BERT+Qwen OCR校正パイプラインをPythonツールにした
 目次
目次
背景
前回の記事で、BERT perplexityスキャン → Qwen 7B LLM判定 → 不一致時エスカレーションという3段パイプラインを組んだ。VRAM 8GBのRTX 4060 Laptopで動く構成で、OCR誤認識131箇所のうち9件を自動処理、5件だけ人間に差し戻すところまでいけた。
ただし、あの実験はWSL2上のスクリプトの寄せ集めで、他の環境では動かない。BERTのモデルロードやollamaのAPI呼び出し、閾値の調整がバラバラのJupyter notebookに散らばっていて、再利用性がゼロだった。
クロスプラットフォームのPythonツールとしてパッケージングして、インストーラー1発で全部入って start.bat ダブルクリックでWebUIが立ち上がるようにした。
なぜollamaではなくllama-serverか
前回はollama経由でQwen 7Bを使っていたが、ツール化にあたってLLMバックエンドをllama-server(llama.cpp)に変更した。
ollamaはGUIが勝手に常駐する。このツールはパイプラインの出力をGradio UIに流すので、ollamaのチャットインターフェースは不要。バックグラウンドで起動して邪魔なだけ。
もっと大きいのはGPUオフロードの制御。llama-serverは --n-gpu-layers でCLIからVRAMに載せるレイヤー数を指定できる。VRAM 4GBのマシンなら20層だけ載せてメモリ効率と速度のバランスを取る、といった調整がコマンド一発でできる。ollamaとLM StudioはこのレベルのGPU制御に対応していない。
ツールの設計としては、LLM判定部分をOpenAI互換APIで抽象化した。llama-serverがデフォルトだが、WebUIのLLM API URL欄やCLIの --llm-api オプションでollama、LM Studio、リモートサーバーなど任意のバックエンドに切り替えられる。
パイプライン全体像
flowchart TD
A[入力テキスト] --> B[BERT perplexityスキャン]
B --> C{閾値判定}
C -->|確率1%未満| D[怪しいトークン抽出]
C -->|確率1%以上| E[AUTO-KEEP]
D --> F[フィルタリング]
F --> G{LLM有効?}
G -->|ON| H[LLM A/B判定]
G -->|OFF| I[BERT確率のみで分類]
H --> J{LLMとBERTの突合}
J -->|LLM: FIX| K[AUTO-FIX]
J -->|LLM: KEEP + BERT 50%以上| L[ESCALATE]
J -->|LLM: KEEP + BERT 50%未満| E
style K fill:#4caf50,color:#fff
style L fill:#ff9800,color:#fff
style E fill:#9e9e9e,color:#fffllama-serverが起動していなければ、パイプラインが自動でプロセスを立ち上げる。終了時に自動停止。手動管理は不要。
インストールから実行まで
GitHubのリリースページからSource code (zip)をダウンロードして展開するか、git clone で取得する。Gitは入れておくとインストールが速いが、なくても動く。
Windows
Pythonは事前にpython.orgから入れておくのを推奨(「Add python.exe to PATH」にチェック)。未インストールでもインストーラーがwinget経由で自動インストールを試みる。
