RTX 4060 Laptop(8GB)でComfyUI + WAI-Illustriousを動かす
 目次
目次
SDXL系のWAI-Illustriousを手元のノートPC(RTX 4060 Laptop / VRAM 8GB)で動かしてみた。8GBだとギリギリかと思ったが、LoRA併用でもlowvramオプションなしで1024x1024が普通に生成できた。
環境
| 項目 | スペック |
|---|---|
| GPU | NVIDIA GeForce RTX 4060 Laptop(VRAM 8GB) |
| OS | Windows 11 Home |
| ドライバ | 576.02 |
| CUDA | 12.9 |
| ComfyUI | v0.15.0(ポータブル版、CUDA 12.8ビルド) |
| モデル | WAI-Illustrious SDXL v16.0(6.5GB) |
セットアップ
ComfyUI ReleasesからNVIDIA CUDA 12.8版(ComfyUI_windows_portable_nvidia_cu128.7z)をダウンロードして展開。CUDA 12.9環境だが12.8版で問題なく動く。
展開先は C:\works\ComfyUI_windows_portable\。パスにスペースや日本語を含めない。
チェックポイントはCivitaiからv16.0(waiIllustriousSDXL_v160.safetensors、6.5GB)をダウンロードして ComfyUI\models\checkpoints\ に配置。
run_nvidia_gpu.bat はカレントディレクトリが ComfyUI_windows_portable\ でないと動かない(中身が相対パス)。エクスプローラーからダブルクリックするか、cdしてから実行する。
