NDLOCR-LiteをiOSネイティブアプリに載せてスマホOCRする
 目次
目次
これまでWindows、Mac、ブラウザ(他の人の実装)と試してきたが、次はiOSネイティブアプリに載せる。
ブラウザ版(ndlocrlite-web)はすでに存在するが、146MBのWASMモデルをダウンロードして初期化する時間がかかる。ネイティブアプリならモデル同梱でコールドスタートから数秒でカメラOCRに入れる。起動の速さが使い勝手に直結するアプリなので、ネイティブで組む意味がある。
検証環境
| 項目 | スペック |
|---|---|
| 端末 | iPhone 13 Pro Max |
| iOS | 18.6 |
| チップ | A15 Bionic |
| RAM | 6 GB |
モデル構成
アプリに同梱するONNXモデルは4つ。
| モデル | 用途 | サイズ | 入力shape |
|---|---|---|---|
| deim-s-1024x1024.onnx | レイアウト検出(DEIMv2) | 38.4 MB | [1, 3, 800, 800] float32 |
| parseq-ndl-16x256-30 | 文字認識(~30文字) | 34.2 MB | [1, 3, 16, 256] float32 |
| parseq-ndl-16x384-50 | 文字認識(~50文字) | 35.2 MB | [1, 3, 16, 384] float32 |
| parseq-ndl-16x768-100 | 文字認識(~100文字) | 39.1 MB | [1, 3, 16, 768] float32 |
DEIMv2のファイル名は1024x1024だが、実際の入力サイズは800x800。Python版の推論コードを読むとinput_size=800になっている。ファイル名を信じてはいけない。
合計約147MB。iOSアプリのバンドルとしては大きめだが、App Storeの上限(4GB)からすれば問題ない。
推論パイプライン
flowchart TD
A["カメラ撮影"] --> B["Vision台形補正"]
B --> C["DEIMv2<br/>レイアウト検出"]
C --> D["テキスト行<br/>矩形切り出し+縦書き回転"]
D --> E["PARSeq<br/>文字認識(カスケード)"]
E --> F["信頼度スキャン<br/>softmax確率で低信頼文字を検出"]
F --> G["読み順ソート"]
G --> H["校正結果表示<br/>怪しい箇所ハイライト"]レイアウト検出のDEIMv2が画像中のテキスト行を矩形で検出し、PARSeqが各矩形から文字を読む。PARSeqは文字列の長さに応じて3モデルをカスケードで使い分ける(短い行→256モデル、長い行→768モデル)。
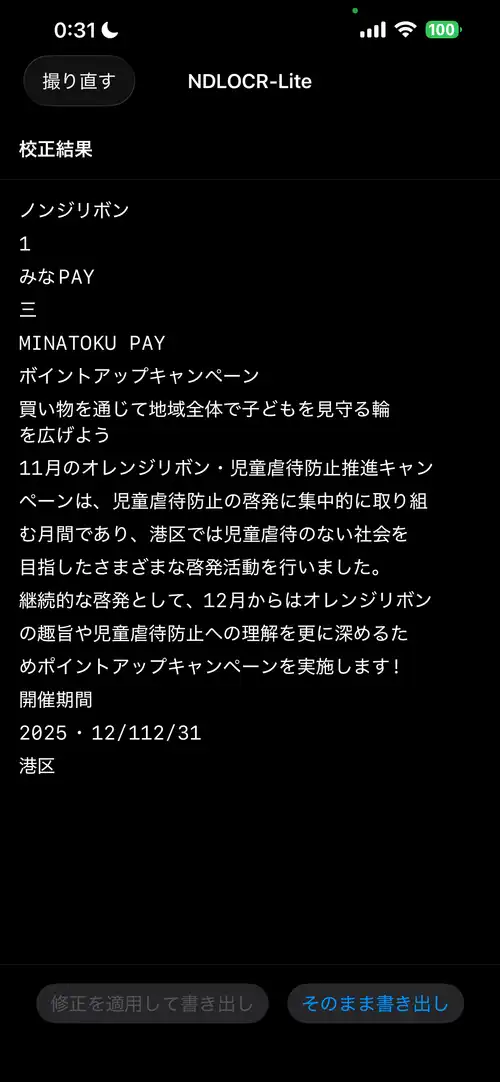
実機(iPhone 13 Pro Max)での動作。入力はみなトクPAYのチラシ(横書き)。
入力画像(みなトクPAYチラシ)

OCR結果(iPhone 13 Pro Max)
Xcodeプロジェクトのセットアップ
ONNX Runtime の導入(SPM)
Swift Package Managerで追加する。
- Xcode → File → Add Package Dependencies
- URL:
https://github.com/microsoft/onnxruntime-swift-package-manager - バージョン: 1.20.0以降
- ライブラリ
onnxruntimeをターゲットに追加
xcodegen(project.yml)を使う場合:
packages:
onnxruntime:
url: https://github.com/microsoft/onnxruntime-swift-package-manager
from: "1.20.0"
targets:
NDLOCRLite:
type: application
platform: iOS
dependencies:
- package: onnxruntime
product: onnxruntimeモデルファイルの追加
ndlocr-liteリポジトリのsrc/model/から4つの.onnxファイルをXcodeプロジェクトにドラッグ&ドロップ。ターゲットのBundle Resourcesに含まれていることを確認する。
文字セット定義のNDLmoji.yamlも必要。PARSeqの出力インデックスを文字に変換するのに使う。約7142文字(EOS含む。ひらがな・カタカナ・漢字・英数字・記号)が定義されている。
モデルの読み込みと推論
ONNX RuntimeのiOS APIはObjective-Cベースで、Swiftからはブリッジ経由で使う。
import OnnxRuntimeBindings
let env = try ORTEnv(loggingLevel: .warning)
let options = try ORTSessionOptions()
try options.setIntraOpNumThreads(2)
try options.setGraphOptimizationLevel(.all)
let modelPath = Bundle.main.path(forResource: "deim-s-1024x1024", ofType: "onnx")!
let session = try ORTSession(env: env, modelPath: modelPath, sessionOptions: options)DEIMv2の推論
入力は2つ。画像テンソルimagesとorig_target_sizes。
let imageTensor = try ORTValue(
tensorData: NSMutableData(data: imageData),
elementType: .float,
shape: [1, 3, 800, 800] as [NSNumber]
)
// orig_target_sizes: Python実装に合わせてinput_sizeを渡す(元画像サイズではない)
var sizeArray: [Int64] = [800, 800]
let sizeData = NSMutableData(bytes: &sizeArray, length: MemoryLayout<Int64>.size * 2)
let sizeTensor = try ORTValue(
tensorData: sizeData, elementType: .int64, shape: [1, 2] as [NSNumber]
)
let outputs = try session.run(
withInputs: ["images": imageTensor, "orig_target_sizes": sizeTensor],
outputNames: ["labels", "boxes", "scores", "char_count"],
runOptions: nil
)出力のboxesからテキスト行の矩形座標を取得し、scoresでフィルタリングする。出力ラベルは1始まりで、classIndex = label - 1でndl.yamlのクラス定義に対応する。テキスト行に該当するクラスインデックスは[1, 2, 3, 4, 5, 16](line_main, line_caption, line_ad, line_note, line_note_tochu, line_title)。
PARSeqの推論
DEIMv2が検出した各テキスト行の矩形を切り出して、行の幅からモデルを選択してPARSeqに渡す。
// アスペクト比から文字数を推定してモデル選択
let aspectRatio = Float(width) / Float(height)
let estimatedChars = Int(aspectRatio * 2)
let config = parseqConfigs.first { estimatedChars <= $0.maxChars }
?? parseqConfigs.last!
