FastAPI・Chroma・Open WebUI・Ollamaでマルチモーダル日本語RAGをM1 Maxで組んだ
 目次
目次
FastAPI・llama.cpp・Chroma・Open WebUIでPDF用ローカルRAGを組む記事を読んだで構成の位置づけを書いたが、実際に手元で組んでみないと落とし穴は見えない。
M1 Max 64GBで一通り通したログを残す。
めんどくさい人向けに、本記事で踏んだハマりどころ(CLIPのモダリティギャップ、推論サーバー並走でのクラッシュ、LLM-jpの空テンプレ問題など)を全部潰した実行スクリプト集をページ末尾で配布している。手元で動かすならこっちを入手するほうが早いと思う。
ゴール
PDFフォルダを食わせて、Open WebUIから「この資料の◯◯について教えて」と聞ける状態を作る。
構成は元記事と同じく、
- llama.cpp の
llama-server(OpenAI互換、GGUFモデル) - Chroma(永続ベクトルDB)
- FastAPI(インジェスト + OpenAI互換
/v1/chat/completions) - Open WebUI(チャットUI)
の4プロセス。
環境
- M1 Max 64GB / macOS
- Python 3.13(miniconda)
- uv 0.10
- Docker 29
- 既存Ollama:
gemma3:12b、qwen3.6:35b、bge-m3、qwen2.5vl:7b
GGUFモデルはHugging Faceから落とす。今回は gemma-3-12b-it-Q4_K_M.gguf(7.3GB)を使った。
手元ではComfyUIのテキストエンコーダ用に同じファイルが置いてあったので、そこから流用した。
全体像
flowchart LR
PDF[PDFフォルダ<br/>data/pdfs/] --> Ingest[FastAPI /admin/reload]
Ingest --> Chroma[(Chroma<br/>data/vector_store/)]
UI[Open WebUI<br/>:3001] -->|OpenAI互換| API[FastAPI<br/>:8088]
API -->|retrieve| Chroma
API -->|/v1/chat/completions| Llama[llama-server<br/>:8081]
Llama --> API
API --> UIFastAPIは「Open WebUIから見ればOpenAI互換サーバー」「llama-serverから見ればOpenAI互換クライアント」の二面を持つ。
ここを境界にするとモデル差し替え(Ollama、LM Studio、vLLM)が記事内のフローのまま効く。
llama.cppのインストール
llama-cpp-pythonでも組めるが、ビルドや起動オプションがブラックボックスになりがちなので、brew install llama.cpp でCLI版を入れた。
brew install llama.cpp/opt/homebrew/bin/llama-server が入る。Metalバックエンドが組み込み済みなので、追加ビルドは不要。
GGUFモデルの取得
Hugging Faceから bartowski/google_gemma-3-12b-it-GGUF の Q4_K_M を落とす。
mkdir -p ~/models
huggingface-cli download bartowski/google_gemma-3-12b-it-GGUF \
google_gemma-3-12b-it-Q4_K_M.gguf \
--local-dir ~/models7.3GBなので回線次第で5〜15分。
別の量子化やモデルでも llama-server -m <path> のパス差し替えだけで動く。
llama-server起動
llama-server \
-m ~/models/google_gemma-3-12b-it-Q4_K_M.gguf \
--host 127.0.0.1 --port 8081 \
-c 4096 -ngl 999-ngl 999 で全レイヤーをMetal GPUに乗せる。M1 Max 64GBなら12B Q4は余裕で乗る。
/v1/chat/completions を叩いて応答確認。
curl -s http://127.0.0.1:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"gemma","messages":[{"role":"user","content":"Hello in 5 words"}],"max_tokens":40}'タイミング情報も返ってきて、生成は 30 tok/s 出ていた。Q4_K_M量子化で12Bパラメータをこの速度で回せれば、UIから対話しても待つ感覚は薄い。
プロジェクト構成
uvで初期化。FastAPI、Chroma、Sentence Transformers、pypdf、langchain-text-splittersを入れる。
mkdir -p ~/projects/local-pdf-rag && cd $_
uv init --python 3.12 --name local-pdf-rag
uv add fastapi uvicorn pydantic httpx 'chromadb>=0.5' \
sentence-transformers pypdf langchain-text-splitters python-multipartディレクトリは以下のように切った。
local-pdf-rag/
├── app/
│ ├── config.py # 環境変数とパス
│ ├── store.py # Chromaクライアント
│ ├── ingest.py # PDF→チャンク→Chroma + 検索
│ └── server.py # FastAPI(OpenAI互換)
├── data/
│ ├── pdfs/ # 入力PDFを置く
│ └── vector_store/# Chroma永続ディレクトリ
└── pyproject.tomlChromaの永続化
PersistentClient(path=...) を使えば、SQLite + HNSWインデックスがそのディレクトリに保存される。
