-load smoke test before the Transformer’s 7-minute load (to avoid the “wait 7 minutes → die on the TE” trap from v1).
python -c "
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, T5Tokenizer
from transformers.models.auto.configuration_auto import CONFIG_MAPPING
print('torch:', torch.__version__, '| cuda:', torch.cuda.is_available())
print('qwen3:', 'qwen3' in CONFIG_MAPPING)
AutoModelForCausalLM.from_pretrained('models/text_encoders', torch_dtype=torch.bfloat16, device_map='cpu')
print('>>> SMOKE TEST PASSED <<<')
"
# Once it passes, launch in tmux
tmux new-session -d -s train "python anima_train.py --config ./config/train_keichan_v2.yaml 2>&1 | tee /workspace/output/keichan-v2/train.log"Known-landmine reference
| Trap | Fix |
|---|---|
requirements.txt’s xformers replaces torch with cu130 → instant Ada death | manual deps. xformers: false |
| transformers 5.x requires device_mesh / 4.45 doesn’t support Qwen3 | pin to >=4.51,<5.0 |
| dies on the TE after the Transformer’s 7-minute load | smoke test before launch |
| scp from home is painfully slow | download models on the pod (240Mbps), scp only the dataset (88MB) |
huggingface-cli download is deprecated | hf download <repo> <files> --local-dir |
| Anima-Base is plain bare | inference assumes quality/artist (@) tags |
Results check (K / N / KT matrix)
Same 3 formats × seed 42/100/200 sweep as v1. The check base is Anima-Base v1.0 (matched to the training base), with the Turbo LoRA at 8 steps.
| Format | Content |
|---|---|
| K (trigger only) | keichan + composition tags |
| N (with natural language) | add the training caption’s natural language |
KT (hair intakes tag assist) | add a guide line at inference |
Success criteria (6 points from trigger keichan alone): blonde / blunt bangs (not hime cut) / long intakes / half braid / blue ribbon / blue eyes.
After the run finished and every epoch was in hand locally, I generated ep20/50/80/120/180 × K/N/KT × seed42/100/200 = 45 images with Anima-Base v1.0 + Turbo LoRA 8 steps (er_sde/simple, CFG 1.0, 832×1216). Below is the seed42 grid (rows = format, columns = epoch, shown is the clothed version with a uniform specified).

I lined this up with the target design and had Codex (gpt-5.5) evaluate it.
- K (trigger only) stably reproduces the main design. Blonde, blue eyes, blunt bangs, braid, and blue ribbon all come from the trigger alone at every epoch. So it’s already usable on Anima-Base. The outfit varies with trigger only (nude to random casual), but specifying it stabilizes the uniform (the grid shown is the clothed, uniform-specified version). Meanwhile the intake’s thickness/orientation isn’t fully fixed (it thins or drifts toward the side hair depending on epoch/composition).
- N (with natural language) is best. Face stability is higher than K, the intake is tidier and closer to the target face, with fewer breakdowns.
- KT (tag assist) helps with outfit/structure specification, but face/intake is worse than N. ep120 KT is shaky on texture, which hurts character evaluation.
- Epoch is roughly capped from ep80–180. Codex’s matrix scoring nudged ep180 ahead by a hair, but I couldn’t see the difference by eye, and a re-test showed ep120–150 is effectively enough (below).
- Overall verdict: “a usable character LoRA.” The main design comes from the trigger alone, so it’s in usable territory. If you want the intake’s thickness/orientation strictly fixed, assume prompt assistance.
Recommended use is ep120–150 + N format (the reason for not recommending ep180 is the re-test below). Add hair intakes etc. only when you want to emphasize the intake (route KT to outfit specification).
What stands out: the “characterless plateau” seen under the built-in sampler (N format, single seed, 25 steps) turns into stable keichan from the trigger alone under full Turbo 8-step inference. The built-in samples only show capability at a discount (re-confirming v1’s “the built-in sampler is a single condition, so it’s thin evidence”). “Color lands, face is practical enough, only the intake is capped” is keichan v2’s conclusion.
Pose/angle & back-ribbon check (uniform, ep180)
A good frontal portrait alone doesn’t tell you whether side, back, and full body come out stably. If the training data is composition-biased, those break, so at ep180 I swept full body, profile, 3/4, back, sitting, running, low angle, and high angle (uniform specified, Anima-Base + Turbo).

