See-throughでアニメ立ち絵を23レイヤーに自動分解してPSD出力した
 目次
目次
See-through は、単一のアニメキャラクター画像を入力すると、前髪・後ろ髪・顔・服・装飾などの意味的レイヤーに自動分解し、隠れていた部分をインペイント補完、PSD形式で出力するツール。SDXL ベースの LayerDiff 3D と Marigold による擬似深度推定を組み合わせた構成。
- 論文: See-through: Single-image Layer Decomposition for Anime Characters (arXiv: 2602.03749)
- 著者: Jian Lin, Chengze Li, Haoyun Qin, Kwun Wang Chan, Yanghua Jin, Hanyuan Liu, Stephen Chun Wang Choy, Xueting Liu(Saint Francis University / Spellbrush / UPenn)
- 学会: SIGGRAPH 2026 条件付き採択
- GitHub: shitagaki-lab/see-through
2026年2月にarXivで論文公開、3月末にGitHubでオープンソース化された。@ljsabcがTwitterで紹介していたが、論文著者リストには入っていない。
以前 Qwen-Image-Layeredで顔パーツ分離を試した が、あちらは元絵を入力してLoRA適用の新規画像としてレイヤー分離版を生成するアプローチ。See-throughは元絵をセグメンテーションで切り分け、隠れていた部分(髪の裏の頭、服の下の体など)をインペイント補完する。見えている部分は元絵ベース、隠れていた部分はAI生成という構成。
かなり面白いが、「1枚絵を入れたら即 Live2D 完成」ではない。「PSD叩き台自動生成機」として見るのが現実的。
何ができるか
see-through は単一のアニメキャラ画像から以下を自動で実現する:
- 意味的レイヤー分解: 前髪 / 後ろ髪 / 顔 / 目周り / 服 / 装飾 / その他身体パーツ、といった領域をRGBAレイヤーに分割
- 前後関係の推定: どのパーツが前でどれが後ろかを自動判定
- 隠蔽補完: 髪の後ろの頭部、服の下の体など、隠れていた部分をインペイント補完
- PSD 出力: 最大23レイヤー程度の意味的分解をPSD形式で書き出し
内部では SDXL ベースの LayerDiff 3D で身体部位一貫性を保ちながら、Marigold を調整したピクセルレベルの擬似深度推定と組み合わせる。相互に入り組んだ構造(重なり合う髪の毛束、髪の後ろのアクセサリー、衣類の層など)を自動で解決しようとしている。
これは Image-to-Live2D ではない
これは「自動で完全な Live2D キャラを生成する」ツールではない。
作者側も明言している通り:
Live2D には「アート的な分解の選択肢 + リギング」が必要。私たちはセグメンテーションとオクルージョン補完の自動化のみを行っています。これは多くの手作業を節約できる、しっかりとした出発点です。
つまり、PSD が出ても以下は残る:
- レイヤーの再統合・分割・命名整理
- 可動部の描き足し
- Live2D 向けの最終調整
期待しすぎないほうがいい点
面白いが制約はある。
向いている絵
- 単体キャラ
- 正面〜やや斜め
- 塗りが比較的整理されている
- 髪・服・アクセが「アニメ的文法」に沿っている
苦しくなりそうな絵
- 超複雑なフリル
- 手や小物が顔の前に大きく被る
- 極端な遠近
- 背景込みの1枚絵
- デフォルメが強すぎる / 人体構造が崩れている
- 半透明素材やエフェクトまみれ
論文の狙い自体が「人手の分解作業を減らす」であって、完全自動で商用品質保証ではない。
今日試すなら、現実的な見方
一番良い使い方は 「ベースPSD を自動で叩き台生成して、手修正する」 だ。
つまり:
- 1枚絵を入れる
- PSD を吐かせる
- そのPSD を見て
- 使えるレイヤーはそのまま採用
- ダメなレイヤーだけ修正
- Live2D 向けに再分割・調整
- 最終調整
という流れ。
逆に 厳しい期待 はこのあたり。
- これだけで即 Live2D 化
- どんな絵でも完璧
- アクセサリや髪束が毎回きれいに分かれる
- 商業案件で無検査投入
この期待は外したほうがいい。
導入面での注意
README 上では環境構築がやや重い。
README での要件例:
- Python 3.12
- PyTorch 2.8.0
- CUDA 12.8
- 用途に応じて Detectron2 / SAM2 / mmcv / mmdet など追加依存
Windows の素の環境だと詰まりやすい部類。最初から本命絵を突っ込まない。髪・顔・服がはっきり分かれた単体立ち絵で確認したほうがいい。
メインスクリプトは:
python inference/scripts/inference_psd.py \
--srcp assets/test_image.png \
--save_to_psd実運用のおすすめ
見るべき評価基準。
- 前髪と後ろ髪が分かれているか
- 顔周りの隠れ部分が破綻していないか
- 服の前後関係が自然か
- PSD で開いたとき修正コストが「手作業ゼロではないが十分減る」レベルか
最初は「人力分解の3時間が1時間になるか」くらいの観点で見たほうが正しい。
ComfyUI 方面
jtydhr88氏(Terry Jia)が ComfyUI-See-through というサードパーティのラッパーを公開している。論文著者チーム(shitagaki-lab)とは別の開発者で、ComfyUIエコシステムに40個以上のプラグインを出している人。本家リポジトリのissue#1でComfyUI対応を報告済み。ComfyUI に寄せて試したいならそっち経由のほうが扱いやすい可能性がある。ただし研究実装本体より安定性が下がる可能性があるので、まず本家で一回結果を見て、その後 ComfyUI 化するほうが安全。
入力画像
今回使う入力画像。1280x1280、透過背景のPNG。