展開したフォルダで install.ps1 を右クリック→「PowerShellで実行」、またはPowerShellから:
powershell -ExecutionPolicy Bypass -File install.ps1Mac/Linux
bash install.shインストーラーが自動でやること
- Python 3.10以上のチェック(Windowsで未インストールならwingetで自動インストール)
- venv作成 + GPU検出に応じたPyTorchインストール
- パッケージ本体 + BERT関連依存 + Gradio
- NDLOCR-Lite(Gitがあればclone、なければGitHubソースアーカイブを自動DL)
- llama-serverバイナリ(llama.cpp最新リリースから自動ダウンロード)
- Qwen3.5-4B Q4_K_M(約2.7GB、HuggingFaceから自動ダウンロード)
全部終わったら start.bat(Windows)か start.sh(Mac/Linux)をダブルクリック。ブラウザでWebUIが開く。llama-serverの起動もモデルのロードもパイプラインが自動でやる。
CLIから使う場合はvenvを有効化してから:
.venv/Scripts/activate # Windowsの場合
source .venv/bin/activate # Mac/Linuxの場合
python -m ocr_corrector scan.jpg # 画像入力(デフォルト)
python -m ocr_corrector --text input.txt # テキスト入力
python -m ocr_corrector --no-llm scan.jpg # BERTのみ(高速)テスト環境
| 項目 | スペック |
|---|---|
| GPU | NVIDIA GeForce RTX 3050 Ti Laptop(VRAM 4GB) |
| メインメモリ | 16GB |
| OS | Windows 11 |
| Python | 3.12.10 |
| PyTorch | 2.6.0+cu124 |
| BERT | cl-tohoku/bert-base-japanese-v3 |
| LLM | Qwen3.5-4B Q4_K_M / Qwen2.5-7B Q3_K_M(両方CPU推論) |
前回の実験環境(RTX 4060 Laptop 8GB + WSL2)よりVRAMが半分。BERTはGPU、LLMはCPU推論の bert-only 構成で自動選択された。
前回と同じOCRデータでテスト
前回記事で使った国会図書館1963年マニュアルのNDLOCR-Lite出力をそのまま投入した。
入力テキスト:
(z)気送子送付管
気送子送付には、上記気送管にて送付するものと、空
気の圧縮を使用せず,直接落下させる装置の二通りがあ
る。後者の送付雪は出納台左側に設置されており.5
3.1の各層ステーションに直接落下するよう3本の管
が通じ投入ロのフタに層表示が記されている。取扱いに
当っては気送子投入優すみやかにフタを閉め速度を調整目視で確認できる誤認識(前回記事と同じ):
- 「送付雪」→ 正しくは「送付管」
- 「投入優」→ 正しくは「投入後」
- 「投入ロ」→ 正しくは「投入口」(カタカナのロ → 漢字の口)
BERTスキャン結果
49箇所を検出、フィルタ後18箇所。処理時間は1.87秒(BERT on GPU)。
前回記事ではフィルタ前131箇所 → フィルタ後14箇所だったが、今回はフィルタ条件を少し緩めているためフィルタ後の件数が多い。
