国立国会図書館が作ったOCR「NDLOCR-Lite」をWindowsで動かしてみた
 目次
目次
以前、国立国会図書館(NDL)のNDLOCRをDockerでビルドしようとして散々苦労した。GPU必須、CUDA依存、ビルド通すだけで一苦労……という代物だった。
そのNDLが「NDLOCR-Lite」という軽量版を公開した。GPU不要、Dockerも不要、pip installだけで動く。Windows / Mac / Linux対応。
これは試すしかないということで、Windows 11環境でGUI・CLIの両方を動かしてみた。
リポジトリ: ndl-lab/ndlocr-lite
テスト環境
| 項目 | スペック |
|---|---|
| OS | Windows 11 Home |
| CPU | AMD Ryzen 7 5800HS |
| RAM | 16GB (8GB x2) |
| SSD | Intel 512GB NVMe |
| GPU | NVIDIA GeForce RTX 3050 Ti Laptop(今回は未使用、CPU推論のみ) |
NDLOCR-Liteとは
元のNDLOCRからDocker+GPU依存を取り払い、ONNX Runtimeベースに変わったことでCPUだけで動くようになった軽量版。内部的にはレイアウト認識(DEIMv2)、文字列認識(PARSeq)、読み順整序の3モジュール構成で、いずれもONNX形式で推論している。
GUI版(デスクトップアプリ)
Pythonとか触りたくない人はこっちが楽。GitHubのReleasesページからOS別のビルド済みバイナリをダウンロードできる。
Windows版は ndlocr_lite_v1.0.3_windows.zip で約207MB。注意点として、日本語(全角文字)を含むパスに置くと起動しないことがある。READMEにも書いてあるが、C:\ndlocr-lite のような英数字だけのパスに展開するのが安全。C:\Users\ユーザー名\デスクトップ とかだと踏む可能性がある。
実行するとSmartScreenの警告が出るので、「詳細情報」→「実行」で起動する。
GUIはFlet(FlutterベースのPython UIフレームワーク)製。日本語/英語の切り替えに対応している。
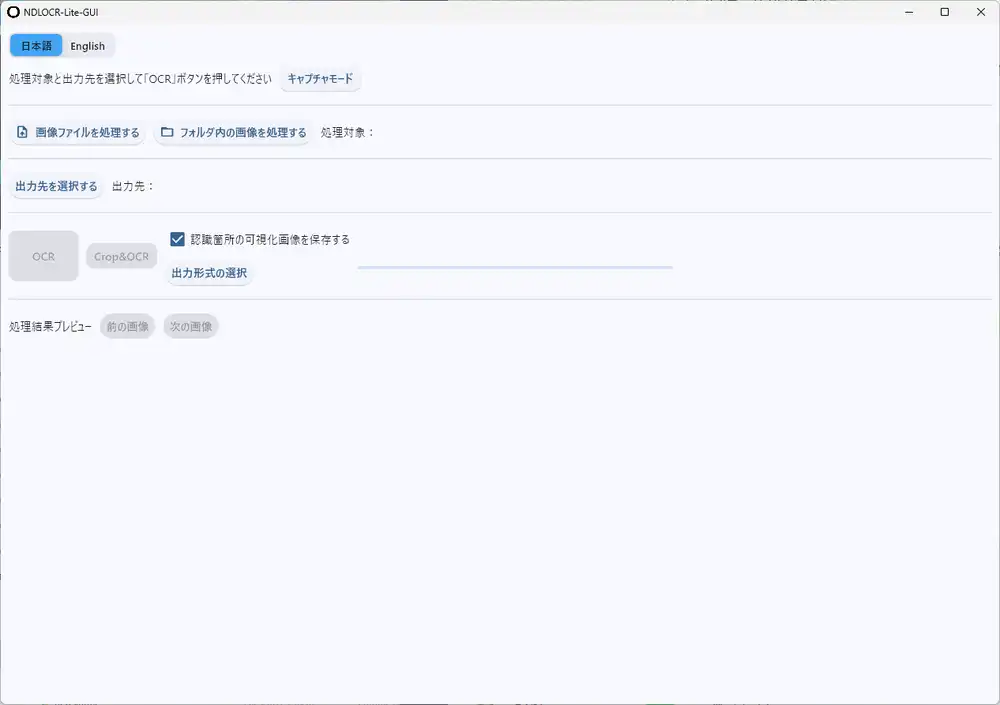