RunPod × RTX PRO 6000 での導入
使用モデル
See-through は HuggingFace から3つのモデルをダウンロードして使う。
| モデル | HuggingFace | サイズ | 用途 |
|---|---|---|---|
| LayerDiff 3D | layerdifforg/seethroughv0.0.2_layerdiff3d | 9.5GB | SDXLベースの透過レイヤー生成 |
| Marigold Depth | 24yearsold/seethroughv0.0.1_marigold | 3.1GB | アニメ向け擬似深度推定 |
| SAM Body Parsing | 24yearsold/l2d_sam_iter2 | 1.3GB | 19パーツのセマンティックセグメンテーション |
合計約14GB。リポジトリ含めて15GB程度。
DC選定
GPU Pod建てた後にVRAM不足で別GPUに切り替える可能性を考え、複数GPUの在庫があるDCを選ぶ。Network Volumeは同一DC内のPodにしかアタッチできないため。
今回は EUR-IS-1 を選択(RTX PRO 6000: Mid、RTX 5090: Low)。
Step 1: Network Volume + CPU Pod でモデル事前ダウンロード
Qwen-Image-Layeredのときと同じ「CPU Podで事前DL → Network Volume → GPU Pod」パターン。GPU課金中にダウンロード待ちするのは無駄。
Network Volume は 50GB で作成。モデル合計15GBなので十分余裕がある。
CPU Pod($0.06/h)にNetwork Volumeをアタッチし、以下を実行:
cd /workspace
git clone https://github.com/shitagaki-lab/see-through.git
pip install huggingface_hubモデルダウンロードはスクリプトファイルに書いてnohupで実行。Web Terminalは切断されるとプロセスが死ぬので直接実行は避ける。
cat << 'EOF' > /workspace/dl.py
from huggingface_hub import snapshot_download
snapshot_download('layerdifforg/seethroughv0.0.2_layerdiff3d', local_dir='/workspace/models/layerdiff3d')
snapshot_download('24yearsold/seethroughv0.0.1_marigold', local_dir='/workspace/models/marigold')
snapshot_download('24yearsold/l2d_sam_iter2', local_dir='/workspace/models/sam_body')
print('ALL DONE')
EOF
nohup python3 /workspace/dl.py > /workspace/download.log 2>&1 &進捗は tail -20 /workspace/download.log で確認。ALL DONE が出たらCPU PodをTerminate。
Step 2: GPU Pod 作成
| 項目 | 設定 |
|---|---|
| GPU | RTX PRO 6000(96GB) |
| DC | EUR-IS-1 |
| テンプレート | Runpod Pytorch 2.8.0(runpod/pytorch:1.0.2-cu1281-torch280-ubuntu2404) |
| Network Volume | Step 1で作ったもの |
| Volume Disk | 0GB(Network Volumeのみ) |
RTX 5090(32GB)で行きたかったが在庫なし。RTX PRO 6000は$2前後/hで予算的にはきついが、96GB VRAMでメモリの心配はゼロ。
Step 3: 環境構築
テンプレートにPython 3.12 + PyTorch 2.8.0+cu128が入っているので、PyTorchの再インストールは不要。ただしUbuntu 24.04はPEP 668でシステムPythonへの直接pipを禁止しているので、venvを作る。--system-site-packages でテンプレートのPyTorchを引き継ぐ。
python3 -m venv /workspace/venv --system-site-packages
source /workspace/venv/bin/activate
cd /workspace/see-through
pip install -r requirements.txt依存インストールは約2分で完了。
Step 4: 推論実行
source /workspace/venv/bin/activate
cd /workspace/see-through
python inference/scripts/inference_psd.py \
--srcp /workspace/input/kanachan_1280.png \
--save_to_psd \
--save_dir /workspace/output \
--repo_id_layerdiff /workspace/models/layerdiff3d \
--repo_id_depth /workspace/models/marigold--repo_id_layerdiff と --repo_id_depth でローカルのモデルパスを指定。指定しないとHuggingFaceからダウンロードしようとする。
実行時間とコスト
| 工程 | 時間 | コスト |
|---|---|---|
| CPU Pod: モデルDL | 約1分 | ~$0.00 |
| GPU Pod: 環境構築 | 約2分 | ~$0.07 |
| GPU Pod: モデルロード | 約1分 | ~$0.03 |
| GPU Pod: 推論 | 2分5秒 | ~$0.07 |
| 合計 | 約6分 | ~$0.17 + NV月額 |
Network Volume 50GBの月額が$3.50。使い終わったら削除すれば課金停止。
実行結果
23パーツに分解されたPSD(7.9MB)が出力された。
再構成画像
レイヤーを全部重ねた再構成結果。元絵とほぼ一致している。