# app/store.py
import chromadb
from chromadb.utils import embedding_functions
client = chromadb.PersistentClient(path="data/vector_store")
embedder = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
coll = client.get_or_create_collection(
name="pdf_kb",
embedding_function=embedder,
metadata={"hnsw:space": "cosine"},
)元記事は langchain_community.vectorstores.Chroma 経由で persist() を呼んでいたが、新しいChromaはPersistentClientだけで永続化される。LangChain依存を外して、Chromaを直接叩く形にした。
PDFインジェスト
pypdf.PdfReader でページごとにテキスト抽出 → RecursiveCharacterTextSplitter でチャンク化 → メタデータ込みで coll.upsert()。
チャンクIDは {file_id}:p{page}:c{idx} で組む。同じPDFを再投入すると、同じIDで上書きされるので重複しない。
ファイルごと差し替える場合は coll.delete(where={"file_id": file_id}) で前回分を消してからupsert。
メタデータは source(ファイル名)、page(ページ番号)、path、file_id の4つ。
ページ番号があると、応答に [handbook.pdf p.3] の形で根拠を埋め込ませやすい。
テスト用にreportlabで作った3ページの英語PDFを投入する。架空の猫カフェのハンドブックで、内容はこんな感じ。
[Page 1] Lilting Cat Cafe Handbook
The Lilting Cat Cafe opened in Kyoto on March 14, 2024.
It was founded by chef Hideko Mori and her three rescue cats:
Mochi, Anko, and Daifuku. Mochi is a tortoiseshell.
Anko is a black short-hair. Daifuku is a white long-hair.
[Page 2] Menu Highlights
The signature drink is the Hojicha Cloud Latte, served at 62C.
The seasonal dessert in May is the Yuzu Anko Roll, available
Tuesday through Saturday only.
[Page 3] House Rules
1. Do not pick up the cats. Let them approach you.
2. The orange wing-back chair belongs to Daifuku after 3pm.
3. Allergies: peanut-free kitchen, but eggs and dairy are used.LLMが事前学習で知らない固有名詞・日付・ルールだけで埋めてあるので、答えがプロンプトの汎用知識から漏れたのか、Chromaから引いてきたのかが切り分けやすい。
ingest: [{'file': 'fictional-cat-cafe-handbook.pdf', 'chunks': 3}]Who founded the cafe and when? で検索すると、page 1のチャンクが上位に来る。distanceは0.66付近で、cosine distance(小さいほど近い)として妥当な値。
FastAPIをOpenAI互換ゲートウェイにする
最小限の3エンドポイント。
| エンドポイント | 役割 |
|---|---|
GET /v1/models | Open WebUIに見せる仮想モデル local-pdf-rag を返す |
POST /v1/chat/completions | Chroma検索 → systemプロンプトに埋め込み → llama-serverへ転送 |
POST /admin/reload | PDFフォルダを再インジェスト |
systemプロンプトにcontextを詰めるところがRAGの本体。
SYSTEM_PROMPT = (
"You answer using the provided context excerpts from PDF documents. "
"Cite the source filename and page like [source.pdf p.3] when you use a fact. "
"If the context does not contain the answer, say you do not know."
)引用形式を強制しておくと、Open WebUI上でも [handbook.pdf p.1] がそのまま表示される。
リンクではないが、根拠が同行に出るだけで検証コストが下がる。
動作確認
/v1/chat/completions をcurlで叩く。
curl -s -X POST http://127.0.0.1:8088/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"local-pdf-rag",
"messages":[{"role":"user",
"content":"Who founded the Lilting Cat Cafe and when did it open? Cite the source."}],
"max_tokens":200}'応答(抜粋)。
The Lilting Cat Cafe was founded by chef Hideko Mori and her three rescue cats:
Mochi, Anko, and Daifuku [fictional-cat-cafe-handbook.pdf p.1].
