TRELLIS.2をM1 Max 64GBで動かしてみた検証ログ
 目次
目次
TRELLIS.2のCUDAフリー移植を先日紹介したので、手元のM1 Max 64GBで実際に動くのか検証する。
元記事のベンチマークはM4 Pro 24GBで約3.5分。M1 Maxは世代が古いがGPUコア数(32)とメモリ帯域(400 GB/s)で踏ん張れるはず、という見立てで挑んだ。動くことは動いたが、実用に耐える速度かは別問題だった。
検証環境
- MacBook Pro(Apple M1 Max, GPUコア32, 64GB統合メモリ)
- macOS Darwin 25.3.0
- Python 3.11.14(uv経由で自動インストール)
- PyTorch 2.11.0(MPS利用可)
- ディスク空き 124GB(モデル約15GB)
システムPythonは3.13/3.12しか入っていなかったが、setup.sh が uv venv .venv --python python3.11 を指定していたので、uvが自動で3.11.14をDLしてvenv内に入れてくれた。システム側には触っていない。
セットアップ
リポジトリをクローンして setup.sh を走らせる。
cd ~/projects
git clone https://github.com/shivampkumar/trellis-mac.git
cd trellis-mac
bash setup.shスクリプトの動作は以下の順で進む。
uv venv .venv --python python3.11で仮想環境作成(3.11がなければuvが自動DL)- torch・torchvision・transformers・kornia・trimesh・xatlas等を一括インストール
utils3dを指定commitでgit install- 本家
microsoft/TRELLIS.2を浅いcloneで取得 patches/mps_compat.pyを実行してMPS対応パッチを適用- HuggingFace認証状態をチェック
全体で約4分。依存のDLサイズはトータルで1GB弱、Python 3.11含めて仮想環境は800MB程度に収まった。
適用されたパッチ
mps_compat.py が書き換えたのは本家コードの8ファイル、新規追加が2ファイル。
Patched: trellis2/modules/sparse/config.py
Patched: trellis2/modules/sparse/attention/full_attn.py
Patched: trellis2/modules/image_feature_extractor.py
Patched: trellis2/pipelines/rembg/BiRefNet.py
Patched: trellis2/representations/mesh/base.py
Patched: trellis2/models/sc_vaes/fdg_vae.py
Patched: trellis2/pipelines/trellis2_image_to_3d.py
Patched: trellis2/pipelines/base.py
Installed: trellis2/modules/sparse/conv/conv_none.py
Installed: stubs/o_voxel/convert.py元記事で解説していた通り、スパースアテンションのバックエンドに sdpa と naive を追加し、flash_attn 依存部分を torch.nn.functional.scaled_dot_product_attention に差し替えるパッチが入る。conv_none.py が新規追加されるスパース3D畳み込みのgather-scatter実装、stubs/o_voxel/convert.py がCUDAハッシュマップ代替のPython辞書実装だ。
なお、元記事の時点では nvdiffrast(テクスチャベイク)がスタブ化されていたが、現在の trellis-mac にはpure-PyTorchで書かれた backends/texture_baker.py が入っており、実際にPBRテクスチャを焼けるようになっていた。
HuggingFace認証とゲートモデル
TRELLIS.2の推論にはゲート付きモデル2つのアクセス権が必要になる。
facebook/dinov3-vitl16-pretrain-lvd1689m(画像特徴抽出)briaai/RMBG-2.0(背景除去)
HFログインはCLIプロンプトで非対話入力ができない環境だとパスワード入力で詰まるので、事前にトークンを作って引数で渡す形が楽。
hf auth login --token <HFトークン>ゲートモデルの申請はブラウザで各モデルページの「Request access」を押す。RMBG-2.0は gated: auto で即承認されたが、DINOv3は gated: manual でMetaの手動審査が入る。申請フォームで氏名・生年月日・国・所属・職種を入力する必要があった。
承認状態は huggingface_hub 経由でDLを試すと確認できる。
from huggingface_hub import hf_hub_download
for repo in ['facebook/dinov3-vitl16-pretrain-lvd1689m', 'briaai/RMBG-2.0']:
try:
hf_hub_download(repo_id=repo, filename='config.json')
print(f'[OK] {repo}')
except Exception as e:
print(f'[NG] {repo}: {type(e).__name__}')DINOv3の手動審査は経験上、早ければ数時間、遅いと1日程度かかる。今回は申請から承認まで数時間だった。
検証プラン
3種類の入力画像で一気に回した。入力と3Dモデルの親和性が出力品質をどう左右するかを見る構成。
①公式サンプル(ベースライン)

