人間とLLMの共著テキスト境界を変化点検出で切るarXiv論文を読んで最小実装を試した
 目次
目次
人間が書いた文とLLMが書いた文が混ざった文章を、文単位でどこから切り替わったか推定する論文が出ていた。
arXiv:2605.03723 の “Segmenting Human-LLM Co-authored Text via Change Point Detection” で、2026年5月5日投稿、ライセンスは CC BY 4.0。
手元で確認した限り、arXivページやTeXソースに著者公式の実装コードは入っていない。
論文と同じ実験をそのまま再現するには、AdaDetectGPT、FastDetectGPT、Gemma 2 9B級のスコアリングモデル、CoAuthorデータセット、生成済み混合文書が要る。
ただ、核になっている「LLMっぽさスコア列に変化点検出をかける」部分は、かなり小さいPythonで試せる。
LLMを温かみのある応答にチューニングすると迎合しやすくなる論文や、ファインチューニングで著作物の逐語再現が増える論文と同じく、今回も「LLMが書いたかどうか」を雑に二値判定する話ではない。
問題は、現実の文章がすでに混ざっていることだ。人間が本文を書き、LLMが表や図の説明を足し、人間がまた直す。
この状態で文章全体に「AI生成」とラベルを貼っても、役に立つ情報が粗すぎる。
判定器をそのまま文ごとに使うと境界が暴れる
論文の発想は素直だ。
文章を文の列 X1, X2, ... XN に分け、各文にLLM検出スコア phi(Xi) を付ける。
人間文では低く、LLM文では高く出るスコアがあるなら、そのスコア列は時系列データのように見える。
平均値が急に変わる場所を探せば、著者が切り替わった場所に近い。
単純な文ごとの分類には弱点がある。
まず、しきい値を決めにくい。
0.6 以上ならLLM、といった境界はデータセット、モデル、文体、文長で動く。
もうひとつは短文の扱いだ。
FastDetectGPTのようなスコアは、次トークン確率から統計量を作る。
短い文は観測数が少ないのでぶれやすい。
長い文は比較的安定する。
それなのに全ての文を同じ重さで扱うと、短い文ひとつのノイズで境界が増える。
論文はここに change point detection、つまり変化点検出を持ち込む。
特に Narrowest-Over-Thresholding(NOT)系の考え方を使い、文ごとのスコア列から複数の境界を拾う。
提案手法は大きく VCP、WCP、GCP の3系統。
VCPは普通のCUSUM、WCPは文ごとの信頼度で重み付けしたCUSUM、GCPは文単位スコアの平均ではなく区間全体へ検出器をかける形だ。
重み付きCUSUMは短い文を過信しない
WCPの直感は分かりやすい。
文が長いほど検出スコアが安定するなら、長い文を強めに見る。
論文では理論上、各スコアの分散の逆数を重みにする。
実装上は分散推定を使ってもよいし、トークン数のべき乗を代理重みにしてもよい、としている。
手元ではまず、検出器なしの合成スコアでCUSUMだけを試した。
前半5文を人間っぽい低スコア、後半5文をLLMっぽい高スコアにし、文長を重みにする。
from math import sqrt
scores = [0.13, 0.18, 0.11, 0.16, 0.20, 0.72, 0.81, 0.77, 0.86, 0.79]
lengths = [18, 14, 22, 11, 19, 34, 42, 37, 45, 39]
def weighted_cusum(y, w, s, e, b):
left_w = sum(w[s:b + 1])
right_w = sum(w[b + 1:e + 1])
total_w = left_w + right_w
left_mean = sum(w[i] * y[i] for i in range(s, b + 1)) / left_w
right_mean = sum(w[i] * y[i] for i in range(b + 1, e + 1)) / right_w
return sqrt(left_w * right_w / total_w) * abs(left_mean - right_mean)
values = [
(b + 1, weighted_cusum(scores, lengths, 0, len(scores) - 1, b))
for b in range(len(scores) - 1)
]
print(values)
print(max(values, key=lambda item: item[1]))出力はこうなった。
[(1, 2.07), (2, 2.71), (3, 3.82), (4, 4.26), (5, 4.92), (6, 4.08), (7, 3.02), (8, 2.46), (9, 1.26)]
(5, 4.92)最大値は「5文目の後」。
合成データの境界そのものだ。
もちろん、これはLLM検出器の性能を試したものではない。
試せたのは、論文の中心にある「文ごとのスコア列を境界推定に変換する」部分だけだ。
複数境界までやるなら、このCUSUMを全文に一回だけかけるのではなく、候補区間をランダムに取り、しきい値を超えた区間の中から短いものを選び、左右へ再帰する。
それがNOT系の処理になる。
論文の実験では M=200、しきい値はおおむね sqrt(log(N)) と書かれている。
同じ実験を家庭用マシンで再現するには重い
論文の主実験は、100文書ずつのWikiQA、News、Storyを使い、人間文書の一部をGPT-5-miniやClaude 4.5で書き換えて混合文書を作る。
評価はWindowDiffとCount Error。
比較対象には文単位分類、Voting、TextTiling、LLMへ直接境界を予測させる方法、PaLDなどが入っている。
検出スコアにはAdaDetectGPT、FastDetectGPT、log likelihood、log-likelihood log-rank ratioが使われる。
FastDetectGPT系では google/gemma-2-9b-it をスコアリングモデルにしている。
実験環境はH20 96GB GPUとXeon Platinum 8255C CPU 96基。
ここまで読むと、Macや普通のゲーミングPCで論文表を再現するのは、少なくとも軽い作業ではない。
ただし、実験全体が重い理由は変化点検出ではなく、文ごとのLLM検出スコアを大量に作る部分だ。
変化点検出だけなら標準Pythonで走る。
小さく試すなら、まずは既存のLLM検出器を何か1つ選び、文ごとのスコアをCSVに落とし、その列にWCPをかけるのが現実的だと思う。
Qwen3-8B-BaseとM1 Maxで実機テスト
論文はGemma 2 9B + FastDetectGPT/AdaDetectGPTで実験している。
手元にはGemma 2 9Bがなかったので、ローカルにあった Qwen3-8B-Base で代替した。
スコアもFastDetectGPTではなく、生の avg log-likelihood をそのまま使う。
論文の主実験とは離れるが、軽量実装が成立するかを見るには十分だ。
HF transformersで Qwen3-8B-Base をロードし、MPSバックエンドで走らせる。
文ごとに model(ids, labels=ids) を呼んで avg log-likelihood を出す。
得られた数値列を z-標準化して、WCP + NOT に渡す。
しきい値は論文と同じ sqrt(log N)。
入力は2本用意した。
純人間テキストとして拙著の同人誌の冒頭2ページ分をそのまま流し込む(39文)。
混合テキストとして自分のブログ記事の本文を1本使う(AIに下書きさせて自分で加筆修正したもの、32文)。
純人間テキストは、教師である語り手の独白から始まり、終盤で生徒が職員室に乗り込んでくる構成。
前半は説明的な地の文、後半は短い会話文が並ぶ。
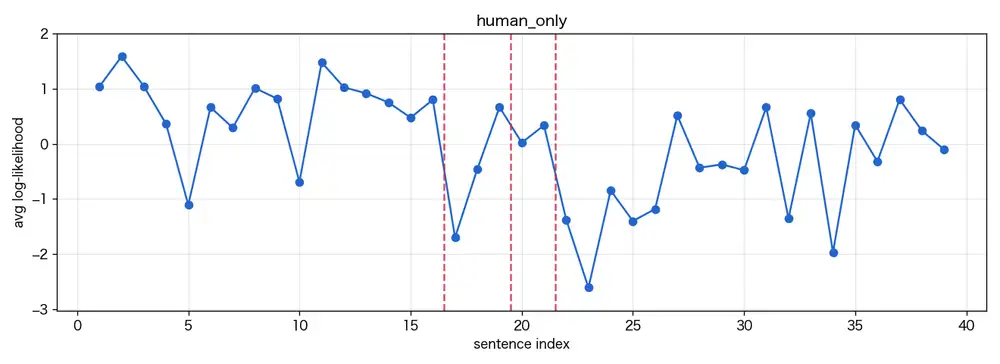
純人間テキストはraw 21候補。
CUSUM上位3つを取ると、文16・19・21の後ろに出た。
最大は12.6。
特に19の後は文体が明らかに切り替わっている。
19: そう、たまにはこういう平穏な日があってもいい、たとえ仕事が何もなくても、
どうせ古書部の面々が何かしらの事件を持ち込んできて、いつも私の至福のまどろみを邪魔するのだから。
20: 「せんせーせんせーくませんせー!」
21: そうそう、こんなふうに。地の文の内省から、生徒の呼びかけに切り替わるところだ。
検出器がそこで反応するのは自然だ。
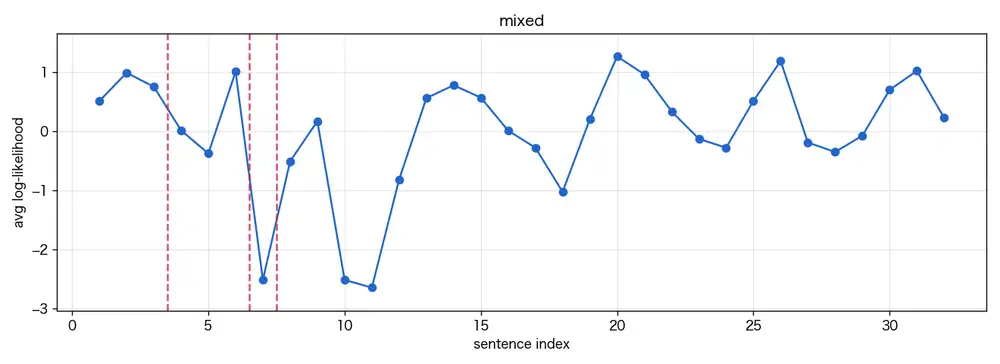
混合テキストはraw 13候補で、上位3つは文3・6・7の後ろ。
CUSUM最大は3.0。
記事はGoogle Flowでオリジナルキャラに衣装を着せて遊んだ話で、導入→手順→画像コメント→感想という普通の構成。
境界が刺さったのは手順の箇条書き周辺だった。
5: 使ったのはウェブ版のGeminiとGoogle Flowだけ。
6: Geminiに衣装を着ている画像を入れて「人物を消して衣装だけにして、背景は単色で」
7: と指示
8: 大体これ一発で衣装だけになる体言止めの短い断片が並ぶ部分だ。
人間とAIの切替点とは特に対応していない。
ここで反応している理由は、手法の限界の話で後述する。
グラフのどこを見るとAIっぽいのか
縦軸は文ごとの avg log-likelihood を z-標準化したもの。
高い(プラス側)ほどQwenにとって予測しやすい文、低いほど意外な文だ。
LLMは確率の高い系列を選んで出すので、別のLLMがスコアを取っても予測しやすい側に寄る。
AIが連続して書いた区間は、グラフの上側に張り付いた台地として浮かぶ。
台地の左端と右端がAI区間の始まりと終わりに対応していて、これがCUSUMの拾う境界になる、というのが教科書的なシナリオだ。
実際の出力ではこの台地はほとんど見えない。
純人間テキスト(拙著の同人誌)はスコアが -2 から -7 の範囲で大きく振れているが、これは台地ではなく上下動だ。
内省の長文は予測しやすくスコアが上に出て、短い叫び声は予測しにくく下に落ちる。
誰が書いたかではなく、文体と文長の差がそのまま振れ幅になっている。
CUSUMが12.6まで上がるのは、地の文と会話文という文体の塊どうしの平均差が大きいから。
人間が同じ文体でしばらく書いて、それから別の文体に切り替える章立てを作ると、内部にたくさん「境界」が立つ。
混合テキスト(AI下書きを加筆修正したブログ記事)も振れ方は似ているが、振幅が小さい。
記事を通して語り口が均されているからで、AIっぽい台地が残っているかというと、グラフからはそうは読めない。
体言止めの短い断片(「と指示」のような1〜2トークン文)が外れ値になって、CUSUMはそちらに刺さる。
こういう振れ方になる以上、生スコアのグラフを見て「ここがAI」と読むことはできない。
論文がFastDetectGPTやAdaDetectGPTを使うのは、文長・文体由来の分散を設計で抑えて、台地として浮かぶAI区間を見えるようにするためだ。
生スコアではここがそもそも成立しない。
校正されたスコアを使っても判定が常に素直に成立するわけではない。
人間がAI風に整えた文や、AI出力を人間が大きく直した文では台地が崩れる。
今回の混合テキストはまさに後者で、加筆修正の段階で台地が均された結果が、振幅の小さいグラフとして残ったと考えるのが筋がいい。
GCPは良さそうだがスコア計算回数が増える
GCPは、文ごとのスコアを平均する代わりに、左区間と右区間それぞれを連結したテキストへ検出器をかける。
短文を個別に判定するより、区間としてまとめたほうが検出器の入力長が増えて安定する。
理屈としてはかなり自然だ。
代わりに計算量が増える。
NOTは再帰的にいろいろな区間を調べるので、GCPではそのたびに検出器を呼ぶ。
検出器が小さい統計量ならまだいいが、9Bモデルでスコアを取るなら一気に重くなる。
手元で試すなら、まずWCPでスコア列を使い回すほうが扱いやすい。
検出結果は証拠ではなく候補境界として見る
この手法は、AI利用の有無を断定する道具ではない。
論文も「人間とLLMの共著テキストを局所化する」問題として扱っていて、文章全体にラベルを貼る検出器より細かいが、入力の検出スコアに依存する。
LLM検出器は文体、ジャンル、言語、翻訳、推敲、パラフレーズで揺れる。
人間がLLM風に整えた文もあれば、LLM出力を人間が大きく直した文もある。
CoAuthorデータセットの実験では、人間、協調、LLM生成の3クラスも扱っているが、これもログ付きエディタで作られたデータだから正解ラベルを持てる。
実用で使うなら、出力は「ここで書き手か生成過程が変わったかもしれない」というレビュー候補に近い。
学生レポートや社内文書の処罰判断に直接使うものではない。
逆に、編集履歴、生成ログ、引用チェックと合わせて、混ざった文章を読む補助線として使うなら筋がいい。
参考
- arXiv:2605.03723 Segmenting Human-LLM Co-authored Text via Change Point Detection
- Creative Commons Attribution 4.0 International
- arXiv:2403.03506 Detecting AI-Generated Sentences in Realistic Human-AI Collaborative Hybrid Texts — Zeng et al. (IJCAI 2024)。今回の論文が参考文献として引いている別系統の手法で、SegFormer系の系列ラベリングで文ごとにAI/人間を判定する。実装は douglashiwo/AISentenceDetection にあるが、これは今回の論文の公式コードではない