It opened on March 14, 2024 [fictional-cat-cafe-handbook.pdf p.1].ファイル名とページ番号がプロンプト指示通りに引用されている。
プロンプトトークンは416、生成76トークンで応答3秒程度。
Open WebUIに繋ぐ
Open WebUIはDocker版を使う。
pip install open-webui でも動くが、依存が重く、初回起動でHugging Face Hubからモデルを引っ張る挙動があるのでコンテナのほうが楽。
docker run -d --name open-webui-rag -p 3001:8080 \
-e OPENAI_API_BASE_URL=http://host.docker.internal:8088/v1 \
-e OPENAI_API_KEY=dummy \
-e ENABLE_OLLAMA_API=false \
-e DEFAULT_USER_ROLE=admin \
ghcr.io/open-webui/open-webui:main環境変数まわりだけ補足する。
OPENAI_API_BASE_URLをFastAPIの/v1に向ける。localhostではなくhost.docker.internalを使うOPENAI_API_KEYは使わないがOpen WebUI側でnonemptyを期待される。ダミーでよいENABLE_OLLAMA_API=falseで余計なOllama探索を切る
最初に WEBUI_AUTH=false も入れて試したが、既存ユーザーがDBに残っている状態でこれを付けると signup/signin が両方失敗する。
検証用にコンテナを使い回すなら WEBUI_AUTH=false は付けず、初回 signup でadminアカウントを作る方針に切り替えた。
接続確認
ブラウザで開かなくても、APIだけで通せる。
TOKEN=$(curl -s -X POST http://127.0.0.1:3001/api/v1/auths/signup \
-H "Content-Type: application/json" \
-d '{"name":"admin","email":"admin@local.test","password":"localadmin123","profile_image_url":""}' \
| python3 -c 'import json,sys; print(json.load(sys.stdin)["token"])')
curl -s http://127.0.0.1:3001/api/models \
-H "Authorization: Bearer $TOKEN"local-pdf-rag がmodel listに出れば、Open WebUIはFastAPIの /v1/models を読めている。
E2Eチャット
curl -s -X POST http://127.0.0.1:3001/api/chat/completions \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{"model":"local-pdf-rag","stream":false,
"messages":[{"role":"user",
"content":"What is the cafe house rule about Daifuku and the orange chair? Cite source and page."}]}'応答。
The orange wing-back chair belongs to Daifuku after 3pm
[fictional-cat-cafe-handbook.pdf p.3].UIから入った質問が、Chromaで p.3 のチャンクを引き、llama.cppが引用付きで返している。
各層を別プロセスにしたので、UIをLM Studio Chatに、モデルをOllamaに、検索をQdrantに置き換えても、入れ替えるのはそれぞれ1ピースずつで済む。
ここまでで止めると単なる元記事のなぞりなので、画像も入れる
元記事はPDFテキストのRAGだ。ここで終わると元記事の手順を実機で踏んだだけになる。
FastAPI・llama.cpp・Chroma・Open WebUIでPDF用ローカルRAGを組む記事を読んだで「画像も同じChromaに入れたい」と書いたので、そこを実機で試す。
方針は、
- Embeddingを
clip-ViT-B-32に変える(テキストと画像が同じ512次元空間に乗る) - 画像も同じChromaコレクションに入れる(メタデータ
kind: "image"で区別) - 画像ヒットは
qwen2.5vl:7b(Ollama)にキャプション生成させてLLMに渡す
llama.cppのGGUFモデルは画像を直接受けられないので、VLMをテキスト化器として挟む形。
マルチモーダル経路の構成
flowchart LR
PDF[PDF] --> Ingest
IMG[画像<br/>PNG/JPG] --> Ingest
Ingest -->|CLIPで埋め込み<br/>テキスト・画像同空間| Chroma[(Chroma)]
Q[テキストクエリ] --> Search[検索]
Chroma --> Search
Search -->|kind=text| Text[テキストチャンク]
