Qwen-Image-LayeredでLive2D用の顔パーツ分離をRunPodで試す
 目次
目次
2026-04-29 追記: 別モデル(See-through)で同じ目的の全身23パーツ分解を試した記事も書いた → See-throughでアニメ立ち絵を23レイヤーに自動分解してPSD出力した
AI生成イラストのキャラにLive2D的な動きをつけたい。顔を動かすにはパーツごとに分離したレイヤーが必要になる。Qwen-Image-Layeredとtori29umai氏のLoRAを使えば自動で顔パーツを分離できるらしい。以前構成を調べたので、今回はRTX PRO 6000(96GB)で実際に動かす。
Qwen-Image-Layeredとは
Alibabaが公開した画像生成モデルで、透過レイヤーを直接生成できる。通常の画像生成は1枚絵だが、このモデルはパーツごとに分離されたレイヤーを出力する。
tori29umai氏の顔パーツ分離LoRAを組み合わせると、以下の3レイヤーが出力される。
- レイヤー1: 顔パーツ(目、口、鼻)
- レイヤー2: 顔土台(顔パーツと髪を除いた部分)
- レイヤー3: 髪のみ
参考:
Live2Dのパーツ分けとの対応
Live2Dで顔を動かすには、最低限以下のパーツが独立したレイヤーとして必要になる。
| Live2Dパーツ | LoRA出力との対応 |
|---|---|
| 左目・右目 | レイヤー1(顔パーツ)に含まれる → 個別に切り出す |
| 眉 | レイヤー1に含まれる → 個別に切り出す |
| 口 | レイヤー1に含まれる → 個別に切り出す |
| 鼻 | レイヤー1に含まれる |
| 顔の輪郭・肌 | レイヤー2(顔土台) |
| 前髪 | レイヤー3(髪)→ 前後の分離は手動 |
| 後ろ髪 | レイヤー3(髪)→ 前後の分離は手動 |
LoRAの出力は「顔パーツ」「土台」「髪」の3分割。Live2Dで実際に使うには、レイヤー1から目・口・眉を個別に切り出す作業が追加で必要になる。ただし透過PNGで出力されるので、パーツの境界が明確で切り出しやすい。
表情差分の作り方
パーツ分離だけでは差分にならない。表情バリエーション(目閉じ、口開き等)が別途必要。流れはこう:
- Qwen-Image-Edit等で表情を変えた画像を用意する
- 各バリエーションをLayered+LoRAでパーツ分離
- 土台(レイヤー2)は共通で、顔パーツ(レイヤー1)だけ差し替え
土台を1枚固定して顔パーツだけ入れ替える構造なので、位置ズレが最大のリスク。同じ顔クロップ・同じ構図の入力なら大きくはズレないはずだが、実測が必要。
バリエーション画像が手元にあるなら、Network VolumeにS3 APIで事前に放り込んでおいて、GPU Pod起動後にdiffusersのバッチスクリプトで一気に処理する。実際に28枚を連続処理して75秒/枚(steps=50, resolution=640)で安定動作した。
tori29umai氏やLoRAユーザーが表情差分の作成まで公開している事例は2026年3月時点では見つからない。パーツ分離ツールとしての利用が主で、差分ワークフローの確立はこれからの領域。
元画像の要件
今回使う入力画像はこれ。白背景・顔クロップ・正面・アニメ絵で、条件を満たしている。

tori29umai氏のLoRAには明確な入力条件がある。
| 条件 | 内容 |
|---|---|
| 背景 | 白背景(必須) |
| 構図 | 顔回りでトリミング(全身NG) |
| 解像度 | 1024x1024推奨(学習解像度に合わせる) |
| 向き | 正面〜やや斜めが無難(横顔は未検証) |
| 画風 | アニメ/イラスト系で最も良い結果が期待できる |
| プロンプト | 英語で画像内容を自然言語で記述 |
全身画像や背景ありの画像を入れると分離品質が落ちる。入力前に白背景・顔クロップに加工しておく。
GPU選択: なぜRTX PRO 6000(96GB)か
前回の調査ではRTX 6000 Ada(48GB)を推奨していたが、実際にLoRAを載せて回すなら96GBのほうが安全。
| 構成 | VRAM使用量(概算) |
|---|---|
| BF16ベースモデル | 40GB |
| VAE + Text Encoder | 数GB |
| LoRA | 数百MB〜 |
| ComfyUIオーバーヘッド | 数GB |
| 合計 | 45GB前後 |
48GBだとギリギリで、ワークフロー途中のOOMリスクがある。96GBなら半分も使わないので、バッチ処理やLoRAの切り替えも余裕。
| GPU | VRAM | 料金目安 | 判定 |
|---|---|---|---|
| RTX 6000 Ada | 48GB | 0.8〜1.2ドル/h | ギリギリ |
| RTX PRO 6000 | 96GB | 1.5〜2.0ドル/h | 余裕、こちらを使う |
料金差は1時間あたり100円程度。OOMで試行錯誤する時間を考えたらこっちのほうがトータルで安い。
LoRAバージョン選択
HuggingFaceに2つのバリアントがある:
| ファイル | サイズ | 特徴 |
|---|---|---|
QIL_face_parts_V3_dim16_1e-3-000056.safetensors | 295MB | 標準版、note記事で配布 |
QIL_face_parts_V3_dim4_1e-3_remove_first_image-000060.safetensors | 74MB | 軽量版、元画像除外学習 |
VRAMに余裕があるのでdim16版を使う。dim4版は軽量だが品質差が不明なので、まずは標準版から。
ダウンロード元: tori29umai/Qwen-Image-Layered
Network Volumeでモデルを永続化
Pod付属のVolume DiskだとPodを削除したらモデルも消える。Network Volumeなら独立して保持されるので、Podを作り直しても再ダウンロード不要。
| Volume Disk | Network Volume | |
|---|---|---|
| Podを削除したら | 消える | 残る |
| 別Podに付け替え | 不可 | 可能 |
| Pod外からアップロード | 不可 | S3 APIで可能 |
| 料金 | Pod料金に含まれる | 0.07ドル/GB/月 |
サイズは後から増やせる(減らせない)。diffusers形式のモデルは合計約57.7GBあり(ComfyUI形式の約48GBより大きい。Text Encoderがfp8ではなくbf16フル精度のため)、ファイルシステムのオーバーヘッドも考慮すると60GBでは入らない。100GB推奨。LoRA・入力画像・出力画像も置くので余裕が必要。
| 形式 | ベースモデル | Text Encoder | 合計 |
|---|---|---|---|
| ComfyUI(split files) | 40GB | fp8: 8.74GB | ~48GB |
| diffusers(from_pretrained) | 40GB | bf16: ~14GB | ~57.7GB |
料金目安: 100GBで月7ドル(約1,050円)。使わなくなったら削除すれば課金停止。
作成
RunPod → Storage → + Network Volume → DC選択 → 100GB → 作成。
DCはS3 API対応のもの(US-KS-2, US-CA-2, EU-RO-1等)を選ぶと、後からPodなしでファイル操作できる。対応DC一覧は公式ドキュメントを参照。
S3 APIで事前にファイルを入れる
GPU Podを起動せずにNetwork Volumeへファイルをアップロードできる。LoRAや表情バリエーション画像の事前配置に使える。
セットアップ
- RunPod → Settings → S3 API Keys → 新規作成
- Access Key(
user_***)とSecret(rps_***)を控える aws configureでキーを設定
アップロード
# Network Volume上のパスはPodの /workspace/ に対応
aws s3 cp local-file.safetensors \
s3://VOLUME_ID/ComfyUI/models/loras/ \
--endpoint-url https://s3api-us-ks-2.runpod.io/ \
--region us-ks-2500MB超は自動でマルチパートアップロードになる。
40GBのベースモデルをローカルから上げるのは回線次第でかなりかかる。大きいファイルはCPU Podで落とすほうが速い(後述)。S3 APIはLoRAや画像など小〜中サイズのファイル向き。
CPU Podでモデルを事前ダウンロード
GPU Pod上でモデルをダウンロードすると1.5〜2.0ドル/hの課金が無駄にかかる。テンプレートの自動セットアップがコケたときにGPU課金中でデバッグするのも最悪。
安いCPU PodにNetwork Volumeをアタッチして、先にモデルを全部入れておく。
- RunPod → Pods → + Deploy
- CPU Pod → 最安の0.06ドル/h(2 vCPU / 4GB RAM)で十分
- Network Volume: 作成済みのものを選択
- Deploy
Web Terminalで実行:
# ディレクトリ作成
mkdir -p /workspace/ComfyUI/models/diffusion_models
mkdir -p /workspace/ComfyUI/models/vae
mkdir -p /workspace/ComfyUI/models/text_encoders
mkdir -p /workspace/ComfyUI/models/loras
# ベースモデル BF16(約40GB)
cd /workspace/ComfyUI/models/diffusion_models
wget https://huggingface.co/Comfy-Org/Qwen-Image-Layered_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_layered_bf16.safetensors
# VAE
cd /workspace/ComfyUI/models/vae
wget https://huggingface.co/Comfy-Org/Qwen-Image-Layered_ComfyUI/resolve/main/split_files/vae/qwen_image_layered_vae.safetensors
# Text Encoder
cd /workspace/ComfyUI/models/text_encoders
wget https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors
# LoRA(tori29umai版 dim16)
cd /workspace/ComfyUI/models/loras
wget https://huggingface.co/tori29umai/Qwen-Image-Layered/resolve/main/QIL_face_parts_V3_dim16_1e-3-000056.safetensors実測ではベースモデル40GBが約12分、全モデルで15分程度で完了した。0.06ドル/hなので全部で2円くらい。
ダウンロード完了したらCPU PodはTerminate。モデルはNetwork Volumeに残る。
ComfyUIはBlackwellで動かない
RTX PRO 6000はBlackwellアーキテクチャ(sm_120)。ComfyUI経由でQwen-Image-Layeredを動かすと、VAEデコード時にNaN(非数)が発生し、出力が透明画像になる。Blackwell Edition テンプレート(runpod/comfyui:latest-5090)でも同じ。--force-fp32や--fp32-vaeでも解決しない。
原因はComfyUI側のBlackwell対応の問題で、GPU自体は正常。同じRTX PRO 6000でdiffusersのPythonパイプラインを使えば問題なく動く(Redditでも複数の動作報告あり)。
diffusersで実行する
ComfyUIの代わりにHuggingFaceのdiffusersライブラリを使う。QwenImageLayeredPipelineがQwen-Image-Layeredに対応している。
1. モデルのダウンロード(CPU Pod)
GPU Podでダウンロードすると課金が無駄になるので、CPU Pod($0.06/h)でNetwork Volumeに入れておく。
diffusers形式のモデルはComfyUI形式と異なり、Text Encoderがbf16フル精度(約14GB)になるため合計サイズが大きい。snapshot_downloadはCPU Podのメモリ(4GB)では動かないため、wgetで直接落とす。
mkdir -p /workspace/models/Qwen-Image-Layered/{transformer,text_encoder,vae,scheduler,tokenizer,processor}
cd /workspace/models/Qwen-Image-Layered
BASE=https://huggingface.co/Qwen/Qwen-Image-Layered/resolve/main
# config類(小さいファイル)
wget -q $BASE/model_index.json
wget -q $BASE/transformer/config.json -P transformer/
wget -q $BASE/transformer/diffusion_pytorch_model.safetensors.index.json -P transformer/
wget -q $BASE/text_encoder/config.json -P text_encoder/
wget -q $BASE/text_encoder/generation_config.json -P text_encoder/
wget -q $BASE/text_encoder/model.safetensors.index.json -P text_encoder/
wget -q $BASE/vae/config.json -P vae/
wget -q $BASE/scheduler/scheduler_config.json -P scheduler/
# tokenizer / processor(省略、同じ要領でwget)
# transformer(5シャード、合計約41GB)
wget $BASE/transformer/diffusion_pytorch_model-00001-of-00005.safetensors -P transformer/
wget $BASE/transformer/diffusion_pytorch_model-00002-of-00005.safetensors -P transformer/
wget $BASE/transformer/diffusion_pytorch_model-00003-of-00005.safetensors -P transformer/
wget $BASE/transformer/diffusion_pytorch_model-00004-of-00005.safetensors -P transformer/
wget $BASE/transformer/diffusion_pytorch_model-00005-of-00005.safetensors -P transformer/
# text_encoder(4シャード、合計約17GB)
wget $BASE/text_encoder/model-00001-of-00004.safetensors -P text_encoder/
wget $BASE/text_encoder/model-00002-of-00004.safetensors -P text_encoder/
wget $BASE/text_encoder/model-00003-of-00004.safetensors -P text_encoder/
wget $BASE/text_encoder/model-00004-of-00004.safetensors -P text_encoder/
# VAE(約254MB)
wget $BASE/vae/diffusion_pytorch_model.safetensors -P vae/2. GPU Pod作成
- RunPod → Pods → + Deploy
- GPU: RTX PRO 6000
- テンプレート: ComfyUI - Blackwell Edition(PyTorchがsm_120対応済み)
- Network Volume: モデルを入れたものを選択
- Volume Disk: 0GB(Network Volumeだけで足りる)
- Deploy
3. diffusersインストール
pip install git+https://github.com/huggingface/diffusers accelerate peft4. 実行
from diffusers import QwenImageLayeredPipeline
from PIL import Image
import torch
pipeline = QwenImageLayeredPipeline.from_pretrained(
"/workspace/models/Qwen-Image-Layered",
torch_dtype=torch.bfloat16,
)
pipeline = pipeline.to("cuda")
# LoRA読み込み
pipeline.load_lora_weights("/workspace/input/QIL_face_parts_V3_dim16_1e-3-000056.safetensors")
image = Image.open("input.png").convert("RGBA")
with torch.inference_mode():
output = pipeline(
image=image,
prompt="",
negative_prompt=" ",
generator=torch.Generator(device="cuda").manual_seed(777),
true_cfg_scale=4.0,
num_inference_steps=50,
layers=3,
resolution=640,
cfg_normalize=True,
use_en_prompt=True,
)
for i, layer in enumerate(output.images[0]):
layer.save(f"layer_{i}.png")5. パラメータ
| パラメータ | 値 | 備考 |
|---|---|---|
| layers | 3 | LoRA使用時。LoRAなしなら4 |
| resolution | 640 | 640か1024のみ指定可 |
| num_inference_steps | 50 | |
| true_cfg_scale | 4.0 |
実行結果
RTX PRO 6000(96GB)でパイプライン読み込み約90秒、推論約75秒/枚(steps=50, resolution=640)。VRAM使用量は約65GB。
以下は実際の出力結果。入力は28枚ある表情バリエーションのうちの1枚(怒り顔)で、記事冒頭の入力サンプル画像とは別の画像。
face_parts(顔パーツ)
目・眉・鼻・口が透過背景で出力される。パーツ同士は離れているため、個別の切り出しが容易。

face_base(顔土台)
顔パーツと髪を除いた肌。目や口があった位置にはのっぺりした肌が生成されている。Live2Dでパーツを動かしたときに下から見える面として使える。

hair(髪)
髪全体が1レイヤーで出力される。アホ毛・サイドテール・前髪・後ろ髪がすべて含まれる。

Live2D向けの課題
顔パーツと土台の分離はLive2D向けに使える。face_baseがパーツの裏側(見えない肌)を生成しているので、パーツを動かしても穴が開かない。
ただし髪は1枚にまとまっており、Live2Dで使うには前髪・後ろ髪・サイドテール・アホ毛を個別に分ける必要がある。LoRAは髪の細分化には対応していないため、別のアプローチが要る。
髪の分離: LoRAなし+レイヤー数増加
Qwen-Image-Layeredはlayersパラメータでレイヤー数を指定できる。LoRAなしでレイヤー数を増やせば、髪が複数レイヤーに分かれる可能性がある。
検証結果
同じ入力画像(怒り顔)で、LoRAなし・レイヤー数を変えて検証した。
| layers | 結果 |
|---|---|
| 5 | ほぼ元画像そのまま。意味のある分離なし |
| 6 | サイドテールが前後に分離、アホ毛・眉が独立。最も良い結果 |
| 8 | 細かすぎて崩壊。ゴミレイヤーが多い |
6レイヤーが最も有効だった。サイドテール+シュシュがlayer_3に、サイドテールの裏側(奥の髪)がlayer_4に分離された。
髪レイヤーの再分解は効かない
gigazineの記事で「一度分解してから特定レイヤーをさらに分解できる」と紹介されていたため、LoRA出力の髪レイヤーを再入力して分解を試みた。結果は、元の髪がそのまま1レイヤーに残り、他は透明。髪単体の画像を入力しても意味のある分解はできなかった。
組み合わせ戦略
- 顔パーツ・土台: LoRA 3レイヤー出力を使う(精密な分離)
- 髪: LoRAなし 6レイヤー出力から取る(サイドテール等の分離)
同じ入力画像に対して2回パイプラインを走らせて、用途ごとに使い分ける形になる。
28枚バッチ処理の注意
Web Terminalで長時間実行は危険
RunPodのWeb Terminalでバッチ処理(28枚×75秒=約35分)を実行したところ、1枚目の途中でプロセスが死んだ。Web Terminalの接続が切れるとフォアグラウンドプロセスがSIGHUPで殺される。
SSH直接接続を使う
RunPodのSSHには2種類ある。
| 方式 | コマンド | インタラクティブシェル | SCP/SFTP |
|---|---|---|---|
| ssh.runpod.io経由 | ssh <pod-id>@ssh.runpod.io | 不可(PTY非対応) | 不可 |
| TCP直接接続 | ssh root@<ip> -p <port> | 可 | 可 |
ssh.runpod.io経由は接続自体はできるが、PTY(擬似端末)が割り当てられないためインタラクティブなシェル操作ができない。接続はできているのにコマンドが打てない、という紛らわしい状態になる。
Podダッシュボードの「SSH over exposed TCP」に表示されるIPとポートで直接接続すれば、通常のVPSと同じように使える。
# ssh.runpod.io経由(接続はできるがインタラクティブ操作不可)
ssh <pod-id>@ssh.runpod.io -i ~/.ssh/id_ed25519
# TCP直接接続(推奨。普通のシェルが使える)
ssh root@<ip> -p <port> -i ~/.ssh/id_ed25519RunPodの公開鍵設定(Settings → SSH Public Keys)に鍵を登録しておく必要がある。
nohupでバックグラウンド実行
直接SSHで接続したら、nohupでバックグラウンド実行する。SSH切断してもプロセスが生き続ける。
nohup python3 /workspace/scripts/run_face_parts.py > /workspace/output/log.txt 2>&1 &
tail -f /workspace/output/log.txtWeb TerminalのnohupはSSHと異なりSIGHUPの扱いが不安定なため、長時間処理には使わないこと。
28枚バッチの結果
SSH直接接続+nohupで28枚の処理が完了した。75秒/枚で安定し、エラーなし。出力は表情ごとにface_parts・face_base・hairの3レイヤー。
face_partsは概ね良好
28枚中、表情パーツ(目・眉・口・鼻)の分離は大半がうまくいっていた。Live2Dの表情切り替え用素材としてはそのまま使える。
face_baseの品質にバラつき
face_base(顔土台)は表情によって結果が大きく異なった。
パターン1: 口の跡が残る(髪は綺麗に取れる)

smile。口元にうっすら跡が残っている。この上にface_partsの口を重ねると二重になる。一方で髪は綺麗に全部取れていて、ハゲた土台としては理想的。

同じsmileのhairレイヤー。アホ毛・前髪・サイドテール・後ろ髪が全部入っている。
パターン2: 口が消える(後ろ髪がサイドに残る)

surprised。口・鼻の跡がほぼない。土台としては一番綺麗。ただしサイドに後ろ髪が残っている。

closed_eyes。同じく口の跡なし、サイドに後ろ髪あり。
パターン3: 口がガッツリ残る

laughing。開いた口がそのまま土台に残っている。土台としては使えない。
「失敗」が前髪分離になっている
後ろ髪が土台に残っているということは、hairレイヤーには前髪だけが入っている。

closed_eyesのhairレイヤー。前髪+アホ毛+シュシュだけが取れていて、後ろ髪がない。Live2Dで前髪と後ろ髪を別レイヤーにしたいケースでは、この「失敗出力」がそのまま使える。
トレードオフ
| 傾向 | 口の跡 | 髪の分離 | 土台の使い道 |
|---|---|---|---|
| 髪が綺麗に取れる | 残りがち | 全部1レイヤー | 口跡を手動で消す |
| 後ろ髪が残る | 消える | 前髪だけ分離 | そのまま使える(後ろ髪は別途処理) |
全表情で完璧な分離はできない。使い方としては:
- 土台: 口跡のない出力(surprised等)を1枚選んで全表情共通で使う
- 前髪: 後ろ髪が残った出力のhairレイヤーから取る
- 後ろ髪: 土台に残った後ろ髪を別途切り出すか、face_baseをLayeredに再入力して分離する
- 表情パーツ: face_partsは表情ごとに使う
出力解像度の注意
スクリプトでresolution=640を指定していたため、入力1024x1024に対して出力が640x640になっていた。Live2Dで使うにはアップスケールが必要。手元のComfyUIでアップスケーラーを通すのが手軽。
resolution=1024で品質は上がるか
640で回したバッチ結果では全体的にディテールが甘かった。入力画像を1340x1340にアップスケールし、resolution=1024で再検証した。
LoRA + resolution=1024で顔パーツの分離品質が大幅に向上
LoRA + layers=3 + resolution=1024で実行。RTX PRO 6000で約4分(4.8秒/step × 50steps)。

face_parts。640と比べて目・眉・鼻のエッジがくっきり出ている。
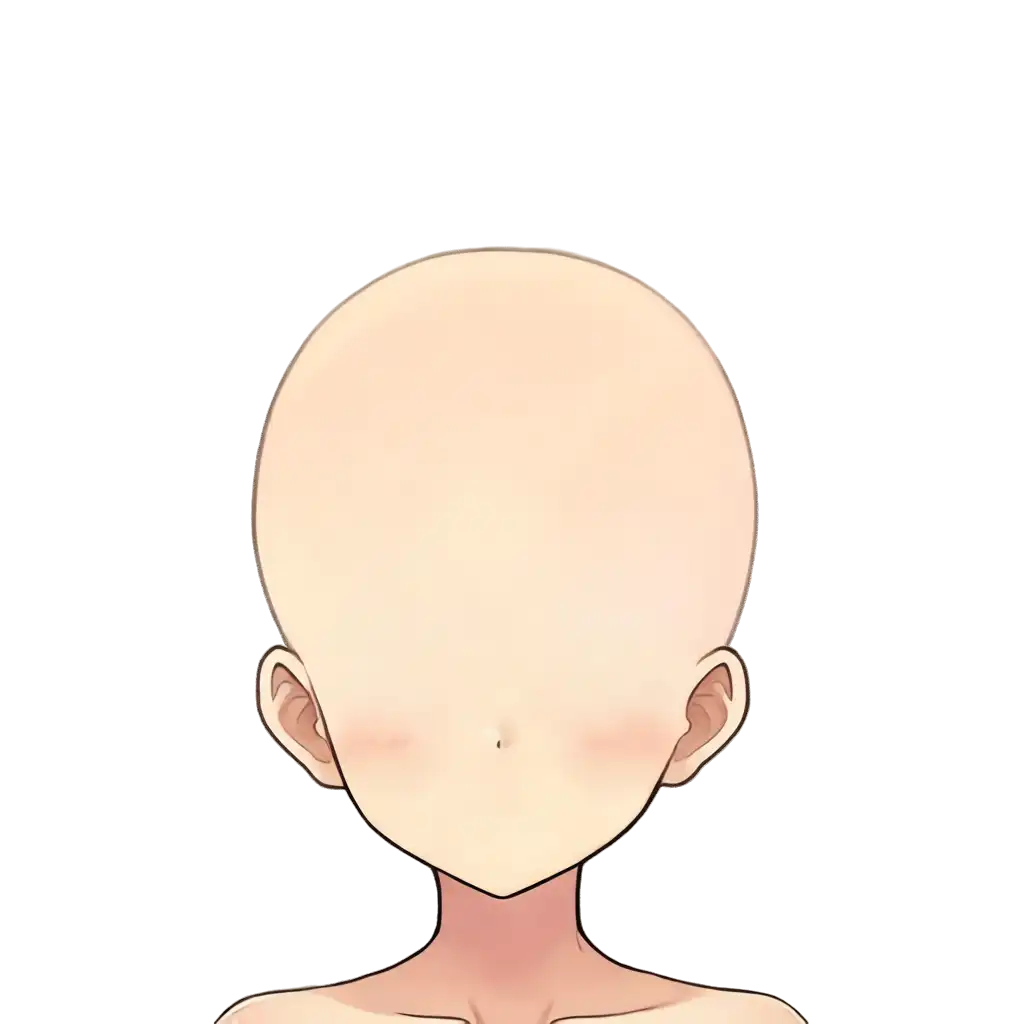
face_base。640のバッチでは口の跡が残る/後ろ髪が残るのトレードオフがあったが、1024では口の跡なし・髪の残りなし・耳も綺麗、と完璧なハゲ土台が出力された。

hair。毛先のディテールが640とは段違い。ただし前髪・後ろ髪・サイドテール・アホ毛はすべて1レイヤーにまとまっており、LoRAの3レイヤー分離では髪の中身は分けられない。
| resolution=640 | resolution=1024 | |
|---|---|---|
| 推論時間 | ~75秒/枚 | ~240秒/枚 |
| face_parts | 使える | くっきり |
| face_base | 口跡/髪残りのトレードオフあり | 完璧 |
| hair | 1レイヤー | 1レイヤー(ディテール向上) |
顔パーツと土台に関しては、1024で回す価値がある。
髪の細分化は試行錯誤したが無理
Live2Dで髪を動かすには前髪・後ろ髪・アホ毛・サイドテールが個別レイヤーである必要がある。以下の方法を試した。
LoRAなし + layers=6 + resolution=1024:
640のlayers=6ではサイドテール前後分離+アホ毛独立ができていたので、1024で精度が上がることを期待した。

layer_1。アホ毛とサイドテール(右)が独立で取れている。

layer_4。髪の線画が出力されている。本来の分離とは異なる挙動。

layer_5。ほぼ元画像がそのまま出力されている。分離されていない。
一部のパーツ(アホ毛、サイドテール)は偶然独立することがあるが、前髪と後ろ髪の分離は実現できなかった。
プロンプトでレイヤー内容を指示:
prompt = "Separate into 6 layers: 1) front bangs hair, 2) ahoge cowlick, "
"3) right side ponytail with blue scrunchie, 4) left side hair, "
"5) back hair, 6) face and skin"プロンプトで各レイヤーの内容を指定しても、モデルは従わなかった。Qwen-Image-Layeredのプロンプトは画像の説明用であり、レイヤー分離の制御には使えない。
Geminiに髪レイヤーの分離を依頼:
マルチモーダルLLM(Gemini)に髪の画像を渡して「前髪と後ろ髪を分離して」と依頼したが、画像の編集・分離はできなかった。
そもそもQwen-Image-Layeredの設計思想が「キャラと背景の分離」「大きなパーツ単位の分離」であり、同じ質感を持つパーツ内部の細分化は想定されていない。tori29umai氏のLoRAも顔パーツ/土台/髪の3分割に特化しており、髪内部の分離には対応していない。髪をパーツごとに分けるには、手動でマスクを描いて切り出すか、SAM(Segment Anything Model)等のセグメンテーションモデルを使う必要がある。
コスト管理
使い終わったらすぐStop。Network Volumeにモデルが残っているので、次回はダウンロード不要で数分で再開できる。
| 操作 | 効果 |
|---|---|
| Stop | Pod停止。Network Volumeは保持(0.07ドル/GB/月は継続) |
| Terminate | Pod削除。Network Volumeは残る |
| Network Volume削除 | 全データ消去、ストレージ課金停止 |
PodをTerminateしてもNetwork Volumeは消えない。別のPodにアタッチし直せるので、GPUを変えたいときもモデルの再ダウンロードは不要。
完全に使わなくなったらNetwork Volumeも削除する。放置するとストレージ課金が地味に積もる。