Qwen3.5-4Bの判定結果
thinkingモードの罠
最初に回したとき、全件KEEPになった。Qwen3.5系はデフォルトでthinking(推論トレース)が有効で、A/B判定のような短い回答でも内部で長い推論を走らせる。llama-serverのOpenAI互換APIでは、thinking部分が reasoning_content フィールドに入り、content(実際の回答)が空になる。
// thinking有効時のレスポンス
{
"message": {
"content": "", // 空 → KEEPと判定される
"reasoning_content": "Thinking Process:\n1. Analyze..." // ここに全部入る
}
}content が空なので「B」を含まない → 全件KEEPになる。前回記事でollama経由のQwen2.5-7Bが動いていたのは、Qwen2.5系にはthinkingモードがないため。
OpenAI互換APIの enable_thinking: false パラメータではthinkingは切れない。llama-serverでもollamaでも無視される。バックエンドごとに固有の方法が必要。
| バックエンド | thinkingの切り方 |
|---|---|
| llama-server | 起動時に --reasoning-budget 0 を渡す |
| ollama | ネイティブAPI (/api/chat) で "think": false を渡す。OpenAI互換API (/v1) では切れない |
Qwen3.5系のthinkingが切れなくて困っている話はネット上でも散見される。OpenAI互換APIだけ見て「enable_thinkingを送ったのに効かない」となるパターンが多い。各バックエンドのドキュメントを確認すること。
thinking無効化後の結果
18箇所の判定に82.6秒(CPU推論、1件あたり約4.6秒)。
| OCRテキスト | 正解 | BERT候補 | 3.5-4B判定 | 最終結果 |
|---|---|---|---|---|
| 投入優 | 後 | 後(73%) | FIX | AUTO-FIX。正解 |
| 投入ロ | 口 | 口(84%) | FIX | AUTO-FIX。正解 |
| 送付雪 | 管 | 真空(35%) | KEEP | AUTO-KEEP |
本物の誤認識2件をAUTO-FIXできた。前回のQwen2.5-7B Q4と同じ結果。
ただし行跨ぎfalse positiveの判定は、4Bでは7B Q4ほど正確ではない。
| 行跨ぎ箇所 | BERT候補 | 前回2.5-7B Q4 | 今回3.5-4B |
|---|---|---|---|
| 「管」→「。」 | 99% | KEEP | FIX |
| 「空」→「。」 | 93% | KEEP | KEEP |
| 「気」→「空気」 | 78% | KEEP | FIX |
| 「,」→「に」 | 80% | KEEP | FIX |
| 「あ」→「ある」 | 87% | KEEP | FIX |
4Bは本物の誤認識は拾えるが、行跨ぎのfalse positiveを正しくKEEPする能力では7Bに劣る。ただしESCALATEで人間に回る分も含めれば、パイプラインとして破綻はしていない。
Qwen3.5-9Bの判定結果
4Bの行跨ぎ精度が足りないので9Bも試した。unsloth/Qwen3.5-9B-GGUF の Q4_K_M(5.7GB)。
18箇所の判定に118.3秒(CPU推論、1件あたり6.6秒)。