The character build (uniform, blonde, ribbon) comes out robustly at any angle. But precise angle control is a separate matter: weak specifications get pulled back to Anima’s “3/4-front attractor” (side → 3/4 side, back → 3/4 back, low angle → front, 3/4 → for some reason becomes kneeling). The “Anima’s strongest attractor is 3/4” recorded in the derivatives article reproduced on a new character + Anima-Base too.
Shooting again with strong weights (Anima recommends higher weights) separates them.

| Angle | Result with strong specification |
|---|---|
| Standing 3/4 | standing fixes the kneeling, but it’s more front-leaning than 3/4, with bent legs — a “cute stance” (not a clean upright 3/4) △ |
| Direct back | (from behind:1.6) gives a true back angle (back ribbon visible). But the legs bend into a walking posture |
| Direct profile | moves away from front but doesn’t fully become a pure profile △ |
| High angle | (from above:1.7) gives a closer crop + downward angle + a looking-up face (upper body, so no leg issue) ✅ |
| Low angle | even at weight 1.7 it stays fully front, no change ❌ |
And when you shoot full body, almost everything except the high angle (upper body) becomes a bent-leg “posed” stance that won’t stand straight. You think “do legs really bend this much?”, but the bare model doesn’t bend, so this is specific to this LoRA. The cause: all 44 full-body training images were Qwen Image Edit “character standee” poses (walking, weight shift, 3/4 stance), with not a single rigid stand (upright, feet together). The LoRA learned “keichan’s full body = posed legs,” so even saying standing it comes out with posed legs (Anima’s moe standing-pose preference piles on top). The output’s pose distribution copies the training pose distribution directly. Another case of “what isn’t in the training/base won’t come out.”
So compositions present in the training data/base can be controlled with explicit + strong specification (especially standing is required; without it, it turns into kneeling etc.). Compositions that aren’t there won’t surface no matter how you hammer the weights. It’s not “any angle is free” but precisely “in-distribution angles are controllable with strong specs; out-of-distribution is impossible.”
What’s interesting is the asymmetry: high angle comes out but low angle never does. This is likely a reflection of the composition distribution of anime art. “High angle = a cute girl looking up at you” is a moe-art staple the base holds tons of, but “low angle = looking up” is scarce in the moe genre (it leans action), and neither the base nor the LoRA material holds it. So high angle surfaces with strong specs, low angle won’t surface no matter what. Even within “out-of-distribution is impossible,” it splits further by whether the base has the prior knowledge.
Is the back ribbon tie visible? (keichan’s core)
keichan is a half-braid updo, and the blue ribbon tied at the back is the giveaway. This can only be confirmed from a back angle. I checked with a rear-head close-up and a look-back.

The blue ribbon bow + half-up braid at the back of the head come out correctly (no failure of hair dangling weirdly from the knot). The reason the back structure appeared even though the training data has barely any back views: the braid and ribbon tie are designs Anima can draw by default (the LoRA just calls them up tied to the character). This is the flip side of why the intake is capped — the same principle.
Builds the base holds by default (braid, ribbon, side ponytail) bake with little data. Builds it doesn’t hold (air intake) cap out even with lots of data. The required training amount and the ceiling are set by whether the base has the prior knowledge.
Detail size scales with “apparent size within the composition” (framing principle)
But in a back composition the blue ribbon shrinks. At the same seed and same LoRA, changing only the composition makes the ribbon size scale exactly with the apparent size of the back of the head.
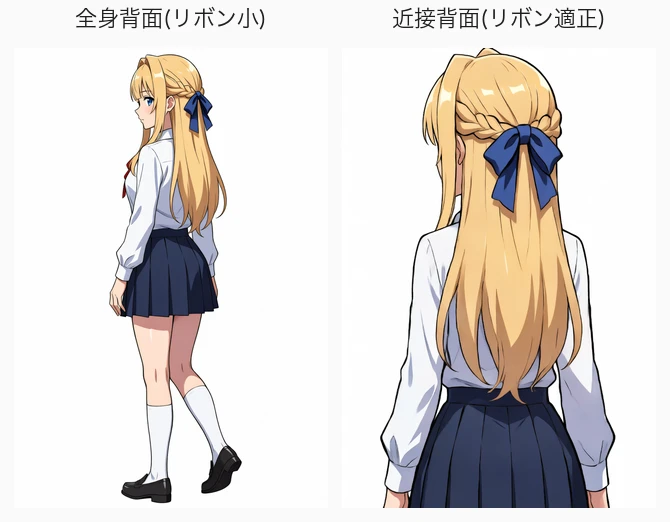
Same framing principle as v1’s “intake strength scales with the apparent size of the face” — keichan’s features (intake, ribbon) all ride this law. The operational rule: shoot the distinguishing feature in a composition where it appears large.
Hammering with size tags ((blue ribbon:1.6), large bow) actually got a response on Anima-Base + LoRA, surprisingly, and the ribbon got bigger. Accessory size control is a weakness shared across all models, and how it fails splits by architecture (QIE = no effect / Gemini = overdoes it / bare Anima·IL = arbitrary), but in this case the LoRA had learned the ribbon, so it responded moderately (framing’s contribution mixes in too, so the reliable lever is still composition).
The trigger embodies the training distribution for pose/angle
Pushing the pose/angle behavior converged on one principle. The trigger word embodies the training material’s pose/angle distribution directly, and suppresses what’s outside it.
(1) standing is irrelevant; the trigger carries the pose. With or without standing the stance doesn’t change (same posed legs at the same seed). keichan is resident in all 44 posed full-body images, so it soaks up the pose signal most strongly = the real culprit for the posed stance is the trigger keichan itself. standing is a thin receptacle; with or without it, the trigger’s posed stance dominates.
(2) Posed or upright is decided by the data distribution (base-independent). I lined up keichan v2 / kanachan v2 / kanachan v1 on the same neutral prompt (full body, standing, front view, no forcing).