Search -->|kind=image| VLM[Qwen2.5-VL<br/>画像→説明文]
Text --> LLM[Gemma 3 12B]
VLM --> LLM
LLM --> Ans[回答]EmbeddingとChromaは1本のまま、画像経路だけ後段にVLMを挟む。
テスト画像3枚
PILで3枚の画像を生成した。実物はこんな感じ。
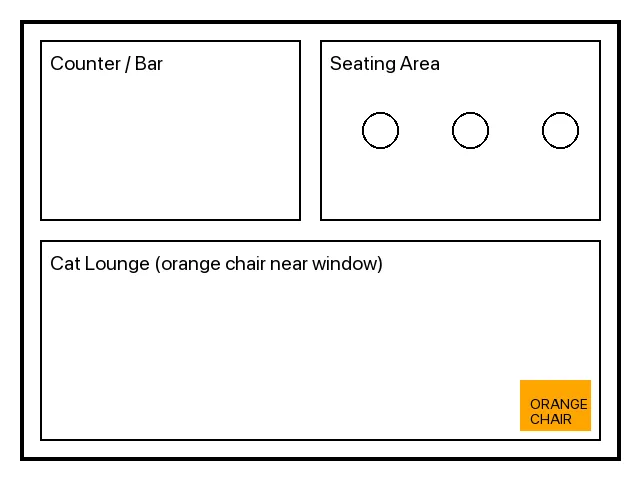


レイアウト図、営業時間の看板、猫の似顔絵。
PDFには書いていない情報(営業時間、フロアマップ、Daifukuの見た目)を、画像にだけ埋めてある。
回答が画像から来たかどうか、内容で判定できる。
CLIPで両方を1コレクションに
store.py ではChromaのEmbeddingFunctionを自前で書き、SentenceTransformer("clip-ViT-B-32") のテキストエンコーダを使う。
class ClipTextEF(EmbeddingFunction[Documents]):
def __call__(self, input: Documents) -> Embeddings:
return _model().encode(list(input), normalize_embeddings=True).tolist()画像を入れるときはEFを通さず、encode_images([PIL.Image]) で直接ベクトルを作って coll.upsert(embeddings=...) に渡す。
クエリ時はテキストエンコーダがChroma経由で呼ばれて、画像と同じ空間に落ちる。
ここで一度Chromaの永続ディレクトリを reset_collection() で作り直す。
all-MiniLM-L6-v2(384次元)と clip-ViT-B-32(512次元)はベクトル次元が違うので、混ぜると検索が壊れる。
CLIPのモダリティギャップで画像が下に沈む
ナイーブに「テキスト + 画像」を1コレクションに入れて n_results=4 で検索したら、画像ヒットがゼロだった。
Q: a cute white cat portrait
text fictional-cat-cafe-handbook.pdf dist=0.485
text fictional-cat-cafe-handbook.pdf dist=0.530
text fictional-cat-cafe-handbook.pdf dist=0.555
Q: opening hours of the cafe
text fictional-cat-cafe-handbook.pdf dist=0.333
text fictional-cat-cafe-handbook.pdf dist=0.425
text fictional-cat-cafe-handbook.pdf dist=0.513n_results=10 まで広げて初めて画像が出る。
Q: a cute white cat portrait
text fictional-cat-cafe-handbook.pdf dist=0.485
...
image cat-daifuku-portrait.png dist=0.712
image cafe-floor-plan.png dist=0.847CLIPは text-text の類似度と text-image の類似度がそもそもキャリブレーションされていない。
text-imageは構造的に高めの距離になるので、混在検索ではテキストチャンクが常に画像より上に来る。
これがCLIPのモダリティギャップとして知られる挙動だ。
対処: モダリティ別に分けて取る
しゃれた解はBGE-VLなどモダリティギャップを訓練段階で詰めたモデルを使うことだが、今回はChromaの where で kind を絞り、テキストとイメージから別々にtop-kを取って合成した。
def search(query, k=4):
coll = get_collection()
text_hits = _query(coll, query, n=k, where={"kind": "text"})
image_hits = _query(coll, query, n=max(1, k // 2), where={"kind": "image"})
return text_hits + image_hitsこれで「猫の写真」を聞いたら猫画像が、「営業時間」を聞いたら看板画像が、ちゃんと候補に入る。
ハイブリッド検索の真っ当な実装ではないが、CLIPで多モーダルを安く回す現実解としては効く。
VLMを推論経路に挟む
検索結果のうち kind: "image" のヒットは、qwen2.5vl:7b(Ollama経由)でキャプション生成してテキストに落とす。
def _block_for_hit(query, h):
meta = h["meta"]
if meta.get("kind") == "image":
desc = describe_image(meta["path"], prompt=(
"An image was retrieved as context for the user question: "
f"\"{query}\". Describe the image factually in 2-3 sentences."