| OCRテキスト | 正解 | BERT候補 | 9B判定 | 最終結果 |
|---|---|---|---|---|
| 投入優 | 後 | 後(73%) | FIX | AUTO-FIX。正解 |
| 投入ロ | 口 | 口(84%) | FIX | AUTO-FIX。正解 |
| 送付雪 | 管 | 真空(35%) | KEEP | AUTO-KEEP |
本物の誤認識は4Bと同じくFIXできる。行跨ぎFPの比較:
| 行跨ぎ箇所 | BERT候補 | 3.5-4B | 3.5-9B | 前回2.5-7B Q4 |
|---|---|---|---|---|
| 「管」→「。」 | 99% | FIX | KEEP | KEEP |
| 「空」→「。」 | 93% | KEEP | KEEP | KEEP |
| 「、」→「する」 | 84% | KEEP | KEEP | KEEP |
| 「気」→「空気」 | 78% | FIX | FIX | KEEP |
| 「,」→「に」 | 80% | FIX | FIX | KEEP |
| 「あ」→「ある」 | 87% | FIX | FIX | KEEP |
9Bは4Bから1箇所改善(「管→。」をKEEP)。ただし「気→空気」「,→に」「あ→ある」はパラメータ数を増やしても突破できていない。これらは行跨ぎで文脈が切れていることが問題の本質で、モデルを大きくしても限界がある。前回のQwen2.5-7B Q4が全KEEPできていたのは、2.5系と3.5系のモデル特性の差もありそう。
llama-server vs ollama、thinking ON/OFF、全文結合の比較
行跨ぎFPの判定がモデルの問題なのかバックエンドの問題なのか切り分けるため、Qwen3.5-4Bで条件を変えてテストした。ollamaはネイティブAPI(/api/chat)を使用。OpenAI互換API(/v1/chat/completions)はollamaでもthinking制御が効かず空レスポンスになる。
| 条件 | 誤認識FIX | 行跨ぎKEEP | 速度(18件) |
|---|---|---|---|
| llama-server thinking OFF (行単位) | 2/2 | 1/6 | 82.6s |
| ollama think=false (行単位) | 2/2 | 2/6 | 48.8s |
| ollama think=true (行単位) | 0/2 | 6/6 | 128.4s |
| ollama think=false (全文結合) | 2/2 | 1/6 | 49.5s |
| ollama think=true (全文結合) | 0/2 | 6/6 | 126.2s |
バックエンドの差
llama-serverとollamaで同じモデル・同じプロンプト・thinking OFFでも行跨ぎKEEPに差が出ている(1/6 vs 2/6)。ollamaの方が1件多くKEEPできた。量子化やサンプリングの実装差がA/B判定の境界ケースに影響していると思われる。速度もollamaの方が速い(48.8s vs 82.6s)。ollamaはGPUを自動で使う設定になっているため、CPUオンリーのllama-serverより有利。
thinking ONの挙動
thinking ONにすると全件KEEPになる。ollamaのネイティブAPIではthinkingフィールドに推論トレースが入り、content(回答本体)は空になる。thinkingの末尾を見ても「Constraint: Answer with…」のようなタスク分析の途中で切れており、AかBかの最終判断まで到達していない。num_predict: 64 ではthinkingのトークン予算が足りず、回答を生成する前に打ち切られている。