keichan v2 (Anima-Base, motion data) bends the legs into a posed stance, kanachan v2 (Anima-Base, upright turnaround data) stands straight, and kanachan v1 (WAI, same data) is straight too. On the same Anima-Base, keichan is posed and kanachan is upright. This is a data effect (not a base difference). Because kanachan’s full body was an “upright turnaround (front/back/left/right/diagonal)” with standing cleanly attached, both the trigger and standing learned “upright.”
(3) The base can do low angle, but the trigger suppresses it. I separated out the issue of (from below) not producing a low angle by shooting with no trigger (base only).

Base alone (no trigger) → low angle comes out normally (with skirt or pants. Not the NSFW avoidance I first suspected either; it draws normally even at an upward angle with a skirt). But adding the keichan trigger suppresses the low angle. The base can do low angle, yet the trigger overwrites it with the training distribution (no low angle) and erases it. Lowering the LoRA strength to 0.3 brings the low angle back at the cost of identity collapse (low angle and keichan-ness are tightly coupled). kanachan behaves identically (no low angle → suppressed, returns at 0.3).
Meanwhile high angle comes out even with the trigger on. The base’s high-angle prior is strong enough to break through the suppression; the low angle has a weak prior and loses. Whether suppression can be overridden is decided by “how strongly the base holds that composition” (high angle = a moe-art staple, strong base; low angle = scarce in the moe genre, weak base).
(4) The general rule of token contamination. standing became posed because the images with standing attached had poses (3/4, raised arms, etc.), and standing co-occurred with them. The tag→feature binding isn’t exclusive but a co-occurrence statistic (distributed across multiple tokens), so even if you route three-quarter etc. separately, standing still catches some leakage. So unless you align the content of images sharing a tag, a general tag gets contaminated by unintended attributes.
The re-test retracts the ep180 recommendation (ep120–150 is enough)
Codex put keichan’s overall best at ep180 in the matrix, but I couldn’t see the ep120–180 difference by eye. So I relined ep100/120/150/180 on a neutral prompt (no forcing).
The result: a bent-leg posed stance at every epoch, with no difference in pose strength between ep100/120 and ep180 (the legs already bend firmly at ep100). So the posed stance doesn’t strengthen with epoch; it’s constant from ep100. It’s data-driven — the posed full-body data bakes in early — and doesn’t increase or decrease the deeper you bake. The notion that “pose strengthens with overtraining the deeper you go” was wrong.
That also removes the basis for recommending ep180. The face plateaus at ep80 and the posed stance is constant from ep100, so ep180 has no gain over ep120–150 (neither face nor stance changes).
So I lower keichan’s recommendation from ep180 to ep120–150. The reason isn’t that ep180 is broken but that deeper baking adds nothing. It also lines up with kanachan being best at ep150 on the same Gemini material (the ep180 overtraining I initially suspected was refuted by the multi-seed check below).
Did the face tighten on off-distribution material? → Yes (v2 wins on target fidelity)
I lined up v1 (training material = Anima self-generated) and v2 (= Gemini-rooted) at the same seed (v1 on the training base WAI-Anima, v2 on Anima-Base). At first I compared with calm, closed-mouth faces, but judging “face fidelity” on a mouthless face is improper, so I re-evaluated with a smiling version that shows the mouth (smile, open mouth).