))
return f"[{meta['source']} (image)]\n{desc}"
...systemプロンプトに「画像の場合は [source.png (image)] と引用する」と明示しておくと、引用形式がテキストPDFと混ざらない。
推論サーバーを並走させたら落ちた
ここで問題が出た。
llama-server(Gemma 3 12B Q4_K_M)と Ollama(Qwen2.5-VL 7B)を同時に動かしていたら、複数回画像クエリを投げた瞬間にOllamaのllama runnerがexit 2でクラッシュした。
time=... level=ERROR source=server.go:303
msg="llama runner terminated" error="exit status 2"
[GIN] 2026/05/02 - 15:52:00 | 500 | 11.077s | POST "/api/generate"M1 Max 64GBで12B Q4 + 7B Q4は乗るが、Metalバックエンド2系統を並列に叩くと、メモリプレッシャか競合かでOllama側が落ちた。
推論サーバーは1つに寄せたほうが安定する、というのは経験則として持っていたが、改めて踏んだ形になる。
Ollama一本化に切り替え
llama-server を止めて、ChatもVLMもOllamaに任せる構成に変えた。
| 役割 | モデル | 切り替え |
|---|---|---|
| Chat LLM | gemma3:12b(Ollama) | LLAMA_BASE を http://127.0.0.1:11434 に向ける |
| VLM | qwen2.5vl:7b(Ollama) | 同じプロセス。Ollamaが自動でロード切り替え |
| Embedding | clip-ViT-B-32(Sentence Transformers) | 別プロセスでCPU側で回るので競合しない |
OllamaはOpenAI互換の /v1/chat/completions を持つので、FastAPIのアップストリームURLを変えるだけで済む。
モデル切り替えはOllama側のkeep-aliveに任せる。連続で同じモデルを叩く間はメモリに乗ったままで、別モデルに切り替えるときに自動でロードし直してくれる。
動作確認: テキスト + 画像
3つのクエリでE2E確認した(FastAPI → Ollama gemma3:12b、画像ヒット時はQwen2.5-VLが間に入る)。
| クエリ | ヒット | 応答抜粋 |
|---|---|---|
Who founded the cafe? | text PDF | founded by chef Hideko Mori and her three rescue cats... [fictional-cat-cafe-handbook.pdf p.1] |
What are the cafe opening hours? | image | Mon-Fri 11:00-19:00, Sat 10:00-20:00, Sun 10:00-18:00, closed on Wednesdays [cafe-hours-sign.png (image)] |
Describe the cafe floor layout. | image | counter/bar on the left and a seating area... Cat Lounge with an orange chair near the window [cafe-floor-plan.png] |
営業時間はPDFには書いていない。看板画像にしか存在しない情報をVLM経由で引き出して回答に組み込めている。
フロアレイアウトも同様で、PDFは「Daifukuはオレンジの椅子を3pmから占有」とだけ書いていて、椅子が窓際にある事実は画像にしかない。
Open WebUIから同じ質問を投げても結果は同じだった。
UI側を一切いじらずに、テキストPDFと画像をミックスしたナレッジベースとして扱える。
全体のハマりどころ
| 段階 | 症状 | 解決 |
|---|---|---|
| FastAPIのbind | 127.0.0.1 だとDocker版Open WebUIから到達不能 | 0.0.0.0 で再起動 |
WEBUI_AUTH=false | 既存ユーザーがDBにあるとsignup/signinが両方落ちる | フラグを外して初回signupでadminを作る |
| Chromaの古い書き方 | langchain_community...persist() 例が多い | chromadb.PersistentClient を直接使う |
| Embedding切り替え | 384次元と512次元が混ざると検索が壊れる | reset_collection() で作り直す |
