ScanSnap+NDLOCR-Liteで機密文書をローカルOCRするホットフォルダを作った
 目次
目次
前回の記事でラズパイ+Samba共有のホットフォルダOCRステーションを構想として書いた。ラズパイは持ってないしLAN接続もできない環境だったので、Mac上で完結させることにした。
構成
ScanSnap iX100(携帯用スキャナ)でスキャンした画像を監視スクリプトが検知し、NDLOCR-Lite CLIでOCRを実行、結果を別フォルダに移動する。すべてローカルで完結する。
| 項目 | スペック |
|---|---|
| Mac | Apple M1 Max / 64GB RAM |
| OS | macOS Tahoe 26.2 |
| スキャナ | ScanSnap iX100(USB有線接続) |
| OCR | NDLOCR-Lite CLI |
| LLM | Qwen 3.5 35B(ollama v0.17.1-rc2) |
flowchart LR
A["ScanSnap iX100"] -->|USB| B["~/Scans/"]
B -->|監視| C["hot_ocr.py"]
C -->|OCR実行| D["NDLOCR-Lite<br/>CLI"]
D -->|結果出力| E["~/Scanned/<br/>txt / json / xml"]セキュリティ設計
機密文書を扱う前提で設計している。
ネットワーク遮断: Wi-Fiを切ればエアギャップになる。クラウドOCR(Google Cloud Vision等)に送信すること自体がコンプライアンス的にNGなケースで有効。
スキャナもUSB直結: iX100はWi-Fi対応だが、エアギャップを謳うなら無線は使えない。USB有線一択。
フルディスクアクセスを開けない: 当初 ~/Documents/Scans/ を保存先にしようとしたが、macOSのプライバシー保護でターミナルからアクセスできなかった。フルディスクアクセスをターミナルに付与すれば解決するが、機密文書を扱う環境でアプリの権限を広げるのは矛盾する。保存先を ~/Scans/ に変更して回避した。
ScanSnap Home設定
ScanSnap iX100の設定。Home側の管理機能は不要なのでファイル保存のみにする。
- プロファイル: Mac(ファイル保存のみ)
- 保存先:
~/Scans/ - ファイル形式: JPEG
- 連携アプリ: なし(切るとスキャン後の確認ダイアログが出なくなり、即座にフォルダに保存される)
iX100は片面スキャンのみ。両面の書類は表→裏で2回通す。
監視スクリプト
Pythonの標準ライブラリだけで書いた。watchdog などの外部依存はなし。3秒間隔のポーリングで ~/Scans/ を監視し、画像ファイルを検知したらNDLOCR-Lite CLIを呼び出す。
#!/usr/bin/env python3
"""
使い方:
python hot_ocr.py # デフォルト設定で起動
python hot_ocr.py --viz # 可視化画像も出力
"""
import argparse
import subprocess
import time
from datetime import datetime, timezone, timedelta
from pathlib import Path
JST = timezone(timedelta(hours=9))