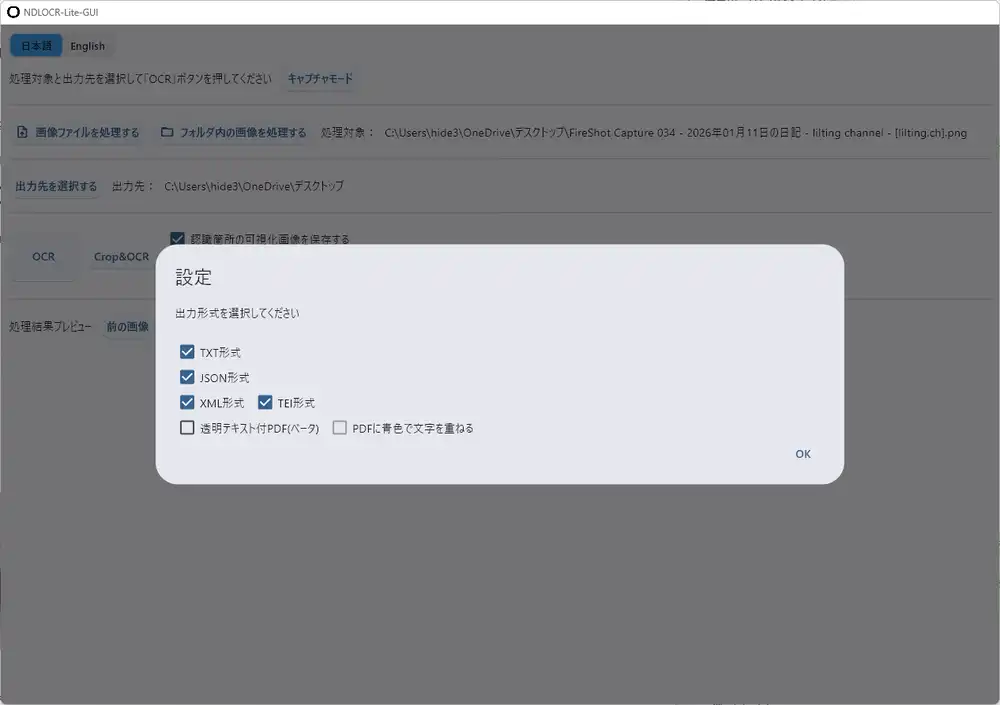
「画像ファイルを処理する」か「フォルダ内の画像を処理する」を選んで、出力先を指定して「OCR」ボタンを押すだけ。出力形式はTXT / JSON / XML / TEI形式から選べて、透明テキスト付きPDF(ベータ)にも対応している。
キャプチャモードが便利
「キャプチャモード」を押すと画面上の任意の領域を矩形選択してそのままOCRにかけられる。試しにLINEのトーク一覧画面をキャプチャしてみた。
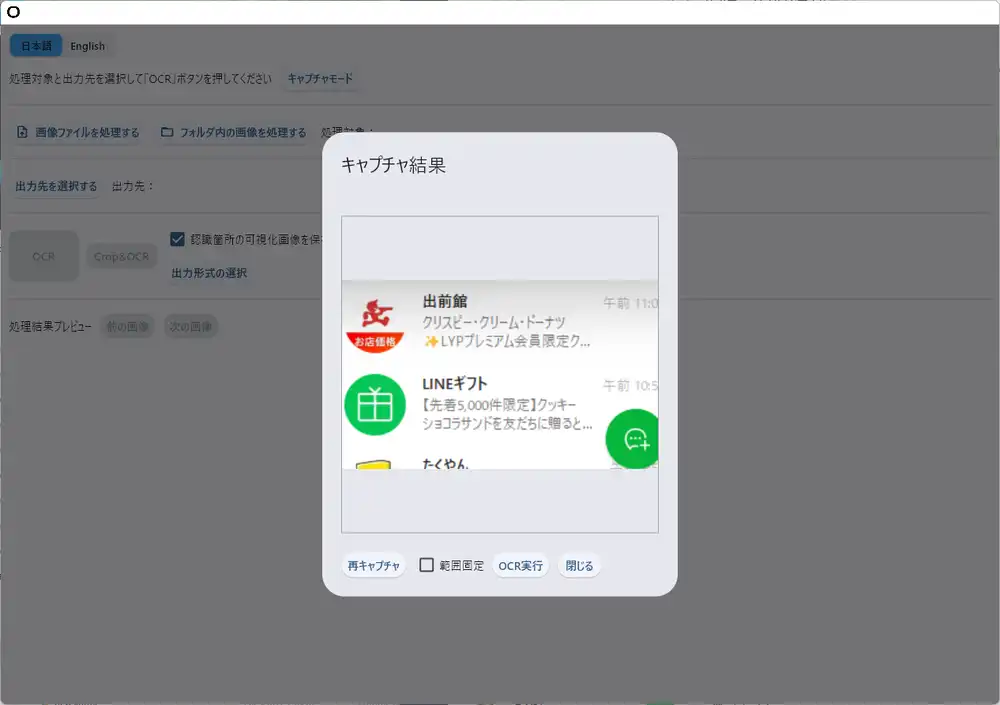
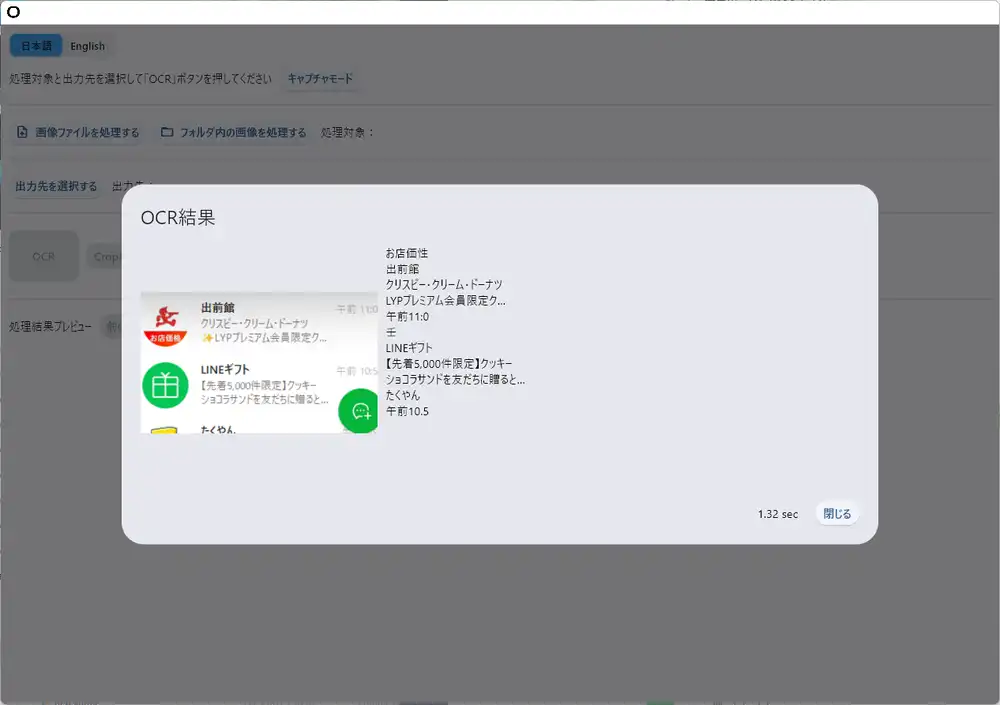
1.32秒で処理完了。「出前館」「クリスピー・クリーム・ドーナツ」「LINEギフト」「先着5,000件限定」といったテキストがそのまま読み取れている。
Webページのスクリーンショットも試した。自分のブログの日記ページをキャプチャさせたところ、1.69秒で完了。ナビゲーション、本文、関連記事まで含めてほぼ正確に読み取れていた。
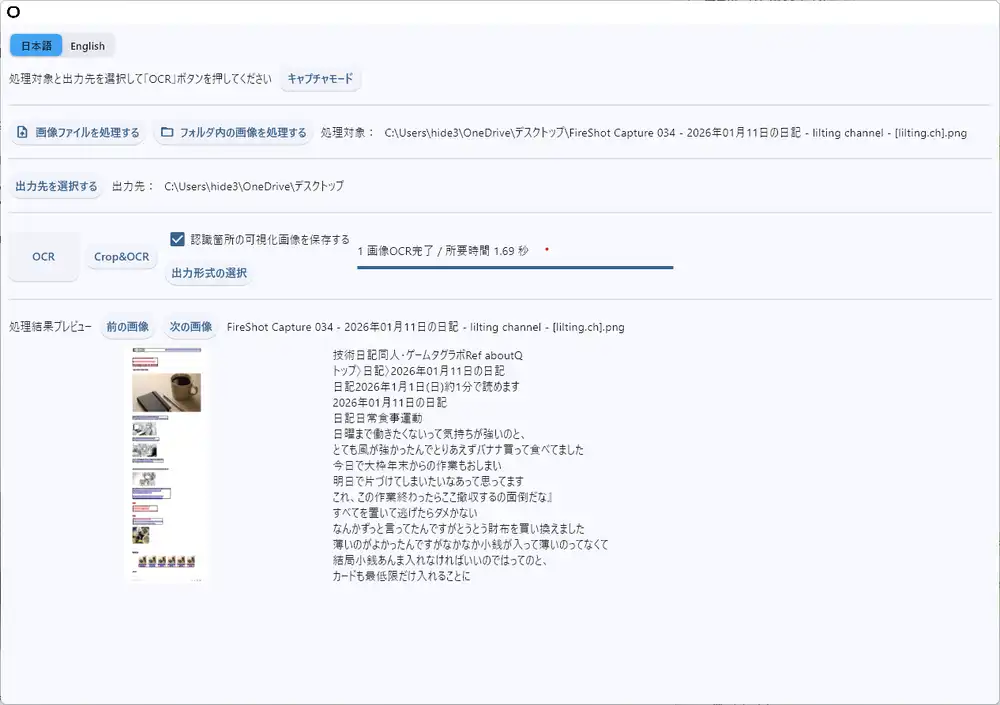