I had Codex (gpt-5.5) evaluate it.
- Face fidelity to the target is higher for v2. v2 leans toward the target’s narrow eyes, face proportions, and center bangs. v1 has big round childish eyes — stable but converged on “a different anime face.”
- The mouth is closer on v2 too. The target is “a modest smile showing teeth” and v2’s mouth shape matches, while v1’s mouth opens wide into a different kind of smile.
- Consistency goes to v1 (stable across seeds), but that stable face is off-target.
- Intake is stronger on v1, weak-to-mid on v2. v2’s generation quality is rougher, being bare Anima-Base.
- Verdict (Codex): even with the mouth condition, v2 is the faithful one to the target (including the mouth actually strengthens its edge).
So “a high-consistency off-distribution source (Gemini) pulls the face toward the target” is supported. v1’s self-poisoning material set into “stable but a different face from the target,” whereas v2 tightened toward the target. The trade-off is v2’s weaker intake and rougher bare quality (from the plain Anima-Base). The mid conclusion in the first half, where I sourly judged “the face won’t tighten” from the built-in samples, is revised upward toward v2 if you look at “target fidelity” rather than face “quality.”
Rebaking kanachan on Anima-Base (parallel experiment)
I baked the same “Gemini material × Anima-Base” on another character, kanachan (brown hair, side ponytail, ahoge). Two goals: separate whether keichan’s early plateau is “a base difference” or “a feature difference,” and confirm whether kanachan’s biggest hurdle — the side-ponytail orientation — comes out on Anima-Base.
T/N/TN matrix (stable from trigger alone, best ep150)
ep30/60/100/150/180 × T/N/TN (seed42, uniform specified).

In Codex’s (gpt-5.5) evaluation, T (trigger only) gives brown hair, ahoge, side ponytail, and blue scrunchie at every epoch with a stable character, and the best is ep150. At ep180, the seed42 TN had hands, a rod-like small object, and a liquid-ish mouth rendering creep in on their own, and I initially judged this overtraining (but it’s overturned by the multi-seed check below).

I initially saw this as post-plateau late-stage degradation (= overtraining) and judged running kanachan to ep180 excessive. Default is ep150. But this “ep180 overtraining” call depended on a single seed42 image, and the next multi-seed check overturns it.
”ep180 overtraining” was a single-seed misjudgment (multi-seed check)
Bothered that I’d ruled “ep180 is overtraining” from one seed42 image, I reshot ep180 and ep150 TN at seed 100/200/300. The result: ep180 doesn’t break down at seeds other than 42 (100/200/300). Only s42 was a worst-case roll — a weird pose pulling the tie toward the mouth plus broken hands — and the same “hands to chest/mouth” tendency shows up in ep150 TN too. keichan’s ep150 was also fully clean across 3 seeds in a hand-free composition (ep120 likewise).
So s42’s breakdown isn’t consistent overtraining degradation but a one-off generation fluke from low-step Turbo (broken hands, and the weird pose stacked tags induce). Even at the same epoch, changing the seed gives mostly clean output. If it were overtraining it should break consistently across multiple seeds at the same epoch, and that doesn’t happen.
This is also a methodological lesson. A single-seed artifact (broken hands, weird pose) can’t separate overtraining from a generation lottery. Both Codex and I ruled “overtraining” from one seed42 image, and that was wrong. The verdict has to be read from whether it breaks consistently across multiple seeds at the same epoch.
In the end there’s no confirmable quality difference between ep150 and ep180 (both clean across multiple seeds, face plateaus early). The reason to recommend ep150 isn’t “because ep180 is broken” but “because deeper baking adds nothing” — that’s all.
Side-ponytail orientation (stable to the viewer’s right even on Anima-Base)
kanachan’s biggest hurdle is the side-ponytail orientation (on WAI it took ep150 to hit 100%). I lined up Anima-Base ep150 and WAI ep150 on the same prompt and seed.