assets/shoe_input.png。写真ライクな靴で、訓練分布の中心にあるタイプの入力。まずこれで正常動作を確認する。
②アニメ調フルイラスト(かなちゃん 競泳水着)

1760x2432の高解像度アニメイラスト、全身正面、四肢が重なっていないシルエット。形状推論には有利な条件が揃っている。髪のストランドと顔のパーツ(特に目)がどう解釈されるかが見どころ。
TRELLIS.2に入れる前にRMBG-2.0で背景を抜いてから投入する。TRELLIS.2は内部でもRMBG-2.0を呼ぶので同じモデルに通るが、事前に抜いておくと中間生成物を目視確認できる利点がある。MPS環境でRMBG-2.0を単体実行してみたところ、1760x2432の画像で数秒で処理完了した。
③ピクセルアート チビ(かなちゃん Pixel)
![]()
256x256のピクセルアート、チビ頭身、完全にフラットな塗り。陰影情報がほぼなく、3D生成モデルの訓練分布から最も遠い入力。大きく崩れる想定で、どう崩れるかを記録する。
②③がこのブログで登場するキャラクター「かなちゃん」。これまでに同じキャラクターでいくつか3D化の実験をしてきた。
- Blender MCP でAIが3Dモデリングを自動化する — ClaudeからBlender操作する下準備
- Blender MCPとHyper3D Rodinで画像から3D化する実験 — かなちゃんのビキニ立ち絵をRodinで3D化、テクスチャ付き
- Blender MCPで複数画像から精度を上げる検証 — 正面・側面・背面の3枚入力で形状精度を上げる試み
- AI 3D生成ツール比較 2026年版 — TRELLIS・Hunyuan 3D・Tripo AI・Hyper3D Rodin等の主要ツール俯瞰
- ActionMesh — 動画からアニメ付き3Dメッシュを生成するMeta AI — 静止画ではなく動画入力の別ルート
これまで試してきたのはクラウドサービスに投げる系(Rodin・Hunyuan 3D)か、手元のNVIDIA GPUで回す系のどちらかで、ローカルでNVIDIAなしに回すルートは今回のTRELLIS.2 MPSが初めてだ。同じかなちゃん入力で比較できる材料が増えたので、クラウド vs ローカル、CUDA vs MPSの差分を見る素地にもなる。