古文書専用かと思いきや、現代のWebページやアプリのスクリーンショットでも普通に使える。
CLI版
バッチ処理したい場合やスクリプトに組み込みたい場合はCLI。Python 3.10以上が必要で、今回はPython 3.12で試した。
git clone https://github.com/ndl-lab/ndlocr-lite
cd ndlocr-lite
pip install -r requirements.txt依存パッケージはflet、onnxruntime、pillow、numpy、lxmlなど。Windows固有のものはなく、そのまま入る。
src フォルダに移動してから ocr.py を叩く。
cd src
# 単一画像
python ocr.py --sourceimg [画像パス] --output [出力先]
# フォルダ一括
python ocr.py --sourcedir [フォルダパス] --output [出力先]
# 可視化画像も出力
python ocr.py --sourceimg [画像パス] --output [出力先] --viz True出力先フォルダは事前に作っておく必要がある。存在しないと Output Directory is not found. で落ちる。
サンプル画像での実行結果
リポジトリの resource/ にサンプル画像が3枚入っている。国会図書館デジタルコレクションの資料画像で、1950〜60年代の図書館内部マニュアルや月報。
| 画像 | 検出領域数 | 処理時間 |
|---|---|---|
| digidepo_2531162_0024.jpg(スタッフ・マニュアル 見開き) | 44 | 3.30秒 |
| digidepo_11048278_po_geppo1803_00021.jpg(月報) | 77 | 4.28秒 |
| digidepo_3048008_0025.jpg(年報 見開き・段組) | 168 | 9.03秒 |
CPUオンリーでこの速度はかなり速い。
出力ファイル
1枚の画像に対してTXT、JSON、XMLが出力される。--viz True をつけると、テキスト領域を赤枠、図表領域を青/緑枠で示した可視化画像も生成される。
元画像:

可視化画像:

JSONにはバウンディングボックス座標、縦書き/横書き判定、confidence値が含まれているので、後処理にも使いやすい。
認識精度
