Blender MCP で画像から3Dモデルを生成してみた
 目次
目次
前回の記事でBlender MCPのセットアップが完了したので、実際に3Dモデルを生成してみた。
今回使うのはHyper3D Rodin。 テキストプロンプトや画像から3Dモデルを生成できるサービスで、Blender MCPと連携している。
まずは接続確認
Hyper3Dを使う前に、BlenderとClaudeがちゃんと繋がっているか確認。
「白いシルエットを作って」と指示してみる。
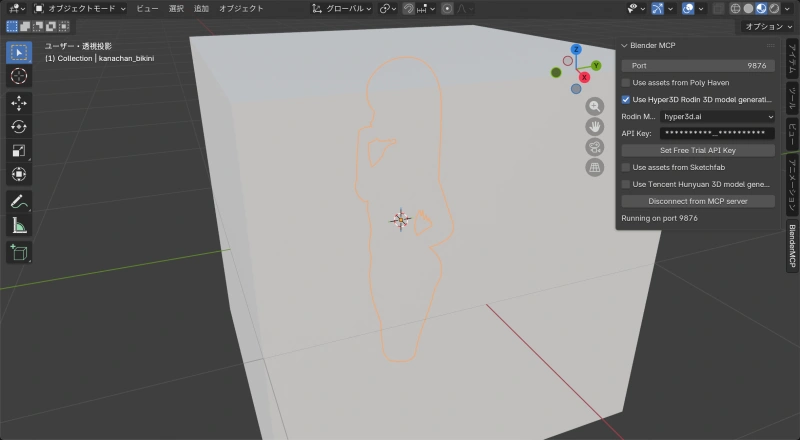
問題なく動いている。Claudeからの指示でBlenderが操作できることを確認できた。
ちなみに、Blender起動時にあるデフォルトの立方体は消しておかないと、生成したモデルに埋まる。Blender初心者なので知らなかった。
テキストプロンプトで生成
次はHyper3D Rodinを使って3Dモデルを生成してみる。
Claudeに「anime girl with bikini を3Dモデルにして」と指示すると、Hyper3D Rodinが起動してモデルを生成してくれる。
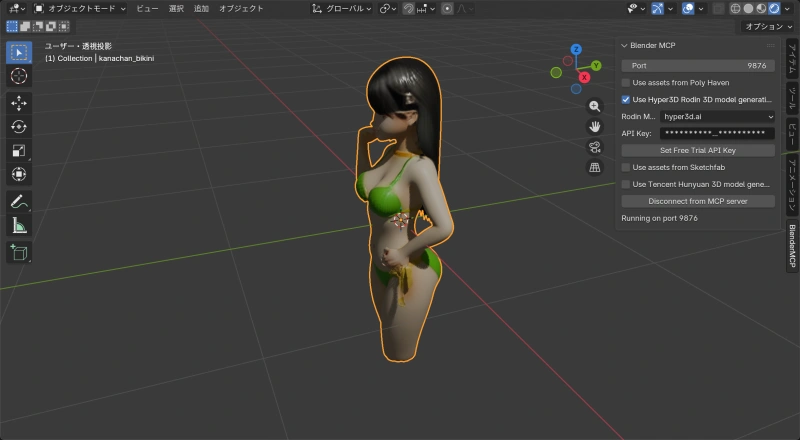
生成結果:
| 項目 | 値 |
|---|---|
| 頂点数 | 22,890 |
| ポリゴン数 | 23,332 |
| マテリアル | model |
| テクスチャ | diffuse, metallic-roughness, normal(各512x512) |
数十秒で緑のビキニを着たアニメ風キャラクターの3Dモデルが生成された。テクスチャも自動で付いている。
画像から3D生成:エラーとの戦い
次は手持ちの画像から3Dモデルを生成しようとした。ここでトラブルに遭遇。

この画像を3Dモデルにしたい。
ちなみになぜ水着かというと、3Dの細かい造形は難しいと思われるので、素体に近い方がいいかと思って生成した。Geminiだと結構面倒だったのでSuperGrokを使っている。
遭遇したエラー
画像パスを指定して生成を開始すると、こんなエラーが返ってきた。
Error: Input buffer contains unsupported image format
at Sharp.toBuffer (/app/node_modules/sharp/lib/output.js:163:17)
at TaskService.rodinPrompting (/app/dist/src/task/task.service.js:968:14)Hyper3DサーバーのSharpライブラリが画像フォーマットを認識できないというエラー。
試したこと(全滅)
| 試行 | 内容 | 結果 |
|---|---|---|
| 1 | 1024x1024にリサイズ | アスペクト比崩壊(却下) |
| 2 | アスペクト比維持でJPG変換 | 同じエラー |
| 3 | PNG変換 | 同じエラー |
| 4 | sipsでPNG変換 | 同じエラー |
| 5 | PillowでRGB変換→PNG | 同じエラー |
| 6 | PillowでRGB変換→JPEG | 同じエラー |
画像フォーマットやサイズの問題ではなさそう。もっと根本的な問題がある。
原因調査
MCPツールの内部でファイルをAPIに送信する際に問題が発生している。ソースコードを追ってみた。
MCPサーバー(server.py)の処理:
# server.py 行800-802
images.append(
(Path(path).suffix, base64.b64encode(f.read()).decode("ascii"))
)画像ファイルを読み込んでBase64文字列に変換している。JSON通信のためバイナリを直接渡せないから、これは正しい。
