OrbisはGitHubリポジトリを3D依存グラフにしてClaudeへ渡す
 目次
目次
Orbisは、GitHubリポジトリのURLを入れるとコードをcloneし、ASTを解析して、モジュール間の依存を3D force-directed graphで表示するツールだ。
DockerでローカルAPIを立ててAIチャットは無効のまま、psf/requests(35モジュール)とexpressjs/express(98モジュール)を実際に放り込んで構造把握UIとして使えるか試した。
GitHub標準のDependency graphがmanifestやlock fileからパッケージ依存を拾うのに対して、Orbisはソースコードのimportやexportを見て、リポジトリ内のファイル同士のつながりを出すので、コードレビュー前に「この変更はどこへ波及するか」を見る用途ならパッケージ一覧よりこちらが近い。
DEV Communityの記事とGitHubリポジトリを見る限り、構成はかなり小さい。
FastAPIバックエンド、neo_parser.py、vanilla JSのSPA、demo生成スクリプトでほぼ完結している。
GitHub APIで確認した時点ではMITライセンス、starは1、default branchはmain、pushは2026-03-18だった。
実際にローカルで動かしてみた
DockerでOrbisを起動して、AIチャットは無効のまま3Dグラフだけ見てみる。
git clone https://github.com/dakshjain-1616/Orbit-dependency-visualised.git orbis
docker build -t orbis orbis
docker run --rm -p 8001:8001 orbisANTHROPIC_API_KEYを渡していないのでチャットパネルは無効になるが、http://localhost:8001を開くとgraphの解析と表示は普通に動く。
分離設計が効いていて、APIキーなしでも構造把握だけは試せる。

https://github.com/psf/requestsを入れてAnalyzeを押すと、35モジュール30エッジを20秒くらいで返してきた。
arch patternはModular、4 circular dependencies、high couplingとしてtest_lowlevel.pyとtest_testserver.pyが挙がる。
テスト群(pink/violet)がひとかたまりになり、libraryコア(cyan)と外側にぱらつく孤立moduleが周辺に散る。
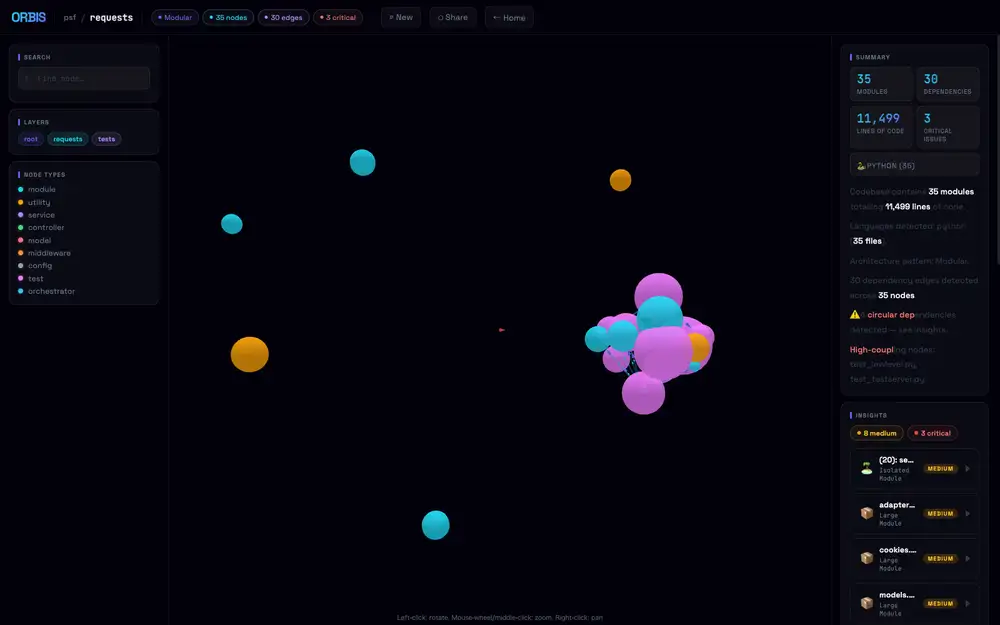
Pキーで自動回転を止めて、テストクラスタを正面に置くとこうなる。
LOCに比例してノード半径が大きくなる仕様なので、35ノード規模でも中心はけっこう密になる。
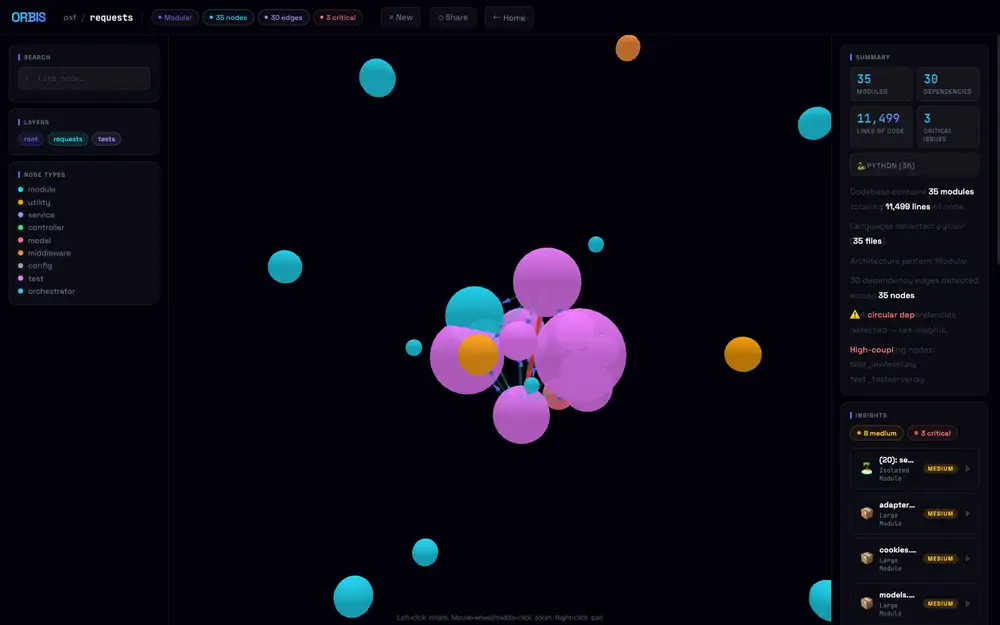
そのまま左クリックドラッグで視点を回すと、テストクラスタが左に寄って、コアmoduleが衛星のように周囲に散っているのが見える。
requests/配下の本体(sessions.py、adapters.py、models.py等)は外周にあり、test moduleが中心の重い塊を形成している、という構図がここで初めて読める。
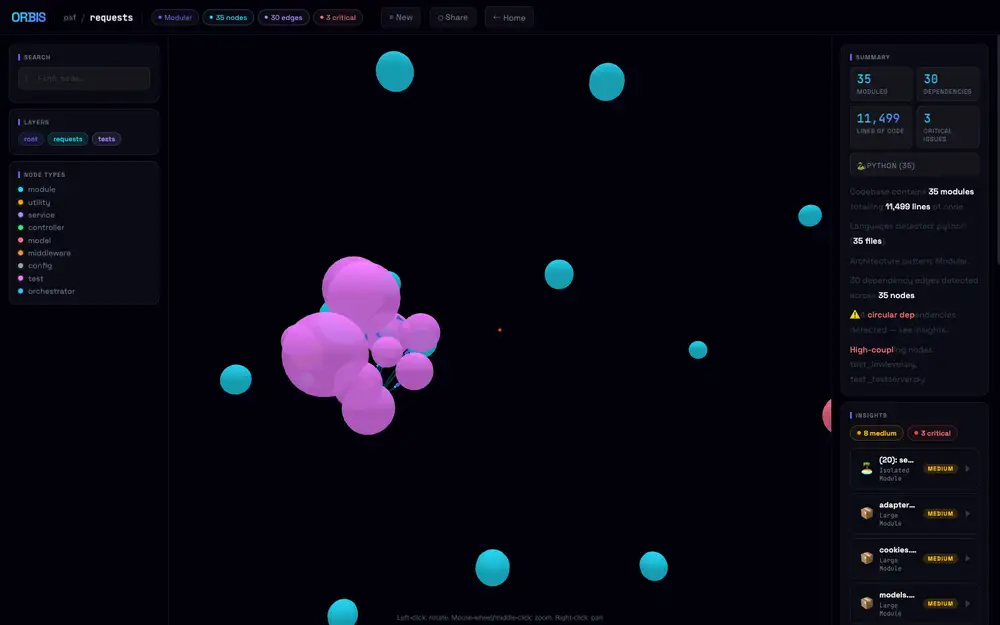
クラスタ内のノード自体もドラッグで掴める。
塊の中の球体を引き出すと、エッジがゴムのように伸びて隣接ノードを引き連れて動き、離すとforce layoutが収束して元の塊に戻る。
重なって読めない場所でも、一瞬引っ張れば「このtestがどのcoreにつながっているか」が線として浮き上がるので、密集したクラスタを解きほぐすときの実用的な手段になる。
ついでに98ノード規模のexpressjs/expressも入れてみたが、これはノードサイズが膨らんで重なり、遠目では「巨大な緑の球体」に見えてしまう。
3Dの利点が出るのは小〜中規模リポジトリで、巨大repoでは逆にFocus Modeで近傍だけに絞らないと読めない。
依存グラフがAIチャットの入力になる
Orbisの面白いところは、3D表示そのものより、解析結果をそのままAIチャットの文脈にしている点だ。
/analyze はSSEで進捗を流し、最後にnode、edge、languages、summary、insightsを含むJSONを返す。
各nodeには行数、complexity、exported symbols、internal dependencies、external dependencies、関数数やクラス数のmetricsが入る。
そのグラフをClaude Opus 4.6へ渡して、循環依存の発生源やリファクタ候補をピンポイントで聞ける。
LLMにリポジトリ全体を雑に読ませる前に、ASTから機械が扱える構造を作っておけば、その構造に沿った質問ができる、という流れだ。
これはWUPHFのMarkdown + GitなLLM wikiで見た「エージェントが参照できる形に知識を落とす」話に近い。
WUPHFは作業ログやfactをMarkdownへ昇格する。
Orbisはコードそのものをnodeとedgeへ落として、AIが会話で使える中間表現にする。
どちらも、チャット欄に生の文脈を詰め込むより、先に機械が扱える形を作る発想だ。
GitHubのDependency graphとは別物
名前だけ見るとGitHubのDependency graphと被るが、見ている層が違う。
GitHub公式ドキュメントのDependency graphは、manifest、lock file、dependency submission APIからプロジェクトの依存パッケージをまとめる機能だ。
Dependabot alerts、dependency review、SBOM exportにつながるので、供給網と脆弱性管理のためのグラフになる。
Orbisが見ているのは、リポジトリ内部の構造だ。
Python、JavaScript、TypeScript、Go、Rust、Javaをtree-sitterで解析し、ファイルやモジュール同士のimport関係をedgeにする。
god module、高結合、循環依存のようなinsightもここから出す。
なので、Orbisで「npmの脆弱なtransitive dependencyを見つける」ことはできない。
逆にGitHub標準のDependency graphで「このauth.pyを割ったら、どの内部moduleが影響を受けるか」は見えない。
同じdependencyという単語でも、片方はパッケージ管理、片方はコード構造だ。
3Dは見た目より探索用のUI
3D force-directed graphは派手に見えるが、OrbisのREADMEを見ると、装飾というより探索UIとして作っている。
nodeは行数でサイズが変わり、typeで色分けされ、edgeには方向付きparticleが流れる。
nodeをクリックするとdetail drawerが開き、依存、metrics、exported symbolsを確認できる。
Focus Modeで未接続nodeを暗くできるので、全部を眺めるより、気になるnodeを中心に周辺だけ見る使い方になる。
大きなリポジトリを3Dで全部把握するのは無理がある。
でも「このファイルの周辺だけ」「循環依存として出たnodeだけ」と絞るなら、平面の巨大な図より視線を切り替えやすい。
GitHub Copilot CLIの/fleet記事では、タスク分解後の依存関係をDAG的に見ていた。
あれは実行計画の依存グラフで、Orbisはコード構造の依存グラフだ。
どちらもAIコーディングでは同じ問題に戻ってくる。
モデルに「全部いい感じに直して」と渡す前に、何が何に依存しているかを外側で持っておく必要がある。
public repoをcloneする設計の重さ
Orbisはpublic GitHub repository URLを受け取り、サーバー側でcloneして解析する。
READMEのUsageでは、expressjs/expressのようなpublic repoを入れて、5秒から30秒ほどでgraphを作る流れになっている。
この設計は試しやすいが、社内リポジトリにそのまま当てるには境界を見直したくなる。
private repo対応、clone先の隔離、解析後の削除、API keyを含むファイルの扱い、巨大repoでのタイムアウト。
Orbisの価値は構造抽出にあるので、SaaSへ投げるよりローカルや社内ネットワーク内で動かすほうが自然だ。
AIチャット機能も同じだ。
ANTHROPIC_API_KEY がない場合はチャットパネルだけエラーになり、graph表示自体は壊れないと書かれている。
これはよい分離だが、Claudeへ送るcontextにはnode list、dependencies、insights、summaryが含まれる。
ファイル全文ではなくても、モジュール名や構造そのものが外部APIに出る。
機密プロダクトでは、この粒度でも十分に設計情報だ。
tree-sitterで取れるものと取れないもの
tree-sitterを使うので、対応言語の構文木からimportやexportをかなり速く拾える。
Python、JS/TS、Go、Rust、Javaを同じ枠で扱えるのは便利だ。
neo_parser.py だけで複数言語を吸収し、frontend側はschema化されたnodeとedgeを見るだけで済む。
一方で、ASTだけでアーキテクチャを完全に読めるわけではない。
動的import、dependency injection、frameworkの規約、設定ファイルで解決されるrouting、runtimeで差し替わるproviderは、素のimport graphから落ちやすい。
insightsに出るgod moduleやhigh couplingも、行数やfan-inを見た機械判定に近いはずで、設計意図までは読まない。
だから、OrbisのAIチャットに「どこをリファクタすべきか」と聞くときは、答えを計画として受け取るより、候補の絞り込みとして見るのがいい。
高結合nodeが出たら、その周辺を開いて、テスト、変更頻度、障害履歴、人間の責務分割と合わせて判断する。
graphは読み始める場所を決めるための道具で、設計判断そのものではない。