let inputTensor = try ORTValue(
tensorData: NSMutableData(data: inputData),
elementType: .float,
shape: [1, 3, 16, config.width as NSNumber] as [NSNumber]
)出力テンソル名がモデルごとに異なる点に注意("13469", "21189", "40488")。Python版のONNXグラフを確認して正しい名前を設定する。
出力のfloat配列からargmaxで文字インデックスを取得し、NDLmoji.yamlの文字セットでデコードする。インデックス0はEOS(End of Sequence)トークン。
校正
BERTの文字マスク予測が使えなかった理由
最初はBERT(bert-base-japanese-v3)のperplexityスキャンで誤認識を検出しようとした。OCR結果の各文字位置を[MASK]に置き換えてBERTに推論させ、元の文字の予測確率が低い箇所を「怪しい」と判定するアプローチ。
bert-base-japanese-v3はMeCab + WordPieceでトークナイズされた入力を前提としている。「児童虐待」ならMeCabで「児童」「虐待」に分割され、WordPieceでサブワードトークンになる。BERTの事前学習はこの粒度で行われているので、サブワード単位での文脈予測ができる。
iOSにMeCabを載せるのは依存が重いため、文字単位でトークナイズした。「児」「童」「虐」「待」のように1文字ずつ独立したトークンになる。BERTの語彙テーブルには1文字トークンも存在するが、学習時にその文字が単独トークンとして出現するコンテキストが少ないため、確率分布が不安定になる。「児童虐待」「オレンジリボン」のような正しいテキストにも高い異常スコアが出て、全文が真っ赤にハイライトされた。
閾値を下げても、ratio-based scoring(BERTの予測1位確率 / 元文字の確率)に切り替えても、指摘位置がずれる根本問題は変わらなかった。文字単位トークナイズでBERTの日本語校正をやるのは無理がある。
モデルは521MB(FP32)→131MB(INT8量子化)まで縮小してバンドルに同梱できるサイズにはなったが、判定がそもそも使えなかったため削除した。
PARSeq信頼度による代替
BERTを捨てて、PARSeq自体のsoftmax出力を校正に使う。PARSeqが各文字を出力するとき、softmax後の最大確率がそのまま「モデルがその文字にどれだけ自信があるか」の指標になる。追加モデル不要で、デコード処理の中で取れる。
private func decodeOutput(data: Data, charCount: Int) -> (String, [CharConfidence]) {
let floats = data.withUnsafeBytes { Array($0.bindMemory(to: Float.self)) }
let seqLength = floats.count / charCount
var result = ""
var confidences: [CharConfidence] = []
for pos in 0..<seqLength {
let logits = Array(floats[(pos * charCount)..<((pos + 1) * charCount)])
// softmax
let maxLogit = logits.max() ?? 0
let exps = logits.map { exp($0 - maxLogit) }
let sumExps = exps.reduce(0, +)
let probs = exps.map { $0 / sumExps }
// argmax
let (maxIdx, maxProb) = probs.enumerated().max(by: { $0.1 < $1.1 })!
if maxIdx == 0 { break } // EOS
let char = charset[maxIdx]
result.append(char)
confidences.append(CharConfidence(
char: char,
confidence: maxProb,
topCandidates: /* top3 */ ...
))
}
return (result, confidences)
}閾値と検出パターン
信頼度0.5未満を「怪しい」と判定し、上位15件を赤くハイライトする。0.5は「モデルが50%未満の確率でしか正しい文字を選べていない」ライン。
開発初期の段階では、DEIMv2の重複検出(同じ行をline_mainとline_captionの両方で拾う)やカメラのプレビュー範囲と実際の撮影範囲のずれがあり、不正確な矩形でPARSeqに渡していたため低信頼の文字が多く出ていた。検出されていたパターン。
| 信頼度 | パターン | 原因 |
|---|---|---|
| 0.1前後 | 行頭・行末の断片文字 | 矩形境界で文字が途切れている |
| 0.2〜0.3 | 記号の誤認識 | ハイフン↔ダッシュ、コンマ↔ピリオド |
| 0.3〜0.5 | 類似字形の混同 | 似た字形の取り違え |
NMSで重複矩形を除去し(IoU > 0.5を抑制)、カメラのresizeAspectFillに合わせた撮影画像のクロップを実装した結果、PARSeqに渡る画像の品質が上がって低信頼文字はほぼ出なくなった。上のスクリーンショットでも赤ハイライトは入っていない。
信頼度が高いのに誤っているケース(confident error)は拾えないが、これはどの事後校正手法でも同じ限界。実用上は、前処理の精度を上げることが校正の負荷を下げる一番の近道だった。
UIでは低信頼文字を赤くハイライトし、タップするとPARSeqのTop3候補を選択できるシートが開く。修正を適用したらシェアシートで書き出す。
画像前処理のハマりどころ
ここが一番時間を食った。PythonだとOpenCV + NumPyで数行の前処理が、iOSだと座標系・ピクセルフォーマット・スケールの罠が待っている。
Retina scaleの罠