3D生成モデルは写真や厚塗りイラストのように陰影とパースペクティブが明確な入力を前提に訓練されている。陰影がフラットなアニメ調、特にピクセルアートは訓練分布から外れるので、「入力側のどこまでが許容範囲か」を切り分ける素材として面白い。
生成結果
全ランを python generate.py <image> --output <out> でデフォルト設定(pipeline-type=512, texture-size=1024, seed=42)で実行した。各ランごとに別プロセスで走らせ、ps で10秒毎にRSSを記録してメモリピークも取った。
①靴(ベースライン)
| 項目 | 値 |
|---|---|
| モデルロード | 340s(初回・モデルDL込み約15GB) |
| スパース構造サンプリング | 84s |
| Shape SLat サンプリング | 26s |
| Texture SLat サンプリング | 14s |
| メッシュデコード + 生成計 | 201s |
| PBRテクスチャベイク | 3954s(約66分) |
| 合計 | 約75分 |
| 出力メッシュ | 427,543頂点 / 865,462三角形 |
| GLBファイル | 27MB |
| メモリピーク | 18.47GB |
生成そのもの(201秒)は元記事のM4 Pro公称値(スパース構造+Shape+Texture+メッシュデコード合計185秒)とほぼ同等だった。
PBRテクスチャベイクの比重が極端に大きく、生成201秒に対してベイク3954秒、全体の95%がベイク時間という内訳になった。元記事の時点では nvdiffrast をスタブ化してベイクをスキップしていた前提だったが、その後 backends/texture_baker.py に pure-PyTorchのベイク実装が追加されていて、今回はそれが走っていた。
出力をラボの3Dモデルビューアーにドラッグして確認すると、形状は靴として成立しているものの、ベイクされたテクスチャが真っ赤なノイズで覆われてしまっている。
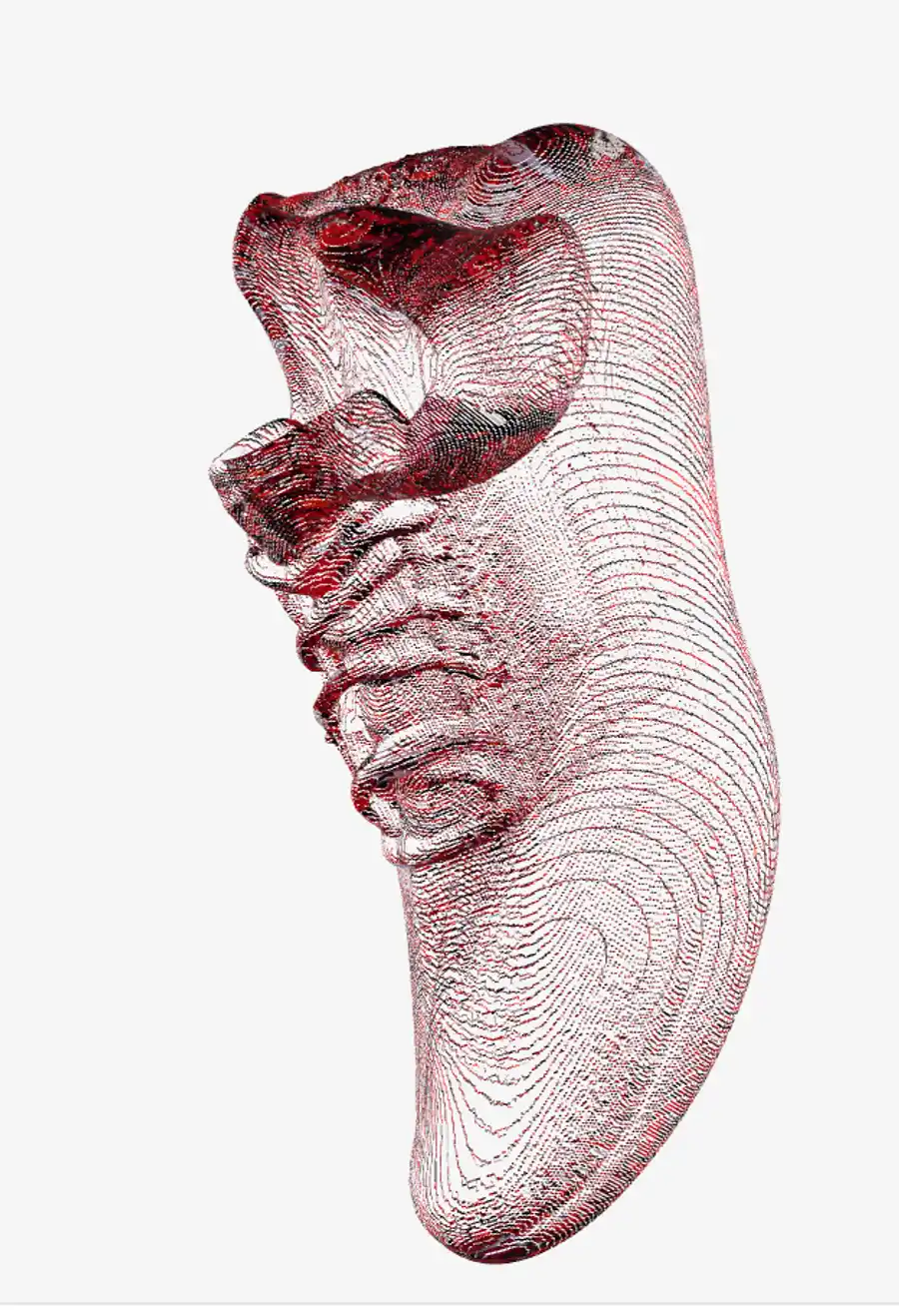
UV展開後の基底カラー画像 out_shoe_basecolor.png を直接見ると、元画像の赤ライン要素が抽出されたまま意味のある形でUVに載せられず、画面全体にランダムに散ってしまっていた。