IMAGE_EXTENSIONS = {".jpg", ".jpeg", ".png", ".tif", ".tiff", ".bmp", ".jp2", ".pdf"}
DEFAULT_NDLOCR_DIR = Path.home() / "projects" / "ndlocr-lite"
DEFAULT_SCANS_DIR = Path.home() / "Scans"
DEFAULT_SCANNED_DIR = Path.home() / "Scanned"
STABLE_WAIT = 2.0
POLL_INTERVAL = 3.0ポイントは wait_until_stable() で、ファイルサイズが2秒間変化しないことを確認してから処理に入る。ScanSnapが書き込み中のファイルを食わないためのガード。
def wait_until_stable(path: Path, wait: float = STABLE_WAIT) -> bool:
"""ファイルサイズが安定するまで待つ。"""
try:
size1 = path.stat().st_size
time.sleep(wait)
if not path.exists():
return False
size2 = path.stat().st_size
return size1 == size2 and size2 > 0
except OSError:
return FalseNDLOCR-Liteは別リポジトリ(~/projects/ndlocr-lite/)に置いてあるので、そのvenvのPythonをsubprocessで呼ぶ。hot-ocr側にOCRの依存をインストールする必要がない。ndlocr-liteをgit pullで更新しても影響しない。
def run_ocr(image_path, output_dir, ndlocr_dir, viz):
ocr_script = ndlocr_dir / "src" / "ocr.py"
venv_python = ndlocr_dir / ".venv" / "bin" / "python"
python_cmd = str(venv_python) if venv_python.exists() else "python3"
cmd = [
python_cmd, str(ocr_script),
"--sourceimg", str(image_path),
"--output", str(output_dir),
]
if viz:
cmd.extend(["--viz", "True"])
result = subprocess.run(cmd, cwd=str(ndlocr_dir / "src"),
capture_output=True, text=True, timeout=300)
return result.returncode == 0処理が終わると元画像をScannedに移動する。OCR結果(txt, json, xml)と元画像が1つのフォルダにまとまる。
def process_file(image_path, scanned_dir, ndlocr_dir, viz):
timestamp = datetime.now(JST).strftime("%Y-%m-%d_%H%M%S")
result_dir = scanned_dir / f"{timestamp}_{image_path.stem}"
result_dir.mkdir(parents=True, exist_ok=True)