Blenderアドオン(addon.py)の処理:
# addon.py 行1174-1175
files = [
*[("images", (f"{i:04d}{img_suffix}", img)) for i, (img_suffix, img) in enumerate(images)],
]
# requests.post の files パラメータに渡すここが問題だった。requests.postのfilesパラメータは生のバイナリデータを期待する。しかしimgはBase64文字列のまま。
何が起きていたか:
- MCPサーバーが画像をBase64文字列に変換
- Blenderアドオンがその文字列をそのまま
requests.postのfilesに渡す - requestsライブラリはバイナリを期待しているのでBase64文字列がそのまま送信される
- Hyper3DサーバーのSharpがBase64文字列を画像として解析しようとして失敗
テキストプロンプトだけの場合はimagesが空リストになるため、この問題が発生しなかった。
修正
addon.pyのcreate_rodin_job_main_site関数を修正。
# 修正前(バグ)
files = [
*[("images", (f"{i:04d}{img_suffix}", img)) for ...],
]
# 修正後
files = [
*[("images", (f"{i:04d}{img_suffix}", base64.b64decode(img))) for ...],
]Base64デコードを追加して、バイナリデータとして送信するように修正。
修正後の結果
元画像(1536 x 2752 px)をリサイズせずにそのまま送信して、3Dモデル生成に成功した。
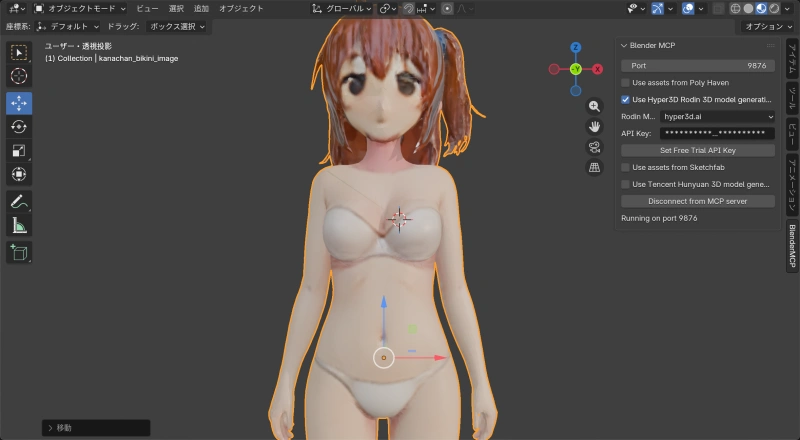
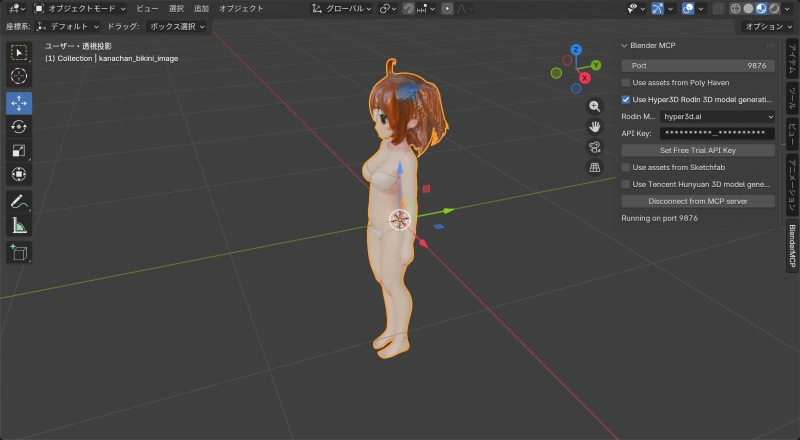
生成されたモデル:
| 項目 | 値 |
|---|---|
| 頂点数 | 23,273 |
| ポリゴン数 | 23,332 |
| マテリアル | model |
| テクスチャ | diffuse, metallic-roughness, normal(各512x512) |
Tips: 複数画像で精度向上
Hyper3D Rodinは最大5枚の画像を同時に送信できる。1枚だと背面や側面の情報がないため、髪や体の裏側がうまく再現されない。
複数アングルの画像を用意すると精度が上がる(かも)
# 複数画像での生成例
input_image_paths = [
"/path/to/front.png", # 前面
"/path/to/back.png", # 背面
"/path/to/side.png" # 側面
]ポイント:
- 同じキャラクター・同じ服装で統一
- できればTポーズが理想的
- 背景はシンプルな方が良い
- 最初の画像がテクスチャ生成のベースになる
まとめ
Blender MCPとHyper3D Rodinを使えば、テキストや画像から3Dモデルを生成できる。
画像からの生成でエラーが出たが、原因はMCPツール側のBase64デコード漏れだった。OSSなのでソースを追って修正できたのは良かった。
次は複数画像を使って、より精度の高いモデル生成を試してみたい。
関連ファイル
修正が必要だったファイルの場所(macOS環境):
- MCPサーバー:
~/.cache/uv/archive-v0/.../lib/python3.10/site-packages/blender_mcp/server.py - Blenderアドオン:
~/Library/Application Support/Blender/5.0/scripts/addons/blender_mcp.py