backends/texture_baker.py のpure-PyTorch実装は、UV展開(xatlas)と voxel ベース属性サンプリングを自前で書き下した素朴なもので、CUDAの nvdiffrast のような微分可能ラスタライザーと比べるとベイク品質が出ていない。結果として、時間をかけてベイクしても最終出力のテクスチャは実用に耐えるレベルではなかった。
②かなちゃん競泳水着(テクスチャあり)
| 項目 | 値 |
|---|---|
| モデルロード | 128s(キャッシュ済み) |
| 生成計 | 152s |
| PBRテクスチャベイク | 5024s(約84分) |
| 合計 | 約88分 |
| 出力メッシュ | 300,373頂点 / 671,142三角形 |
| GLBファイル | 22MB |
| メモリピーク | 17.77GB |
モデルキャッシュ効果でロード時間が340秒→128秒に短縮(2.6倍速)。
面白いのは生成部分が152秒で、靴(201秒)より速かった点。入力解像度は1760x2432と大きいがTRELLIS.2内部でリサイズされるので、差を生んでいるのはスパース構造のボクセル密度と思われる。
TRELLIS.2は3D空間を「ボクセル」と呼ばれる小さな立方体の集まりで表現する。3D空間全体をサイコロ状に分割して、中身が詰まっている位置だけ計算対象にする仕組みで、その「中身がある」と判定されたボクセルが活性点だ。活性点が多いほど畳み込み対象の点数が増えて計算時間も伸びる。正面アニメ全身のシルエットは、靴よりも3D空間上で占める体積(活性点)が少なかったので早く終わった、と見ている。


テクスチャは靴と同じくノイジーだが、形状はかなり驚きだった。アニメ調2Dイラスト1枚から、髪・四肢・ポニーテールが正しく立体化されている。顔の細部(目・鼻・口)は潰れていてこのスクリーンショットからは読み取れないが、シルエットの人体バランスは崩れていない。背面は入力画像に存在しないので推測になるが、破綻なく後ろ姿を構築できている。訓練分布の中心ではない入力に対してもTRELLIS.2本体の形状推論能力はそれなりに機能する、というのは今回一番意外だった発見だ。
③ピクセルアートのチビかなちゃん(テクスチャあり)
| 項目 | 値 |
|---|---|
| モデルロード | 126s(キャッシュ済み) |
| 生成計 | 166s |
| PBRテクスチャベイク | 13429s(約224分) |
| 合計 | 約229分(3時間49分) |
| 出力メッシュ | 415,433頂点 / 1,055,998三角形 |
| GLBファイル | 28MB |
256x256のピクセルアート入力から100万三角形超のメッシュが生成された。靴(865K)の1.2倍、水着(671K)の1.6倍。ベイク時間もそれに比例して最長の224分だった。

予想通り完全に破綻している。ぱっと見の感想は「劇団イヌカレーの絵みたい」で、魔法少女まどか☆マギカの魔女の結界に出てくるコラージュ絵の異物感にそっくりだった。ピクセルアートは「境界」が多い(色の飛びが激しい)ため、3D生成モデルがそれを細かい凹凸として解釈し、結果として過剰にノイジーなメッシュになっている。キャラクターの原型は読み取れない。ここは訓練分布の外で、DINOv3ベースの特徴抽出がそもそもピクセルアートを構造化できていないのだろう。