分解されたパーツ一覧
| パーツ | 内容 | 評価 |
|---|---|---|
| front hair | 前髪 + アホ毛 | きれいに分離 |
| back hair | 後ろ髪 | サイドポニーがback hairに一体化。独立パーツとしての分離なし |
| face | 顔の肌 | 良好 |
| eyebrow / eyelash / eyewhite / irides | 目周り4パーツ | 細かく分かれている |
| mouth / nose | 口・鼻 | 良好 |
| ears / earwear | 耳・イヤリング | 良好 |
| headwear | 頭の装飾(シュシュ) | 取れている |
| neckwear | ネクタイ | 良好 |
| topwear | シャツ(胴体部分) | 袖はhandwearに分離 |
| handwear | 袖 + 手 | きれいに分離 |
| bottomwear | スカート | 良好 |
| legwear | タイツ | 良好(黒タイツなので透過表示だと見えにくいが実際は下まである) |
| footwear | 靴 | 良好 |
| neck | 首 | 良好 |
| head | 頭部全体(補完用) | インペイント済み |
| tail | 尻尾(獣耳キャラ用) | 該当なし(空レイヤー) |
| wings | 翼(天使・悪魔キャラ用) | 該当なし(空レイヤー) |
| objects | 小物 | 該当なし(空レイヤー) |
tail / wings / objects はキャラの属性に応じたパーツ。今回の立ち絵には尻尾も翼もないので空レイヤーになっている。獣耳キャラや翼付きキャラならここにパーツが入る。
主要レイヤーの出力例
前髪(アホ毛含む、きれいに分離):

後ろ髪(サイドポニーはback hairに一体化、個別分離なし):