1963年のスタッフ・マニュアル(手書きっぽい活字)でのOCR結果はこんな感じだった。
(z)気送子送付管
気送子送付には、上記気送管にて送付するものと、空
気の圧縮を使用せず,直接落下させる装置の二通りがあ
る。後者の送付雪は出納台左側に設置されており.5
3.1の各層ステーションに直接落下するよう3本の管
が通じ投入ロのフタに層表示が記されている。旧字体混じりの昭和の文書でこの精度はなかなか。「管」が「雪」になっていたり、「(ヱ)」が「(z)」になっていたりと誤認識はあるが、全体の構造と読み順は正確に取れている。
段組+表組みの認識
以前NDLOCRの段組認識で苦労した話を書いたが、Lite版はどうか。昭和27年度の国会図書館年報(2段組+表組み)を試した。168領域を検出して9.03秒。
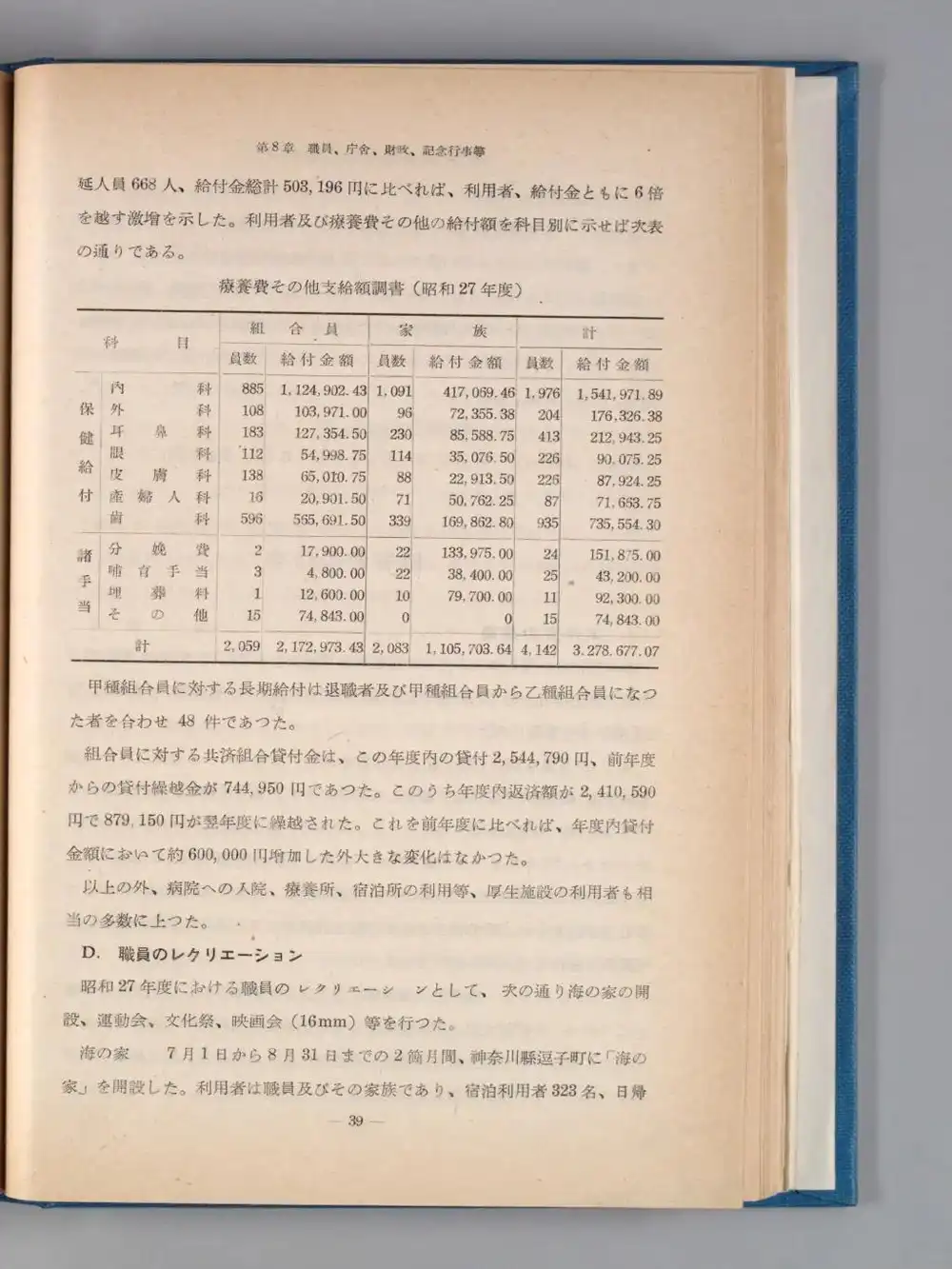
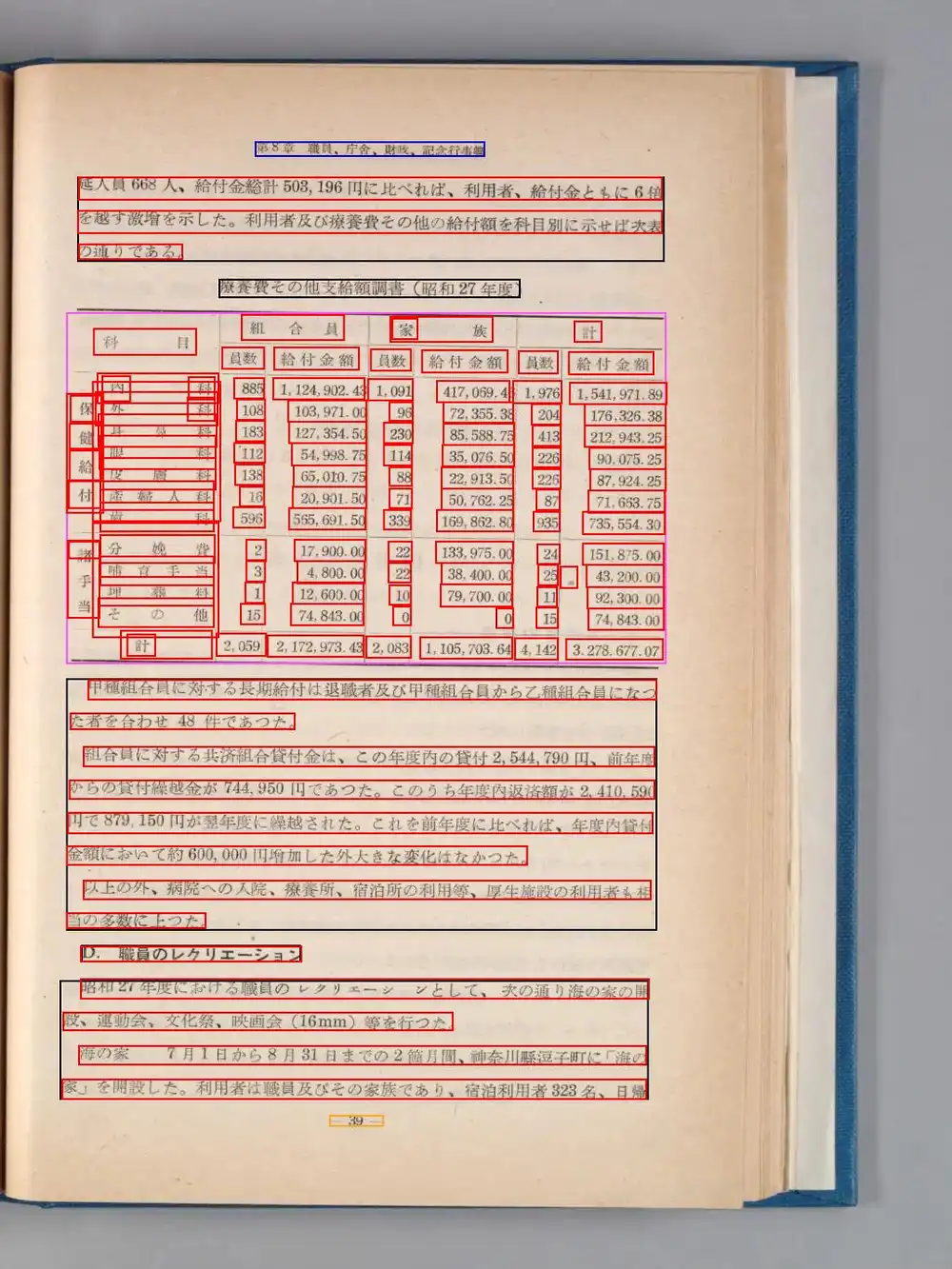
表部分のテキスト出力はこうなった。
科 目
組合員
員数
給付金額
...
内科
外 科
皮膚科
産婦人科
歯科
眼科
...
885
108
183
112
138
16
596
...