thinking ONで回答を取るには num_predict を大幅に増やす必要があるが、A/B判定に1文字返すだけのタスクで数百トークンの推論を走らせるのはコスト的に見合わない。
全文結合の効果
行単位のコンテキスト(前後2行)を全テキスト結合に変更しても改善しなかった。むしろ行跨ぎKEEPが2/6→1/6に悪化。コンテキストが長くなるとLLMの注意が分散して、A/Bの差分に集中できなくなる。行単位コンテキストの方が良い。
モデル選択
| モデル | サイズ | 誤認識FIX | 行跨ぎKEEP | 速度(CPU) |
|---|---|---|---|---|
| Qwen3.5-4B Q4 (llama-server) | 2.7GB | 2/2 | 1/6 | 4.6秒/件 |
| Qwen3.5-4B Q4 (ollama) | 2.7GB | 2/2 | 2/6 | 2.7秒/件 |
| Qwen3.5-9B Q4 (llama-server) | 5.7GB | 2/2 | 2/6 | 6.6秒/件 |
| Qwen2.5-7B Q4 (前回ollama) | 4.7GB | 2/2 | 6/6 | 約4秒/件 |
Qwen3.5系はthinking OFFの状態では行跨ぎFPの判定が弱い。前回のQwen2.5-7Bが6/6全KEEPできていたのは、2.5系がthinkingなしのストレートな応答に最適化されているため。3.5系はthinking前提の学習なので、切ると推論の質が落ちる。
VRAM 6GB以上のGPUなら、Qwen3.5-4B(2.7GB)をBERT(2.5GB)と同時にGPU上に載せて both-gpu 構成にできる。GPU推論ならLLM判定は1件1秒未満に高速化する見込み。
句読点再分割による行跨ぎ対策
行跨ぎfalse positiveの根本原因は、OCRテキストの物理的な改行位置で文が切れること。「空\n気」が2行に分かれていると、BERTは行末の「空」を文末と誤判定する。
対策として、入力テキストの改行を全て除去してから句読点(。、)で再分割する前処理を入れた。
# 元の行分割(OCR出力そのまま)
[0] 気送子送付には、上記気送管にて送付するものと、空 ← ここで切れる
[1] 気の圧縮を使用せず,直接落下させる装置の二通りがあ ← 「空気」が2行に
# 句読点で再分割
[0] (z)気送子送付管気送子送付には、
[1] 上記気送管にて送付するものと、
[2] 空気の圧縮を使用せず,直接落下させる装置の二通りがある。 ← 「空気」が1文に結果
| 指標 | 行分割(従来) | 句読点再分割 |
|---|---|---|
| BERT raw検出 | 49件 | 35件 |
| フィルタ後 | 18件 | 13件 |
| 「優→後」検出 | 73% | 82%(改善) |
| 「ロ→口」検出 | 84% | 60% |
| 行跨ぎFP(「空→。」等) | 6件 | 0件 |
行跨ぎ由来のfalse positiveが全滅した。BERTに投入する候補が18→13件に減り、LLMが判定する件数も減る。「優→後」のBERT確信度は73%→82%に改善。文が途中で切れていない方がBERTの確率推定が正確になる。
「ロ→口」の確信度が84%→60%に下がったのは、句読点再分割で文が長くなり、BERTのトークン数が増えたため。文が長いとperplexity計算の精度が落ちる傾向があるが、60%でもフィルタ閾値(30%)は超えているので検出はできる。