Both come out to the viewer’s right (the learned direction) at all 3 seeds. Anima-Base handled orientation control as well as WAI ep150. Side ponytail and ahoge are base-strong (Anima draws them big by default), so the orientation rides cleanly too. A contrast with keichan’s intake (base-weak) being capped.
Checking ep150 across poses/angles
Just declaring “ep150 best from one matrix” doesn’t show composition robustness, so at ep150 I swept full body, side, 3/4, back, sitting, running, low angle, and high angle (uniform, seed42/100).

kanachan comes out without breakdown in each composition, and the side ponytail + ahoge are kept through the poses (the robustness of base-strong). The notable one is the full-body front: kanachan’s legs are nearly upright — a contrast with keichan’s bent-leg posed stance — and the upright-turnaround-dominant data shows up directly as a natural standing posture. The 3/4 becoming kneeling and the weak low angle are the same as keichan (the former is a quirk of the cowboy shot+three quarters prompt; the latter is the trigger’s low-angle suppression, character-independent).
Comparing face convergence with the training source
To see whether keichan’s “the face leans toward Anima’s style rather than the training source itself” also happens with kanachan, I lined up the training source (Gemini-generated busts) and outputs at ep100/150. Since varying expressions make a face comparison meaningless, both the training source and the outputs are normalized to a smile (smile).

In Codex’s (gpt-5.5) evaluation, fidelity is about 3/5 and caps around ep100. Brown hair, brown eyes, ahoge, right side ponytail, and bang density reproduce, but the face is more vertical/V-shaped than the training source’s round, plain build, and the eyes are too neatly Anima-like. Furthermore the side ponytail got longer and bigger than the training source (Anima’s default exaggerating the base-strong feature), and the blue scrunchie color-drifted toward yellow.
Same as keichan’s “two-tone back hair,” small accessory colors can’t be held by the trigger or tags and drift toward the base. In the end, same as keichan, “it’s recognizable but the face converges on Anima’s style, and small-object colors drift” — the face behavior of Gemini material × Anima-Base matched across both characters.
What’s settled across the two characters
| keichan | kanachan | |
|---|---|---|
| Giveaway | intake (base-weak) | side ponytail + ahoge (base-strong) |
| Trigger only | comes out (intake weak) | comes out (feature strong too) |
| Best epoch | ep120–150 (plateaus by ep80, ep180 no gain) | ep150 |
| ep180 | roughly plateaued | doesn’t break (s42 was a one-off fluke) |
The decisive point: kanachan’s best ep150 was the same on both WAI and Anima-Base. The sweet-spot epoch is set by “data/feature,” and the base (WAI or Anima-Base) doesn’t change it. keichan plateaued early because it has no feature that grows at deep epochs; kanachan needed ep150 because the side-ponytail orientation improves at deep epochs. So the answer to “is keichan’s fast convergence a base difference or a feature difference” is a feature difference — on the same Anima-Base, keichan was early and kanachan was ep150.
Data-design guidelines (v3 proposal / general rules for Anima-family character LoRAs)
Organizing all the findings so far yields data-design rules for character LoRAs.
- A few upright turnarounds (front/back/left/right/diagonal). Attach
standingcleanly only here. Good defaults (rigid stand) + proportions + multi-direction identity. The core that made kanachan easy to control. - Bust-ups + outfit variety. Baking in the face, bangs, and base-weak features (intake) becomes the body of identity. Bake the intake strongly on busts where framing makes it appear large (detail size scales with apparent size). Vary outfits to prevent locking to one.
- Caption hygiene. So that general tags (
standingetc.) don’t get bound to unintended poses/attributes, align the content of images sharing a tag. Pull the core (color, intake) out of tags into trigger absorption, and keep independent structure (ribbon, braid) in tags. - “Only include what the base can’t produce.” Base-strong (braid, ribbon, ponytail, high angle, general poses) is few or unnecessary (piling it on loses to default contamination; the base produces it anyway). Base-weak (intake: exaggerate it in the material and include it — still a ceiling; low angle: required if you want it, since without it the trigger suppresses it) should be included.
- Material provenance. A high-consistency off-distribution source (Gemini) > self-poisoning (Anima self-generated). Demonstrated by v2 > v1 on face fidelity.
In short: bake identity densely on busts + trigger absorption. Include composition only to the extent the base can’t produce it. Set defaults and proportions with clean upright turnarounds. Don’t contaminate general tags. Use a high-consistency off-distribution source for material.
Concretely, v2’s reflection point is that replacing the 44 posed full-body standees with a few upright turnarounds to lighten the whole set is the next optimum (moving toward kanachan’s composition).
Reference links
- keichan LoRA v1 (WAI-Anima, self-poisoning, ep20 plateau)
- Comparing Anima-Base v1.0 with WAI-Anima and checking existing-LoRA compatibility
- Applying the same character LoRA to 6 Anima derivatives
- Extending kanachan to 12,000 steps (off-distribution material’s optimum is ep150)
- Classifying 20+ Anima derivative checkpoints