ワークフロー
基本構成。チェックポイントローダー → CLIPテキストエンコーダー → KSampler → VAEデコード → 保存。
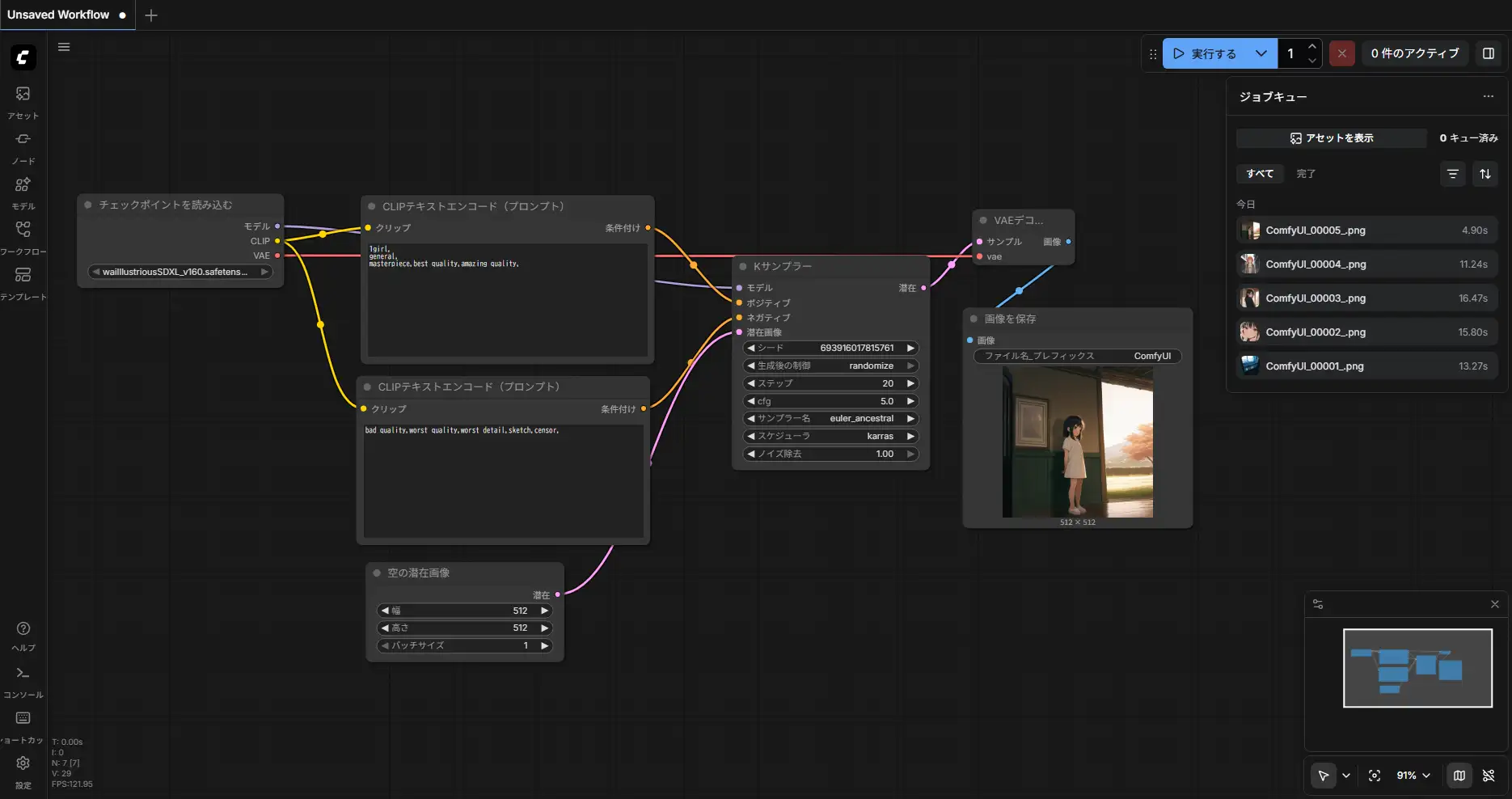
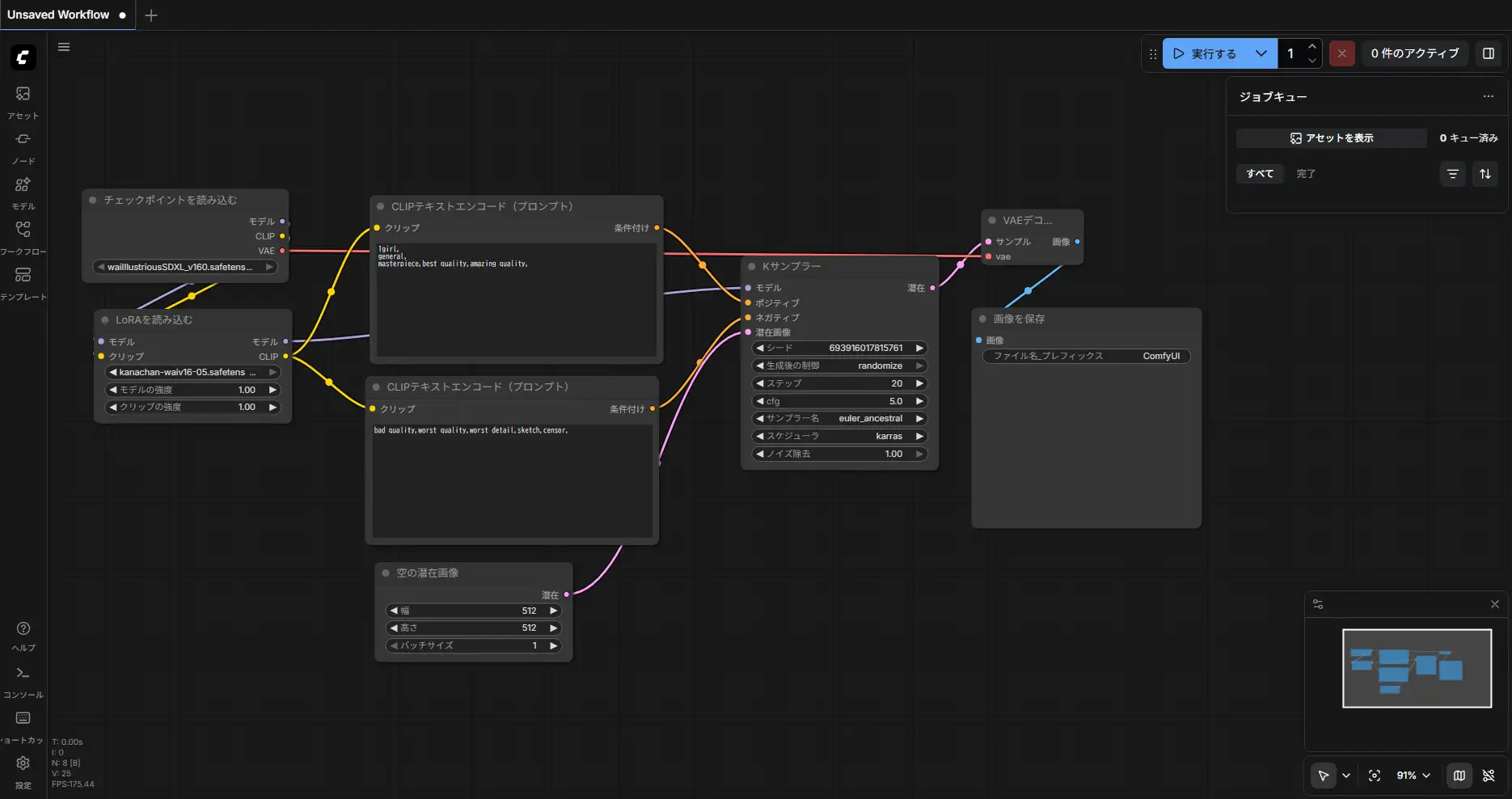
LoRA併用時はチェックポイントローダーとCLIPエンコーダーの間にLoRAローダーを挟む。MODELとCLIP両方にLoRAを適用する構成。
ベンチマーク
共通設定: euler_ancestral / Karrasスケジューラ / CFG 5 / 20ステップ / デノイズ 1.0
ポジティブ: 1girl, general, masterpiece, best quality, amazing quality,
ネガティブ: bad quality, worst quality, worst detail, sketch, censor,
チェックポイントのみ
| 解像度 | it/s | KSampler | トータル | VRAMピーク |
|---|---|---|---|---|
| 512x512 | 5.90 | 3秒 | 4.90秒 | ~4.9GB |
| 768x768 | 2.45 | 8秒 | 11.24秒 | ~4.9GB |
| 1024x1024 | 1.47 | 13秒 | 15.81秒 | ~5.6GB |
全解像度で full load: True(モデル全体がVRAMに載った状態)。--lowvram は不要だった。
1024x1024:


768x768:

512x512:

LoRA併用
| 解像度 | it/s | トータル | LoRAなし |
|---|---|---|---|
| 512x512 | 5.83 | 5.98秒 | 4.90秒 |
| 768x768 | 2.82 | 7.99秒 | 11.24秒 |
| 1024x1024 | 1.63 | 15.62秒 | 15.81秒 |
LoRA初回ロード時は512x512で10.37秒かかったが、キャッシュ済みなら5.98秒。KSamplerのit/s自体はほぼ変わらず、LoRAのオーバーヘッドは微小。



キャラLoRAの生成結果
自作キャラクターLoRAを適用して生成。キャラの特徴がしっかり反映されている。
20ステップ:

25ステップ:

25ステップのほうが線の造形が安定して、指の描写も崩れにくい。
M1 Maxとの比較
参考までに、M1 Max(MPS backend)だと同条件の1024x1024で約40秒かかる。CUDA最適化の恩恵でRTX 4060 Laptopのほうが2.5倍速い。
VRAMの使われ方
アイドル時(ComfyUI起動直後)は91MiB。モデルは生成リクエストが来たタイミングで初めてVRAMにロードされる。
生成中に最もVRAMを消費するのはKSampler。ステップごとにUNetのフォワードパスを回すため、SDXL系のUNet(約4.9GB)がVRAMを占有する。CLIPテキストエンコードは一瞬で終わり、VAEデコードも1回だけ。
生成後の自動アンロード
生成が終わるとComfyUIのメモリマネージャがUNetの重みをVRAMからシステムRAMに退避させる。1024x1024の場合、約3GBが解放されて1.8GBだけVRAMに残る。
Unloaded partially: 3056.88 MB freed, 1840.21 MB remains loadedこれは意図的な動作で、8GB環境ではありがたい。理由:
- 次の処理に備える: VAEデコードやLoRAパッチ適用など、別の処理用にVRAMを空けておく
- VRAM断片化の防止: 載せっぱなしだと断片化して大きい連続メモリが確保できなくなる
- WDDM環境: Laptop GPUはディスプレイ出力とVRAMを共有しているので、占有しすぎるとシステムが不安定になる
退避先はディスクではなくシステムRAM。次の生成時はRAM→VRAMの転送だけで済むので、初回ロード(ディスク→VRAM)より速い。--disable-smart-memory で常駐させることもできるが、8GB環境では使わないほうがいい。
8GBで足りるのか
WAI-Illustrious単体でもLoRA併用でも余裕だった。当初は「SDXLのUNetが6.5GBだから8GBギリギリ」と思っていたが、実測ではピーク5.6GBに収まった。fp16での推論とComfyUIのメモリ管理が効いている。
VRAM不足になりそうなケース:
- ControlNet併用: ControlNetモデル(1〜2GB)が追加で載る
- 複数LoRA同時適用: LoRAは軽いが積み重なると効く
- 高解像度アップスケール: 2048x2048以上はVAEデコードでスパイクが起きやすい
その場合は --lowvram で起動すればOOM回避できるが、UNetのパーツをCPU⇔GPU間でスワップするため速度は落ちる。
今までM1 Maxで小さめに生成→シード固定でHires拡大→FaceDetailerで顔を修正、みたいなワークフローでやってたけど、RTX 4060 Laptopだと1024x1024を直接生成しても15秒で終わる。M1 Maxだと同じ条件で40秒。CUDA環境のほうがComfyUIのカスタムノードや最新の最適化もフルに使えるし、mps backendの対応待ちもない。
マシンの価格差は約10万円。画像生成用途だけで見たらRTX 4060 Laptop搭載のWindowsノートのコスパがいい。