success = run_ocr(image_path, result_dir, ndlocr_dir, viz)
if success:
image_path.rename(result_dir / image_path.name)メインループはシンプル。起動時に既存ファイルを先に処理し、その後ポーリングで待機。Ctrl+Cで終了。
def main():
# 起動時に既存ファイルがあれば先に処理
scan_and_process(scans_dir, scanned_dir, ndlocr_dir, viz)
# ポーリングで監視
while True:
time.sleep(POLL_INTERVAL)
scan_and_process(scans_dir, scanned_dir, ndlocr_dir, viz)全文はhot-ocrリポジトリを参照(※リポジトリは未公開)。
実機テスト
マイナンバーカードの更新手続き案内をスキャンした。全員に送られる共通書類なので個人情報は含まない。カラムが多く、QRコードやイラストが混在するレイアウトで、OCRの実力を測るにはちょうどいい。
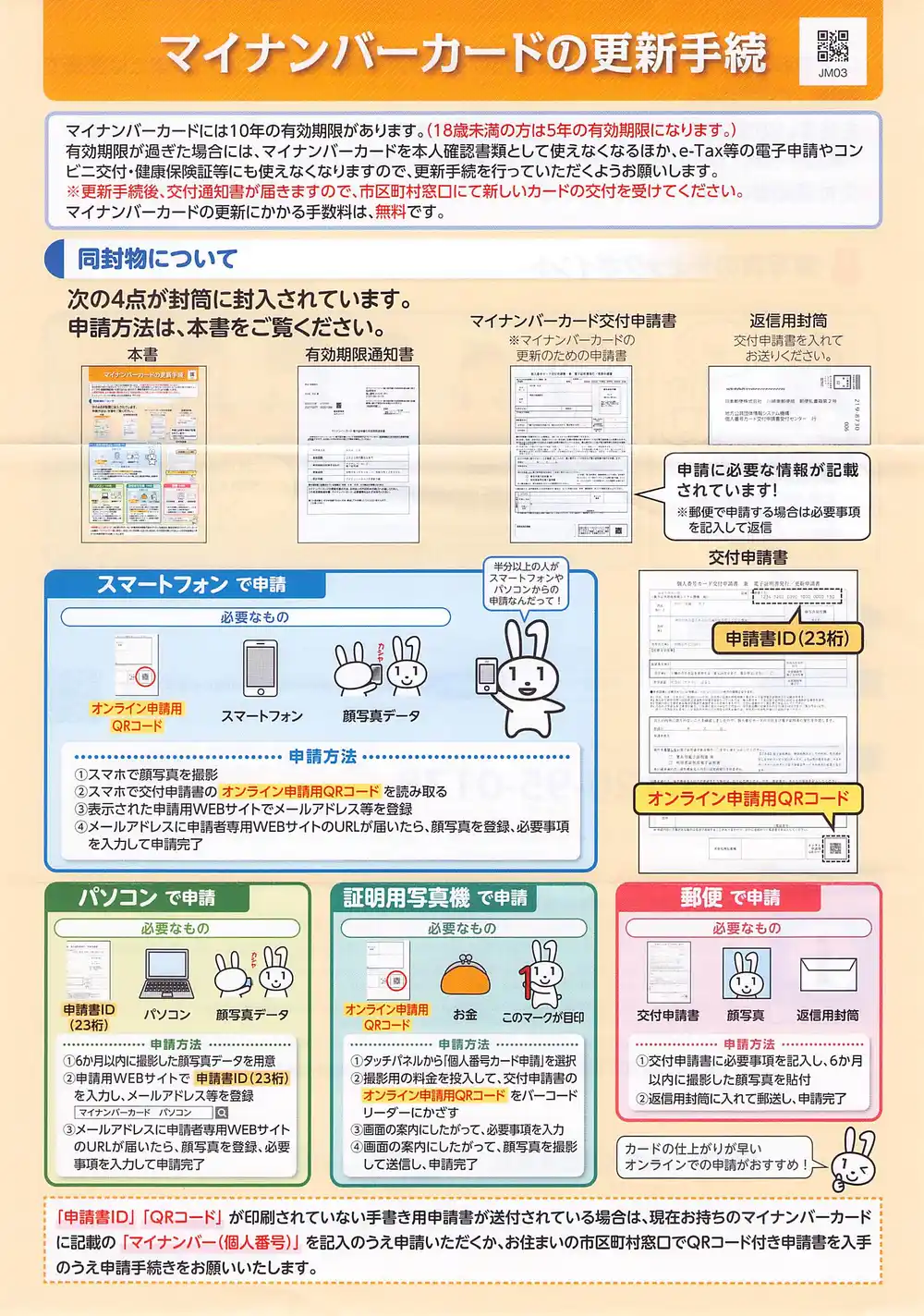
スクリプトを起動してスキャンすると数秒でOCR結果が出力された。M1 MaxのCPU推論で十分な速度。iX100は手差しなので1枚スキャンしている間にOCRが終わる。
OCR結果
本文の読み順は正確で、レイアウト認識も機能していた。誤読は数箇所。
- 「マイナンパーカード」→ 正しくは「マイナンバーカード」
- 「住上がり」→ 正しくは「仕上がり」
- 「すすめ」→ 正しくは「おすすめ」
面白かったのは装飾の誤認識。文中の点線罫線が !!!!!!!!!!!!!!!!! として読まれていた。原文のビックリマークは1個だけ。
さらに「カードの住上がりが早いすすめ!!!!!」という文がOCR結果に含まれていたが、画像上のどこから読んだか特定できなかった。この書類にはうさぎのマスコット「マイナちゃん」がいて、イラスト周辺でレイアウト検出がテキスト領域の境界を見誤り、存在しないテキストを生成したか、装飾の一部を文字として合成した可能性が高い。マイナちゃんに幻覚作用がある。
多言語テスト
裏面は多言語(英語・中国語・韓国語・スペイン語・ポルトガル語)で書かれている。NDLOCR-Liteは日本語OCRなので想定外の入力だが、どう崩れるか試した。

処理時間は1.9秒。日本語部分はほぼ正確に読めた。多言語部分の結果:
- 英語: 概ね読めるが
direet(direct)、nmero(número)など誤読あり - 中国語簡体字: ほぼ崩壊。
迸行咨洵、清拔打、洋情也可妨向。日本語の漢字に引きずられている - 中国語繁体字: 簡体字よりはマシだが
悠想、遺請撥打など怪しい - スペイン語/ポルトガル語: アクセント記号が全滅。
espafiol(español)、portugus(português) - 韓国語: 完全消滅。ハングルが
会社会社会社会社会社会社...の無限ループに化けた
韓国語の崩壊が一番面白い。NDLOCR-Liteの文字認識モデル(PARSeq)は日本語の文字セットで学習しているので、ハングルのグリフを「一番近い日本語の文字」に無理やりマッピングした結果、すべて「会社」になった。
日本語部分だけ読めていれば実用上は困らない。
LLM校正