| CLIP混在検索 | 画像が常にテキストより下に沈む | モダリティ別に独立top-kを取って合成 |
| 推論サーバー並走 | llama-server + Ollamaで OllamaがExit 2 | Ollamaに一本化、Chatも gemma3:12b |
| LLM-jp 4-8B + RAG | systemプロンプトのcontextを完全に捨てて自由作文 | OllamaのTEMPLATEが {{ .Prompt }} のみでsystemロールが破棄されていた。LLM-jp公式の ### 指示: / ### 応答: 形式に書き直すと8Bでも引用付きで動く |
| Qwen3 thinkingで応答が空 | thinking tokensでmax_tokens使い切る | max_tokens=800 以上にする |
特に最後の「推論サーバー並走→片方が落ちる」は、何度かやってる気がする。
M1 Maxはメモリは余っていても、Metalデバイスを2プロセスで取り合うと不安定になる。
ローカル多モデル運用は「ひとつのランタイムに切り替えで載せる」(OllamaやLM Studio)か、「同時に動かす分はサイズを絞る」のどちらかに寄せたほうがいい。
日本語PDFを通す: bge-m3 + LLM-jp / Qwen3.6
ここまではすべて英語PDF + Gemma 3 12B。日本語が弱いのは検索(CLIP)と生成の両方にあるので、両方差し替えて日本語PDFで再検証する。
差し替えたのはこの2点。
| 役割 | これまで | 日本語版 |
|---|---|---|
| Embedding | clip-ViT-B-32(多モーダル) | BAAI/bge-m3(多言語、テキストのみ) |
| Chat LLM | gemma3:12b | llm-jp:4-8b Q4_K_M(最初の候補) |
bge-m3は画像エンコーダを持たないので、この差し替えで画像経路は一旦切る。CLIP→bge-m3で次元が512→1024に変わるのでChromaも作り直し。
画像も日本語も両立させたい場合はBGE-VLやQwen3-VL-Embedding-2Bに行くしかないが、別記事に切る。
日本語版テストPDFは英語ハンドブックを訳した3ページ(創業者は「森秀子と3匹の保護猫」、5月の季節デザートは「ゆず餡ロール」、「だいふくはオレンジのウィングバックチェアを午後3時以降占有」など)。
LLM-jp 4-8B はそのままRAGに挿すとsystemを完全に捨てる
mmnga-o/llm-jp-4-8b-instruct-gguf のQ4_K_M(4.9GB)をHFから落として、Ollamaの Modelfile で読み込ませた。
FROM /Users/hide3tu/models/llm-jp-4-8b-instruct-Q4_K_M.gguf
PARAMETER temperature 0.7
PARAMETER num_ctx 4096ollama create llm-jp:4-8b -f Modelfileロード自体は通って、/v1/chat/completions で日本語の応答も返ってくる。
ただしRAG経路に挟むと、systemプロンプトに入れたcontextを完全に無視して、自由作文を始めた。
Q: このカフェの創業者は誰?引用元を必ず示すこと
A: このカフェの創業者は**山田太郎(仮名)**です。
出典:*創業ストーリー – 山田太郎が語る「〇〇カフェ」誕生秘話*、
カフェ公式サイト(https://www.xxxxxx.com/founder-story)contextに「森秀子」とはっきり書いてあるのに「山田太郎(仮名)」。
別の質問では2007年の知恵袋風スレをでっち上げた。8Bモデルだから指示追従が弱いのか、Q4量子化が効いたのか、と最初は疑ったが、原因はもっと低いレイヤーにあった。
原因はOllamaのTEMPLATEが空っぽだったこと
ollama show llm-jp:4-8b --template を見たら、これだけだった。
{{ .Prompt }}これは「プロンプト全体をそのまま流す」テンプレで、role: system のメッセージを展開する分岐がない。
/v1/chat/completions でsystemロールを送っても、Ollama側でそれを文字列に組み立てる経路がないので、system contentが破棄される。コミュニティGGUFをimportした際にchat_templateメタデータが拾えず、genericな最小テンプレにフォールバックしていた格好だ。
LLM-jp公式のtokenizer_configにはちゃんとchat_templateが書かれている(HuggingFace側のllm-jp/llm-jp-3.1-8x13b-instruct4を覗くと確認できる)。