顔(肌のみ。目・眉・口・鼻は別レイヤー):
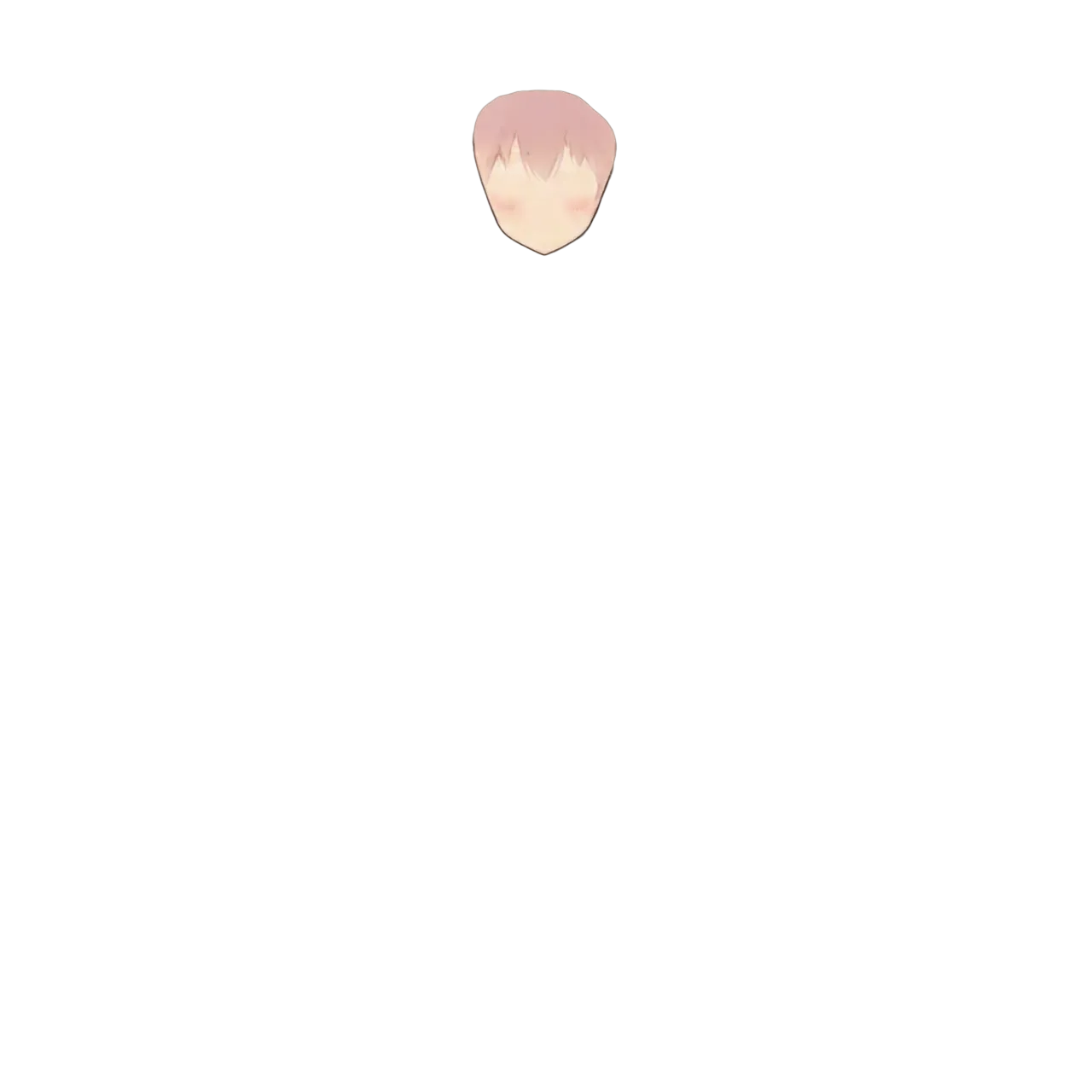
眉:

虹彩:

口:

Live2Dで表情を動かすには目・眉・口が独立レイヤーであることが必須。See-throughは顔を face / eyebrow / eyelash / eyewhite / irides / mouth / nose の7パーツに分割しており、Qwen-Image-Layeredの3分割(顔パーツ / 土台 / 髪)よりはるかに細かい。Qwen-Image-Layeredではface_partsから目・口・眉を個別に切り出す作業が追加で必要だったが、See-throughでは最初から分かれている。
シャツ(袖はhandwearに分離されている):

袖 + 手:

タイツ(黒タイツは透過表示だと背景に溶ける。白背景で見ると下まできっちりある):

靴:

深度マップ(depth)
各パーツにはdepth画像も同時に出力される。別途 kanachan_1280_depth.psd としてまとまったPSDも出る。

黒が手前、白が奥を表すグレースケールの奥行き情報。See-throughの内部ではMarigoldベースの擬似深度推定で生成され、レイヤーの前後順序を決めるために使われている。
Live2Dだけが目的なら直接は使わないが、以下の用途がある:
- パララックス効果: カメラを動かしたときに手前のパーツを大きく、奥を小さく動かす2.5D演出。After Effectsやblenderで深度マップをDisplacementに使える
- レイヤー順序の参照: PSDのレイヤー順序が正しいか判断するときの根拠
- 被写界深度演出: 奥にあるパーツほどぼかしを強くする
問題点
サイドポニーが独立パーツとして分離されない: サイドポニーはback hairレイヤーに含まれているが、後ろ髪と一体化しており個別パーツとして切り出されていない。19パーツのボディセグメンテーション定義に「ポニーテール」カテゴリが存在しないため、ポニテを独立要素として分離するデータ構造自体がない。headwearにはシュシュだけ入っている。
また、パイプラインの中間出力であるsrc_head.png(頭部クロップ)ではポニーテールが途中で切れている。