OCR結果のテキストをQwen 3.5(35B)に渡して校正させた。前回の記事ではSwallow(Qwen3-Swallow-30B-A3B)も試したが、今回は現代の公文書なので日本語特化モデルは不要。Qwen 3.5はollamaの --think=false でthinkingを切れる点も有利(SwallowはGGUF変換の問題でthinkingが切れない)。
ollama run qwen3.5:35b --think=false "以下はOCRで読み取ったテキストです。
誤字・誤読を修正してください。内容は一切変えず、
明らかな文字認識ミスだけ直してください。
修正したテキストのみ出力し、説明は不要です。
---
(OCRテキストを貼る)
---"校正結果をdiffで確認する。
- マイナンパーカードを本人確認書類として使えなくなるほか、e-Tax等の電子申請やコン
- ビニ交付・健康保険証等にも使えなくなりますので、
+ マイナンバーカードを本人確認書類として使えなくなるほか、e-Tax等の電子申請やコンビニ交付・健康保険証等にも使えなくなりますので、
- カードの住上がりが早いすすめ!!!!!!!!!!!!!!!!!!!!!!!!
+ カードの仕上がりが早いおすすめ!!!!!!!!!!!!!!!!!!!!!!!文字の誤読(パ→バ、住→仕、すすめ→おすすめ)は直せた。改行で分断された「コン/ビニ」も結合された。人間がdiffを見るだけで確認が終わる。
直せなかったのは装飾の誤認識。! の連打はテキストだけ見ても罫線かビックリマークか判断できない。[ → 「 の誤読も見逃した。テキストベースの校正の構造的な限界で、画像を見ないと判断できない部分は残る。
前回の記事では昭和38年の文書で「一方交通」を「一方通行」に直してしまうアンカリング効果が問題になったが、今回は現代の公文書なのでその心配はなかった。
OCRとLLM校正の分離
ホットフォルダスクリプトにLLM校正を組み込まなかった理由がある。スキャン速度のほうがOCR速度より速い。LLM校正まで含めると1枚あたりの処理時間が伸びて、スキャン→OCRのパイプラインが詰まる。
分離しておけば:
- ガーッとスキャンして
~/Scans/に溜める - hot_ocr.py がバックグラウンドで順次OCR →
~/Scanned/に移動 - 全部終わったあとに校正スクリプトで一括LLM校正
校正スクリプトは未実装だが、~/Scanned/ 内の .txt を読んでollamaに投げてdiffを出すだけなのでシンプルに作れる。
ラズパイ構成との比較
series-guideで書いたラズパイ構成と比較すると:
| ラズパイ+Samba | Mac完結 | |
|---|---|---|
| ネットワーク | Samba共有が必要 | 不要 |
| LLM校正 | Piには載らない | M1 Maxなら載る |
| 常時稼働 | 数ワットで放置可能 | スリープ管理が必要 |
| 携帯性 | Pi+電源+スキャナの3点セット | MacBook+スキャナの2点 |
| コスト | Pi 5で約6万 | 既存Macを流用 |
ラズパイの利点は消費電力とサイズ感で、スキャナの横に置いて常時稼働する運用に向いている。Mac完結はLLM校正まで回せる点と、既存のMacを流用できる点で勝る。用事があるときだけ起動する運用なら常時稼働の利点は効かないので、Mac完結のほうが合理的だった。
テスト用に手元にあった書類をスキャンしていたら、マイナンバーカードの電子証明書の期限が切れていることに気づいた。銀行で怒られるし医者に行くのにも困る。オンラインで更新申請できるらしいので、まず証明写真を撮ってこないといけない。