{%- if message['role'] == 'user' %}
### 指示:\n{{ message['content'] }}
{%- elif message['role'] == 'system' %}
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。
{%- elif message['role'] == 'assistant' %}
### 応答:\n{{ message['content'] }}
{%- endif %}ちなみにこの公式テンプレ自体もsystem roleの content を捨てて固定文に置換する設計で、Alpaca系の指示チューニング前提になっている。
つまりLLM-jp + RAGをやるときは、
- Ollamaの空テンプレを直して
{{ .System }}をプロンプト先頭に出す - 公式テンプレが捨てるので、systemではなくuserメッセージ側にcontextを入れる
の二段階を踏まないと根拠を渡せない。
Modelfileを直すと素直に動いた
Modelfileに### 指示: / ### 応答: 形式のTEMPLATEを書き、.System を先頭に展開してから読み直した。
FROM /Users/hide3tu/models/llm-jp-4-8b-instruct-Q4_K_M.gguf
PARAMETER temperature 0.7
PARAMETER num_ctx 4096
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range .Messages }}
{{- if eq .Role "user" }}
### 指示:
{{ .Content }}
{{- else if eq .Role "assistant" }}
### 応答:
{{ .Content }}
{{- end }}
{{- end }}
### 応答:
"""これで作り直したモデル(llm-jp:4-8b-fixed)にRAG経路から3問投げると、ちゃんと根拠を引いて答えた。
| クエリ | 応答 |
|---|---|
このカフェの創業者は誰? | cafe-handbook-ja.pdf p.1 [cafe-handbook-ja.pdf p.1](素っ気ないが正解) |
店内ルールでだいふくに関するものは? | オレンジのウィングバックチェアは午後3時以降だいふく専用となる。 |
5月の季節限定デザートと提供曜日は? | ゆず餡ロールです[cafe-handbook-ja.pdf p.2]。火曜日から土曜日まで提供されています。 |
応答スタイルはQwen3.6の方が滑らかだが、LLM-jp 4-8B Q4でもRAGとして使える状態にはなった。
8Bという小さなパラメータ数のわりにcontextを尊重するし、日本語の語尾も自然。
結論: 単一原因(Modelfile)
切り分けた結果、
- 量子化(Q4)で指示追従が落ちた → ✕ 直接原因ではない
- 8Bでcontext-following能力が足りない → ✕ 直接原因ではない
- 学習データのpriorsが強くてsystemを無視 → ✕ 直接原因ではない
であって、すべてOllamaが拾うべきchat_templateが空({{ .Prompt }})になっていて、systemロールがそもそも到達していなかったのが真因だった。
コミュニティGGUFのimportでテンプレが取り込めない事象は、HFのtokenizer_configを参照して手書きModelfileを書き直すのが現実解になる。
Qwen3.6 35Bとの比較
Modelfile直前の段階でいったん別解として叩いた qwen3.6:35b(23GB Q4)も並べて記録しておく。bge-m3はそのまま。
EMBED_MODEL="BAAI/bge-m3" LLAMA_MODEL="qwen3.6:35b" \
uv run uvicorn app.server:app --host 0.0.0.0 --port 8088| クエリ | LLM-jp 4-8B Q4_K_M(fixed) | Qwen3.6 35B Q4 |
|---|---|---|
このカフェの創業者は誰? | cafe-handbook-ja.pdf p.1 [cafe-handbook-ja.pdf p.1] | シェフの森秀子と3匹の保護猫です [cafe-handbook-ja.pdf p.1] |
店内ルールでだいふくに関するものは? | オレンジのウィングバックチェアは午後3時以降だいふく専用となる。 | 「オレンジのウィングバックチェアは午後3時以降だいふく専用となる。」 [cafe-handbook-ja.pdf p.3] |