LLM判定(ollama Qwen3.5-4B think=false)では「優→後」「ロ→口」ともにFIX正解。4Bでも句読点再分割を入れれば、行跨ぎFPでLLMが誤FIXする問題が構造的に消える。
GPU検出とモデル配置
BERTとLLM(llama-server)をGPUとCPUにどう配置するかの組み合わせ。インストーラーがVRAM容量を見て自動選択する。
| 配置 | BERT | LLM | 必要VRAM | 選択条件 |
|---|---|---|---|---|
both-gpu | GPU | GPU (--n-gpu-layers 99) | 約5GB+ | VRAM 6GB以上 |
bert-only | GPU | CPU (--n-gpu-layers 0) | 約2.5GB | VRAM 3-6GB |
cpu-only | CPU | CPU | 0 | GPU非搭載 |
今回のテスト環境(RTX 3050 Ti 4GB)では bert-only が自動選択された。BERTスキャンは1.6秒でGPUの恩恵がある。LLMはCPU推論で1件4.6秒、18件で82.6秒。both-gpu ならLLM判定も大幅に高速化するが、VRAM 4GBではBERTとLLMの同時ロードが厳しい。Qwen3.5-4B(2.7GB)ならBERT(2.5GB)と合計5.2GBで、VRAM 6GB以上のGPUなら収まる。
Apple Siliconの場合はMPSバックエンドを使い、統合メモリなのでVRAM制約はない。BERTもllama-serverも自然にGPU上で動く。both-gpu が自動選択される。
Apple Siliconでの実測
M1 Max(64GB)で句読点再分割後のテストデータ(13件)を処理した結果。
| ステップ | 時間 |
|---|---|
| BERTスキャン (MPS) | 1.81秒 |
| LLM判定 (Metal, ngl=99) | 5.55秒 (0.43秒/件) |
| 合計 | 7.37秒 |
Windowsのテスト環境(RTX 3050 Ti 4GB、bert-only 構成)ではLLMがCPU推論になり、同じ4Bモデルで1件あたり4.6秒かかっていた。Apple Siliconは統合メモリでBERTとLLMの両方をGPU上に載せられるため、VRAM分離のCUDA環境で起きるBERT/LLM同時ロード問題がそもそも発生しない。
テンソルオフロードによる高速化の試み
llama.cppにはレイヤー単位ではなくテンソル単位でCPU/GPUを振り分ける --override-tensor オプションがある。FFNテンソル(サイズが大きくCPUでも処理可能)をCPUに逃がし、attentionテンソル(GPU向き)だけGPUに載せることで、--n-gpu-layers 99(全レイヤーGPU)にしつつVRAMに収める手法。Redditで報告されている事例では200%以上の速度向上が出ている。
RTX 3050 Ti(4GB)で試した結果:
| 設定 | 4B (3回平均) | 9B (3回平均) |
|---|---|---|
| CPU only (ngl=0) | 3.1秒/件 | 3.7秒/件 |
| レイヤーオフロード (ngl=15) | - | 3.8秒/件 |
| テンソルオフロード (ngl=99, FFN→CPU) | 3.0秒/件 | 3.8秒/件 |
差が出なかった。理由はプロンプトの短さ。A/B判定は入力が数十トークン、出力が1トークンのタスクで、GPU並列計算の恩恵が小さい。Redditの報告で効果が出ているのは数千トークンの長いプロンプトや長い生成を伴うケース。