1,124,902.43
65,010.75
127,354.50
54,998.75
565,691.50TXTだとセル単位でテキストは拾えているものの、「内科 885 1,124,902.43」のように行でつながった状態にはならず、列単位でまとまって出力される。科目名がまとめて出て、次に員数がまとめて出て、その次に金額がまとめて出る、という感じ。
ただしJSON出力にはセルごとのバウンディングボックス座標とconfidence値が入っている。
{"text": "内科", "confidence": 0.439, "boundingBox": [[1128,401],[1128,434],[1259,401],[1259,434]]}
{"text": "885", "confidence": 0.774, "boundingBox": [[1275,406],[1275,429],[1308,406],[1308,429]]}
{"text": "1,124,902.43", "confidence": 0.847, "boundingBox": [[1317,406],[1317,430],[1416,406],[1416,430]]}Y座標がほぼ同じ(401〜406)なので、座標でグルーピングすれば「内科 / 885 / 1,124,902.43」が同じ行だと判定できる。セル結合やヘッダーの階層構造までは再現できないが、表データとして使いたい場合はこのJSON座標から自分で再構成する形になる。
技術的な補足
開発者の青池氏(@blue0620)が公開時にアーキテクチャの詳細をポストしていたので要約する。開発コンセプトは「Snipping Toolのように事務用のロースペックマシンでも快適に動かせて高精度」で、DRAMが1GB程度空いていれば動くとのこと。
CPU推論を速くするための工夫
CPUでOCRをやるとき律速になるのは文字列認識。一度に読める文字数を少なくすればモデルを軽くできるが、英文など1行あたりの文字数が多い場合に対応できなくなる。
そこでNDLOCR-Liteでは大中小の文字列長に対応した複数のモデルを用意し、各行をどのモデルで読むべきかを事前に推論して割り当てている。
この割り当ての推論は、レイアウト認識のDEIMv2に分類用のヘッドを追加して、主損失とは別の補助損失として実装。1回の順伝播でレイアウト検出とモデル割り当ての仕分けを同時に行う。振り分け専用の分類器を別途ロードしないので、メモリも推論コストも増えない。
かなチャットのインテント分類でも、分類専用モデルを立てずにHaikuに相乗りさせて振り分けている。速度を出すために「無駄なロードをしない」というスタンスは、OCRでもLLMアプリでも共通する設計判断。
なぜOCRだとDRAM 1GBで済むのか
この「複数サイズのモデルを事前にメモリに載せておいてルーターで振り分ける」構造は、LLMのMoE(Mixture of Experts)と同じ発想。GLMやMixtral、DeepSeekなどが採用しているアーキテクチャだが、LLMでこれをやるにはVRAMが何十GBも必要になる。
LLMの場合、例えば72Bパラメータのモデルは量子化しても重みだけで40GB前後。さらに推論時にはKVキャッシュ(コンテキスト長に比例)や中間計算の作業領域が必要で、合計90GB超えということが普通にある。モデル本体より「処理するための場所」のほうがデカいくらい。
OCRモデルは1つ数十MB程度。大中小3つ全部メモリに載せても数百MBで、推論ワークスペースも小さい。しかも同時に推論するのは振り分けられた1つだけなので、実際に使う作業領域はさらに限られる。「巨大な汎用モデル1つ」ではなく「小さな専門家を複数」にすることで、同じMoE的な設計でもメモリ要件が桁違いに下がる。開発者が「DRAM 1GBあれば動く」と言い切れるのはこの構造のおかげ。
マルチスレッドでの文字列認識
割り当てた各モデルの文字列認識はマルチスレッドで並列実行する。文字列長がおおむね揃った計算を並列するので効率的(NLPコンペでよくやるやつ、とのこと)。
誤分類対策として、マルチスレッド処理は小→中→大の順に行い、各モデルの上限付近の文字数で出力された場合は次に大きなモデルでもう一度読み直す。最初から大きなモデルで全部読めば安定するが非力なPCでは重くなるので、できるだけ余計な計算をしない設計になっている。
その他
- Kaggler出身の開発者のノウハウが詰まっているとのこと
- 組織内版にはollamaエンドポイントと連携してOCR結果から情報抽出できる機能もあるらしい
- GPU版のonnxruntimeを入れれば
--device cudaでGPU利用も可能(ベータ) - ライセンスはCC BY 4.0
前回の苦労何だったんだよってくらい普通に動いて拍子抜けした…精度は高いしメモリも食いづらいのでOCR作業が大量にある人はバッチ作って回してもいいかも。
続編: NDLOCR-LiteとローカルLLMで昭和の文書をOCR校正する(Mac版セットアップ + Qwen 3.5 / Swallowでの校正実験)