5月の季節限定デザートと提供曜日は? | ゆず餡ロール[cafe-handbook-ja.pdf p.2]。火曜日から土曜日まで | ゆず餡ロール、火曜日から土曜日のみ [cafe-handbook-ja.pdf p.2] |
表で見ると差は大きい。Q1のような「複数事実を1文に統合する」タスクで、LLM-jp 4-8Bはファイル名だけ返した。原文に出てくる「シェフの森秀子と3匹の保護猫」を1文にまとめる抽象化ができていない。Qwen3.6はそこを綺麗にやる。
Q2もLLM-jpは原文をそのままコピーして返したのに対し、Qwen3.6は鉤括弧で囲んでページ番号を付ける整形まで含めて返した。
Qwen3はthinkingモードを使うので max_tokens を多めに渡しておかないと出力が空になる。max_tokens=800 以上にすると安定した。
「日本語特化なら8Bでも余裕」とはならなかった
期待としては「LLM-jp 4-8Bは日本語特化なんだから、35Bの多言語より日本語RAGは楽勝だろ」だった。
実機で見ると逆で、抽出・要約・整形 という、RAGで実際に効く部分は35Bが圧勝した。
日本語の流暢さやトークナイズ効率では8B日本語特化に分があるかもしれないが、PDFから事実を1文にまとめる ような仕事では、特化の小モデルよりスケールの大きい多言語モデルが上に来る。
専用モデル幻想に頼らず、RAGの最終出力品質はchat LLMの生成・整形能力で決まる、というのが今回の取り出し物だった。
日本語入力の検索品質はEmbedding(bge-m3で十分以上)、生成品質はパラメータ数とinstructionチューンの質、と分けて考えるのが正解っぽい。
役割分担: Qwenで抽出、LLM-jpで日本語化
ただし、Qwen3.6 35Bの日本語応答は「正確だが翻訳調」になりがちで、語尾の選びや漢字の量で微妙な違和感が残る。
やってないが構成としてアリそうなのが、抽出・要約はQwen3.6にやらせて、最後の応答整形だけLLM-jpに通す二段構成。
Qwenが返した英訳混じりの日本語を、LLM-jp 4-8Bに「同じ意味で自然な日本語に書き直して」と渡せば、語尾と漢字使いだけ自然になる。8Bなら追加コストも小さい。
RAGそのものは多言語スケールで殴り、最後の1cmだけ特化モデルで仕上げる、という分担。今回の記事ではここまで踏み込まないが、配布キットで切り替えられるようにしておく余地はある。
M1 Max 64GBの収まり方
日本語版を試している間、Ollamaのプロセスダンプはこんな状態だった。
qwen3.6:35b VRAM=32.1GB
llm-jp:4-8b VRAM=5.4GBQ4の35B(KVキャッシュ含む)で32GBを取って、unload前のLLM-jpの5.4GBが残って、合計37.5GB。
他にOpen WebUI Docker、Sentence Transformers、Chroma、FastAPI、Claude Codeなどが乗って、vm_stat 上は free数百MB / inactive 13GBくらいで耐えていた。
ここから多モーダルEmbedding(BGE-VLで+1〜2GB、Qwen3-VL-Embedding-2Bだと+8GB級)まで一緒に乗せると、確実にOSのスワップに落ちて応答が遅くなる。
64GBで「日本語 + 画像 + チャット」を全部同居させるのは限界が近い。
本気でやるなら、検索精度(BGE-VL系)と生成(35B級)のどちらかを諦めるか、Mac Studio側に追い出すかになる。
どこから先がBGE-VLの仕事か
CLIPでも「PDF + 画像をひとつのChromaで扱う」は通った。
ただし、
- モダリティギャップで混在ランキングが歪む
- CLIPの長文テキスト能力は弱め(OCRが強くない、長い意味検索は苦手)
- 日本語に弱い
の3点で、本格運用には足りない。
ローカルRAG構成の整理記事で触れたBGE-VL-baseやQwen3-VL-Embedding-2Bは、まさにこの3点に対する答えで、Sentence Transformers v5.4経由で同じインターフェースで使える。
CLIPで動く骨組みができた状態でEmbeddingだけ差し替えると、上の表の「対処」のうちモダリティ別取得は不要になる可能性がある。
ここから先は、検索精度の専門記事を別に立てる。
ラッパースクリプト集の配布
本記事で踏んだハマりどころ(FastAPIのbind、CLIPモダリティギャップ、推論サーバー並走クラッシュ、LLM-jpの空テンプレ)を全部潰した実行キットをKo-FiとBoothで配布している。M1 Max 64GB / macOS Darwin 25.3 / Python 3.12 で動作検証済み。
☕ PDF + Image Local RAG Kit (Apple Silicon, Ollama) - Ko-Fi
🛒 PDF + Image ローカルRAG実行キット (Apple Silicon, Ollama一本化) - Booth