ただしこれはllama-server単独のテスト。実際のパイプラインではBERTがGPU上の2.5GBを占有しているため、LLMに使えるVRAMがさらに少ない。BERTをアンロードしてからLLM推論するフローにすれば、テンソルオフロードで9Bモデルの一部をGPUに載せる余地が生まれ、長いコンテキストの処理で効果が期待できる。
ollamaとLM Studioはこのテンソルオフロードに非対応。llama-serverを選んだ理由の一つ。
ディレクトリ構成
ocr-correction-pipeline/
├── pyproject.toml
├── install.sh / install.ps1
├── llm/ # インストーラーが自動配置
│ ├── llama-server(.exe)
│ └── models/
│ └── Qwen3.5-4B-Q4_K_M.gguf
├── src/ocr_corrector/
│ ├── __main__.py # CLI entry
│ ├── pipeline.py # パイプラインオーケストレーター
│ ├── bert_scanner.py # BERT perplexityスキャン
│ ├── qwen_judge.py # OpenAI互換API経由のLLM判定
│ ├── escalation.py # AUTO-FIX / ESCALATE / AUTO-KEEP
│ ├── llm_server.py # llama-server自動起動/停止
│ ├── gpu_detect.py # GPU検出・配置設定
│ ├── config.py # 設定管理
│ ├── ocr_frontend.py # NDLOCR-Lite統合(optional)
│ └── webui.py # Gradio WebUI
└── tests/llm/ と ndlocr-lite/ はgit管理外。インストーラーが自動配置する。モデルを差し替えたいときは llm/models/ にGGUFを置くだけ。パイプラインはディレクトリ内の最初の .gguf ファイルを自動で使う。
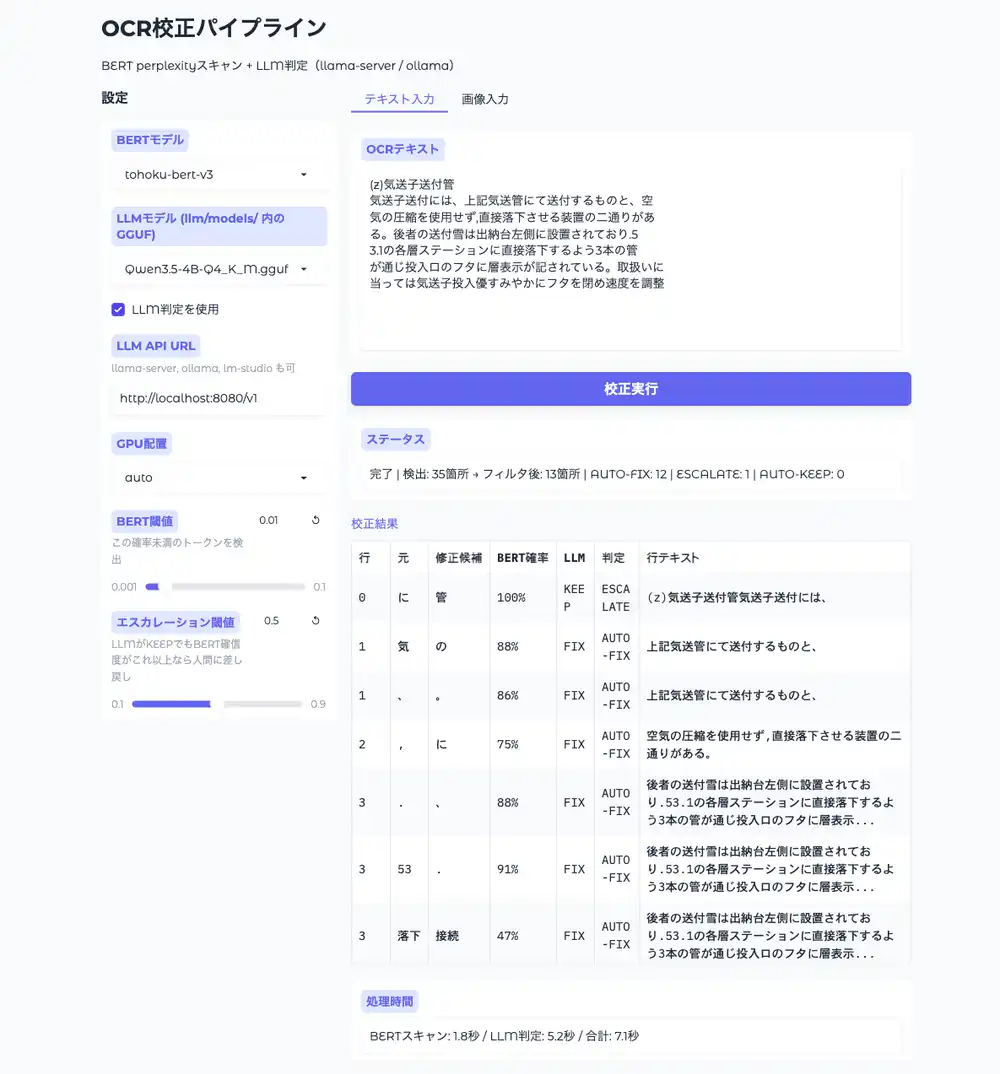
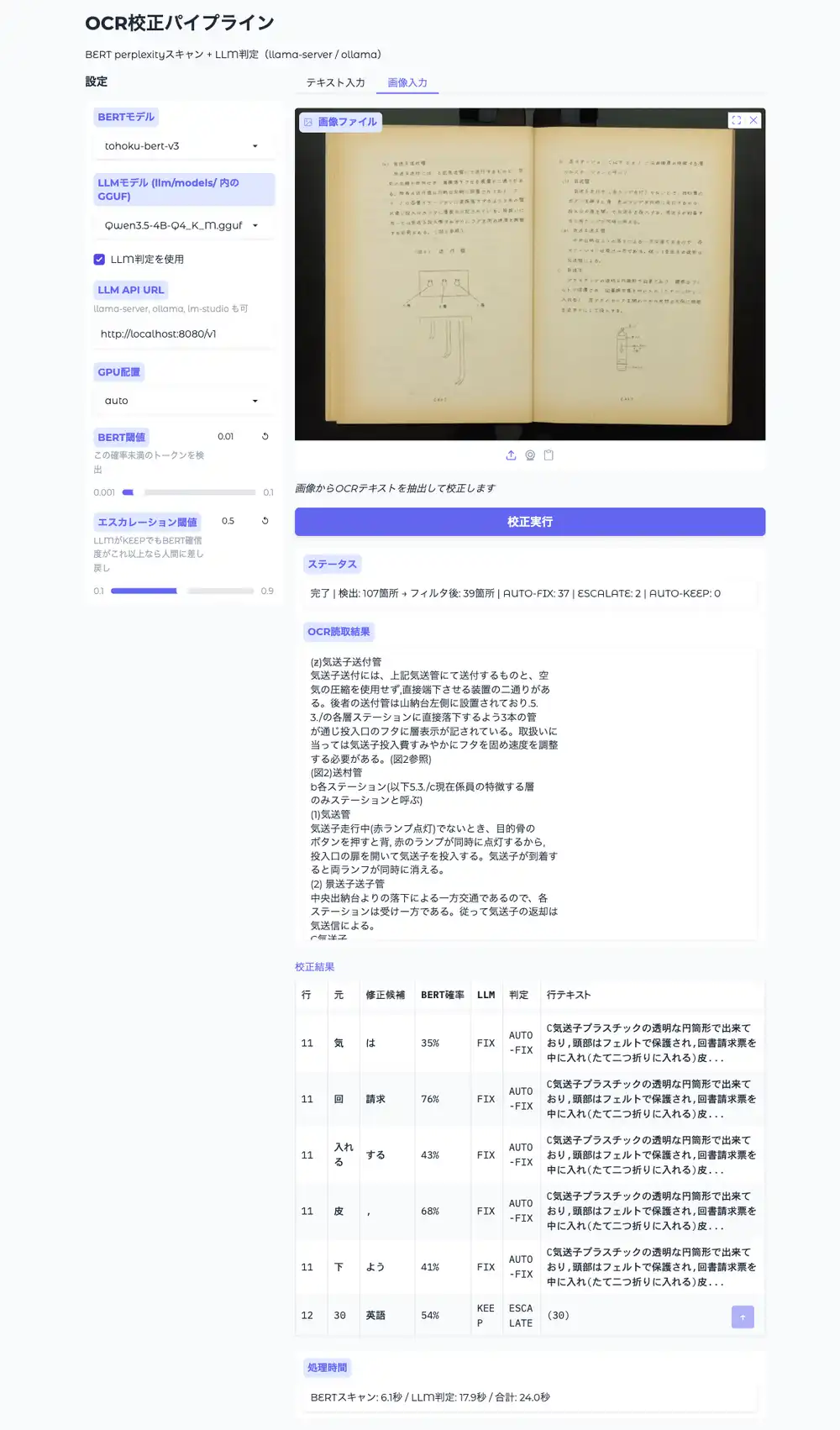
Gradio WebUI
start.bat(Windows)または start.sh(Mac/Linux)をダブルクリックするとブラウザで http://localhost:7860 にUIが開く。Gradioはインストーラーで一緒に入る。
左パネルでBERTモデル、LLMモデル(llm/models/ 内のGGUFを自動検出)、LLM API URL、GPU配置、閾値を設定。メインエリアにテキストまたは画像を入力して校正実行。処理はOCR→BERT→LLMの順で段階的に進捗表示され、結果テーブルにAUTO-FIX/ESCALATE/AUTO-KEEPが出る。画像入力の場合はOCR完了時点で読み取りテキストが先に表示される。
実行中はボタンが無効化されるので二重実行の心配はない。
テキスト入力
画像入力(NDLOCR-Lite連携)
リンク
| リンク | URL |
|---|---|
| GitHub | https://github.com/hide3tu/ocr-correction-pipeline |
| リリースページ(ZIP配布) | https://github.com/hide3tu/ocr-correction-pipeline/releases |
NDLOCRシリーズの他の記事: