技術約3分で読めます
Blender MCP で複数画像から3Dモデルを生成する
 目次
目次
前回の記事では、1枚の画像から3Dモデルを生成した。
しかし1枚だと背面や側面の情報がないため、髪の後ろや体の裏側がうまく再現されない。そこで今回は複数画像を使って精度向上を試す。
Hyper3D の複数画像対応
Hyper3D Rodinは最大5枚の画像を同時送信できる。
ただし出力ポリゴン数は固定(23,332ポリゴン)。画像を増やしてもポリゴン数は増えない。精度が上がるだけ。
テスト1: リアル頭身 × Tポーズ4枚
まずはリアル頭身のキャラをTポーズで4アングル用意して生成してみた。
入力画像
正面・背面・左横・顔アップの4枚。画像サイズは1760x2432(Tポーズで腕を広げているため横幅が広い)。
ちなみに服装が競泳水着なのは、3方向の画像をGeminiで生成しようとしたらビキニが「性的コンテンツ」として弾かれたため。競泳水着なら通った。
| 正面 | 背面 | 左横 | 顔アップ |
|---|---|---|---|
 |  |  |  |
生成結果
| 正面 | 横 | 背面 |
|---|---|---|
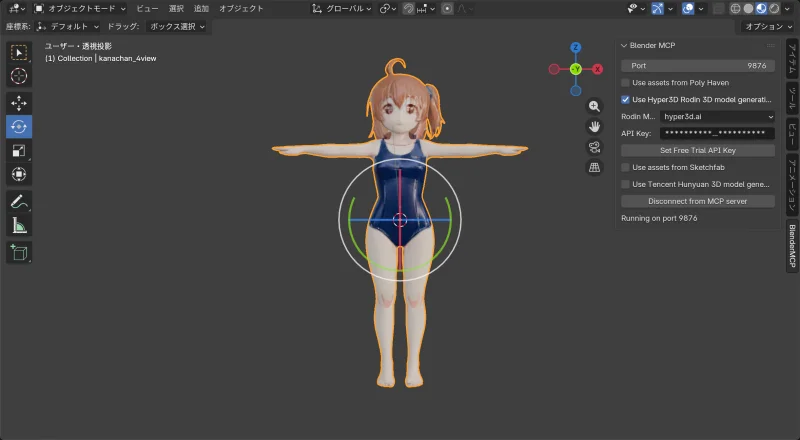 | 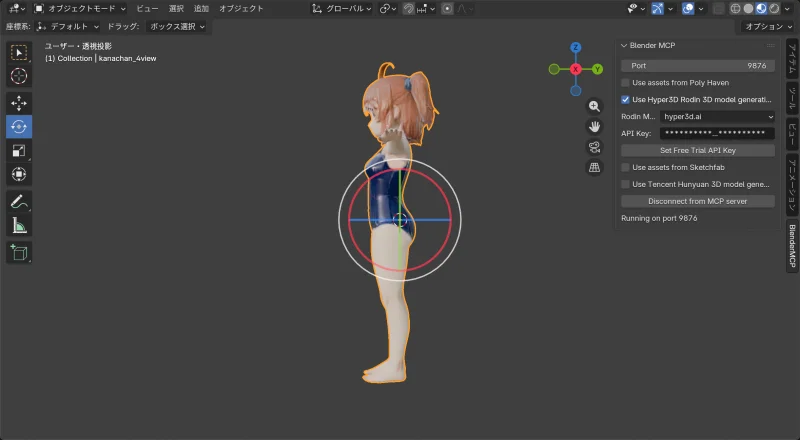 | 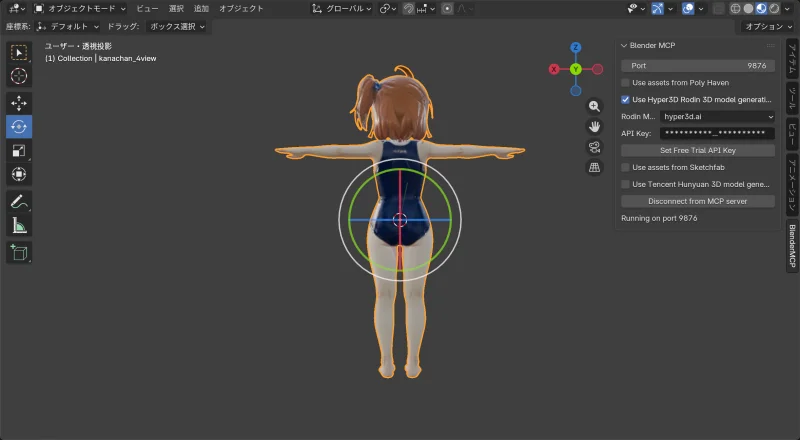 |
モデル情報:
| 項目 | 値 |
|---|---|
| 頂点数 | 22,991 |
| ポリゴン数 | 23,332 |
問題発生
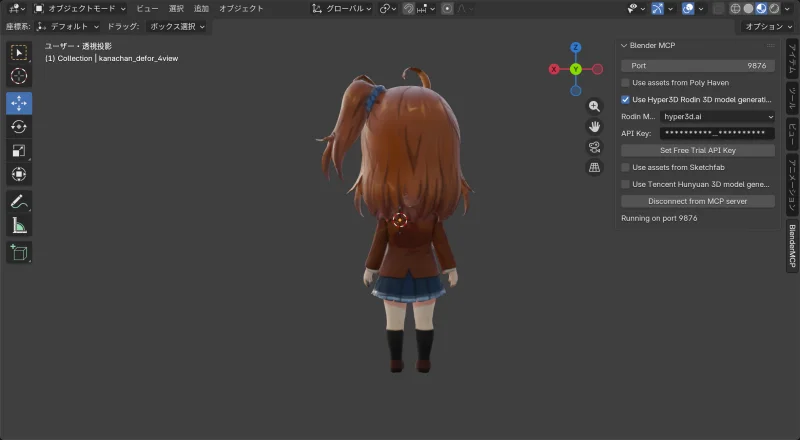
髪の品質は良くなった。背面もちゃんと再現されている。顔は…まあ顔だとわかる。
しかし頭身がおかしい。 元画像はリアル頭身なのに、生成結果はデフォルメ寄り(頭が大きい)になってしまった。
原因の考察:
- Tポーズは腕を広げるため横幅が広い(1760px)
- Hyper3Dの出力ポリゴン数は固定
- 横長の画像を同じポリゴン数に収めると、体全体が圧縮される
- 結果として頭身が詰まって見える
テスト2: デフォルメキャラ × 立ちポーズ4枚
次はデフォルメキャラを立ちポーズで4アングル用意。今度は画像サイズを統一した。
入力画像
正面・背面・左横・右横の4枚。画像サイズは全て1536x2752で統一。こちらはFlowで生成(中身はNanobanana Pro)。思ったより普通に出てきた。
| 正面 | 背面 | 左横 | 右横 |
|---|---|---|---|
 |  |  |  |
生成結果
| 正面 | 背面 |
|---|---|
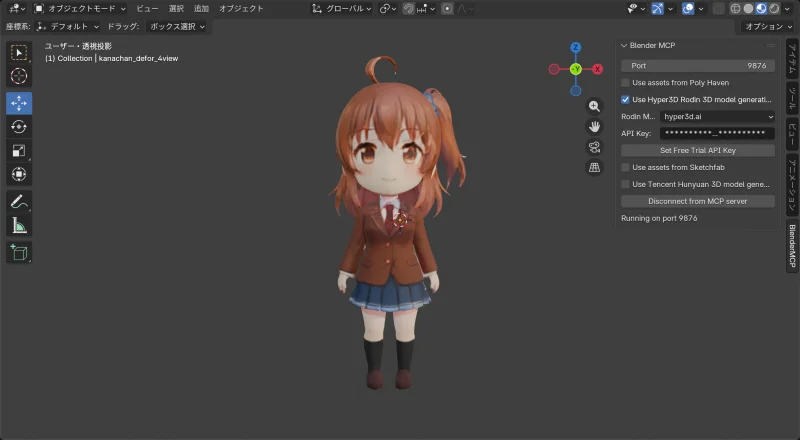 |  |
モデル情報:
| 項目 | 値 |
|---|---|
| 頂点数 | 26,917 |
| ポリゴン数 | 23,332 |
成功
今回は頭身が元画像通りに再現された。服・髪(前後)の品質も良好。顔もリアル頭身より納得できるレベル。
成功要因:
- 全画像のサイズを統一(1536x2752)
- 立ちポーズで横幅が狭い(縦長)
- 結果として体のディテールにポリゴンを使える
比較
1枚 vs 4枚
| 項目 | 1枚(前面のみ) | 4枚(前後左右) |
|---|---|---|
| 顔の品質 | 微妙 | 顔だとわかる程度 |
| 髪の品質 | 後ろが微妙 | 前後とも良好 |
| 背面 | 情報不足で適当 | 画像通りに再現 |
複数画像で確実に品質は上がる。
Tポーズ vs 立ちポーズ
| 項目 | Tポーズ | 立ちポーズ |
|---|---|---|
| 画像横幅 | 1760px | 1536px |
| 頂点数 | 22,991 | 26,917 |
| 頭身再現 | 変化あり | 元画像通り |
立ちポーズの方が安定している。
Tips: 画像準備のポイント
- 画像サイズを統一する(最重要)
- 立ちポーズの方が頭身が崩れにくい
- Tポーズは腕の分だけ横幅が必要になり、体が圧縮される
- 同じキャラ・同じ服装で統一
- 背景はシンプルな方が良い
- 最初の画像がテクスチャ生成のベースになる
まとめ
複数画像で3D生成の品質は確実に向上する。特に背面や髪の再現度が上がる。
ただし画像のサイズやポーズによって結果が変わる。Tポーズより立ちポーズ、画像サイズは統一するのがコツ。