UIGraphicsImageRenderer(size: CGSize(width: 800, height: 800)) で描画すると、iPhone 13 Pro Max(3x Retina)では2400x2400ピクセルの画像が生成される。モデルが期待する800x800とまったく合わない。
// NG: Retina scaleが掛かって2400x2400になる
let renderer = UIGraphicsImageRenderer(size: CGSize(width: 800, height: 800))
// OK: scale=1.0を明示して800x800ピクセルを保証
UIGraphicsBeginImageContextWithOptions(CGSize(width: 800, height: 800), true, 1.0)
defer { UIGraphicsEndImageContext() }UIGraphicsImageRendererにscaleを指定する方法もあるが、UIGraphicsBeginImageContextWithOptionsの方が確実。
ピクセルバイト順はBGRA
UIKitのbitmapコンテキストからピクセルデータを読むとき、バイト順はBGRA(ARM iOSの場合、kCGImageAlphaNoneSkipFirst | kCGBitmapByteOrder32Little)。RGBAだと思って読むと色が入れ替わって推論結果がめちゃくちゃになる。
let bytes = ctxData.assumingMemoryBound(to: UInt8.self)
// bytes[offset + 0] = B
// bytes[offset + 1] = G
// bytes[offset + 2] = R
// bytes[offset + 3] = A (or skip)bytesPerRowはwidth*4ではない
コンテキストのbytesPerRowがピクセル幅x4とは限らない。メモリアラインメントのためにパディングが入ることがある。行頭アドレスの計算には必ずbytesPerRowを使う。
let bytesPerRow = ctx.bytesPerRow
for row in 0..<targetSize {
let rowOffset = row * bytesPerRow // width * 4 ではなく bytesPerRow
for col in 0..<targetSize {
let pixelOffset = rowOffset + col * 4
// ...
}
}正規化の違い
DEIMv2とPARSeqで正規化が違う。混同すると精度が壊滅する。
- DEIMv2: ImageNet正規化
(pixel / 255.0 - mean) / std - PARSeq:
pixel / 127.5 - 1.0
台形補正
スマホ撮影画像の歪みはVisionフレームワークのVNDetectDocumentSegmentationRequestで書類の四隅を検出し、CIPerspectiveCorrectionで台形補正する。OpenCVなしで完結する。
縦書き回転
縦長の行画像(縦書き)は90度CCW回転してから渡す。
// .right = 「生データは90° CW回転済み」→ UIKitが90° CCW回転して表示
let rotated = UIImage(cgImage: cgImage, scale: 1.0, orientation: .right)
UIGraphicsBeginImageContextWithOptions(rotated.size, false, 1.0)
defer { UIGraphicsEndImageContext() }
rotated.draw(at: .zero)CGContext.rotate(by:)を直接使うとUIKitのy-flip座標系の影響で回転方向が直感と逆になるので、UIImage.Orientationで指定する方が安全。
文字セット(NDLmoji.yaml)のパース
NDLmoji.yamlのcharset_test: "..." から文字列を取り出して1文字ずつ配列にする処理で、SwiftのCharacter型を使うと異体字セレクタ(U+FE0E)が前の文字と結合してしまう。
// NG: Character型はgrapheme clusterを結合する
// "☆\u{FE0E}" が1文字に → 文字数が7141になる(正解は7142)
for char in charsetString { ... }
// OK: Unicode scalar単位で読む
let scalars = Array(content.unicodeScalars)
for scalar in scalars {
chars.append(String(scalar))
}文字数が1つでもずれると、PARSeqの出力テンソルの読み取り位置が全ポジションでズレてargmaxの結果が全部間違う。出力が全文字化けしたらまずcharset数を疑う。
メモリ管理
iPhoneのアプリに使えるメモリは端末RAMの半分程度。iPhone 13 Pro Max(6GB RAM)でも実質1.5GB程度。
ONNX Runtimeのセッションは展開時にモデルサイズの数倍のメモリを使う。PARSeq3モデルを全部同時にロードするとメモリを圧迫するので、遅延ロード+autoreleasepoolで対策する。
// PARSeqは使用時に遅延ロード
if parseqSessions[config.width] == nil {
parseqSessions[config.width] = try ORTSession(env: env, modelPath: path, sessionOptions: options)
}
// 各行の推論をautoreleasepoolで囲む
for box in boxes {
let result: LineResult? = try autoreleasepool {
// crop → rotate → recognize
}
}前述の通りBERT校正モデル(131MB)は不採用になった。追加モデルが不要になり、バンドルサイズ約147MBに収まっている。