頭部領域の判定がポニーテールを頭部の一部として扱っておらず、クロップの範囲外に出ている部分が切り落とされている。back hairとしてのセグメンテーションは行われているが、頭部クロップ起点の処理ではポニテが考慮されていない。
PSDにfootwearレイヤーがない: 個別ファイル(footwear.png)としては靴が出力されており、info.jsonにもfootwearは含まれている。しかしPSDを開くとfootwearレイヤーが存在しない。PSD書き出し時に何らかの条件でフィルタされている模様。靴が必要な場合は個別PNGから手動でPSDに追加する必要がある。
足が切れて見える(実際は切れていない): 黒タイツのlegwearレイヤーは透過背景で表示すると背景と溶けて足が消えたように見える。白背景に重ねると下まできっちり分離されていた。PSDで確認するときは背景色に注意。
評価
顔パーツの細分化(眉・睫毛・白目・虹彩の4分割)はQwen-Image-Layeredより細かい。服・髪・顔の前後関係も自然で、隠れていた部分のインペイント補完もそれなりに機能している。
ただしポニーテールのように「独立パーツとして分離してほしいが、データ構造上カテゴリがない」ケースには対応できていない。
これをLive2Dで使えるようにできるのか
ゼロからPSDを作るよりは格段に楽。ただし「そのままLive2Dに突っ込む」のは無理。
そのまま使える部分:
- 顔パーツ7分割(face / eyebrow / eyelash / eyewhite / irides / mouth / nose)→ Live2Dの表情制御に直結
- 隠れ部分のインペイント補完 → パーツを動かしても穴が開かない
- 服・髪・顔の前後関係 → レイヤー順序がそのまま使える
手修正が残る部分:
- サイドポニーの手動分離(back hairに一体化しているため)
- footwearのPSD手動追加(個別PNGは出力されている)
- レイヤー境界の微調整(にじみ・ぼけの処理)
- Live2D用のメッシュ割り・可動範囲の設計(これはどの手法でも残る作業)
Qwen-Image-Layeredのときは「3分割からさらに目・口・眉の個別切り出しが必要」だったのに対して、See-throughは「最初から細かく分かれてるけど、定義外のパーツ分離には対応できない」という別方向の問題。アプローチも違う(Qwen-Image-Layeredは生成時に分離、See-throughは既存絵を後から分解)ので、手持ちの絵を活かしたいならSee-through、生成絵の分離ならQwen-Image-Layeredという棲み分けになる。
ポニーテール問題の考察
これはSAMの認識精度の問題ではなく、データ構造の問題。19パーツのボディセグメンテーション定義にfront hair / back hairはあるが「ポニーテール」カテゴリがない。サイドポニーはback hairとして認識されてはいるが、後ろ髪と一体化したまま出力される。ポニテだけ切り出したい場合は手動で分離するしかない。
加えて、頭部クロップの段階でポニーテールが切れている。頭部領域の判定がポニテを頭の一部として扱っていないため、クロップ範囲外に出ている部分が失われる。セグメンテーションの問題と頭部クロップの問題、2つが重なっている形。
複合技の可能性
See-throughで全身を分解し、顔の表情差分だけQwen-Image-Layeredで作るという複合技も考えられる。Qwen-Image-Layeredはプロンプトで表情を指定して顔パーツ/土台/髪の3分割を生成できるので、目の開閉や口の開閉といった表情バリエーションの生成に向いている。
- See-through: 手持ちの1枚絵 → 全身23パーツ分解 → Live2Dの基本構造
- Qwen-Image-Layered: 顔だけ表情差分を生成 → 目閉じ・口開きなどのバリエーション
ただしQwen-Image-LayeredはBF16で約40GB、推論に75秒/枚(resolution=640)〜240秒/枚(resolution=1024)かかる。See-throughの推論2分5秒(全身23パーツ)と比べると、顔だけなのにかなり重い。
この速度差はアプローチの違いから来ている。Qwen-Image-Layeredは40GBの生成モデルで画像を丸ごと新規生成するので、1枚出すたびにフル推論が走る。See-throughは既存の絵をセグメンテーションで切り分けて、隠れていた部分だけインペイントするので、全体を生成し直す必要がない。「全部生成」vs「必要な部分だけ補完」の差がそのまま処理時間に出ている。
両方を1つのPodで動かすのは無理ではないが、RTX PRO 6000(96GB)でも同時ロードは厳しい。順番に使う形になる。
今回は真顔の立ち絵で試したが、Live2Dで本気で使うなら入力画像は微笑んで少し口を開けた表情のほうがいい気がする。口が真一文字だとLive2Dで口の動きをつけるときにパーツの当てが効きにくい。