さらに横から見ると、そもそも立体としての厚みが出ていない。ほぼ平面の壁にノイズが張り付いただけの状態で、3D化というより「2Dのまま高さ方向に潰れた何か」になっている。正面向きのピクセルアート1枚から背面を推測する情報がなさすぎて、モデルが奥行きを作ることを放棄したように見える。
④靴(--no-texture で再実行)
ベイクが支配的である事実を裏付けるため、靴を --no-texture フラグ付きで再実行した。
| 項目 | 値 |
|---|---|
| モデルロード | 133s |
| 生成計 | 191.6s |
| PBRテクスチャベイク | 0s(スキップ) |
| 合計 | 325s(約5.4分) |
| 出力メッシュ | 427,543頂点 / 865,462三角形(①と完全一致) |
| GLBファイル | 15MB(①の27MBに対して頂点カラーのみ) |
同じシードで走らせたのでメッシュは①と完全に同一。テクスチャベイクだけをスキップして75分 → 5.4分に短縮された。

ビューアで確認すると、赤いテクスチャのノイズが消えて靴の形がクリーンに見える。①と同じメッシュなのに、テクスチャベイクを省くだけで出力の見栄えが大きく改善した。ベイク結果が使い物にならない現状では、--no-texture を選んで頂点カラーで済ませる方が実用的だ。
⑤かなちゃん競泳水着(--no-texture で再実行)
②のテクスチャ付き結果で「形状は良いのにテクスチャのノイズで台無し」という印象があったので、同じ入力画像を --no-texture で回し直した。
| 項目 | 値 |
|---|---|
| モデルロード | 132s |
| 生成計 | 167.4s |
| PBRテクスチャベイク | 0s |
| 合計 | 299s(約5分) |
| 出力メッシュ | 300,373頂点 / 671,142三角形(②と完全一致) |
| GLBファイル | 11MB |




これが今回の実験で一番いい結果だった。あほ毛(頭頂の小さな1本)、ポニーテール、水着の襟とレッグラインまで、メッシュの凹凸として正しく表現されている。背面から見ても破綻していない。顔はアップで寄ると目の凹みと鼻・口の段差がうっすら読める程度で「ぱっと見キャラとしては成立」レベルには届いていないが、過去に試した3D生成と比べるとこれは一番顔っぽく出ている。
テクスチャ付き(②)のノイズが形状を覆い隠していただけで、素のメッシュ品質自体はここまで高かった。アニメイラスト1枚から破綻の少ない人型3Dメッシュが約5分で得られる、というのはM1 Maxローカルでやれる範囲としては十分すぎる結果だった。頂点カラーでいい場面なら、この経路が実運用に乗る可能性が見えてくる。
⑥顔クロップを投入
頂点予算をもっと顔に寄せるために、元画像から頭部だけを切り出してTRELLIS.2に投入してみた。全身を入れると頂点が体・服・手足に分散するが、頭だけ渡せば同じ頂点数が顔周辺に集中するはず、という仮説。
| 項目 | 値 |
|---|---|
| モデルロード | 133s |
| 生成計 | 539.2s(約9分) |
| 合計 | 約11分 |
| 出力メッシュ | 2,002,285頂点 / 2,705,690三角形 |
| GLBファイル | 53MB |
頂点は確かに跳ね上がった。水着全身の300K頂点に対して200万頂点、6.7倍の密度だ。




ただし期待した「顔のパーツが鮮明に出る」効果はほとんど得られなかった。6.7倍の頂点数は髪の束と表面ノイズに分散していて、目・鼻・口の凹凸は水着全身版とほぼ同じ曖昧さだった。
さらに背面は密度が明らかに薄い。入力画像に存在しない情報をモデルが推測で埋める必要があるが、頭の後ろは特に手がかりが無くて、正面側に比べて頂点を割けていない。2D画像1枚入力という制約が背面情報の乏しさに直結している。
頂点数がセマンティックな重要度に沿って配分されるわけではない、というのは考えてみれば当然で、モデルから見れば「表面の形状を再現するのに必要な点密度」は表面積と凹凸の複雑さで決まる。顔は曲面として比較的滑らかなので頂点はあまり要らず、逆に髪の毛の束や毛先の不規則な凹凸に頂点を使ってしまう。
顔を鮮明に出したいなら、頂点数を増やす方向では筋が悪そうだ。本来なら入力側の情報量を増やす方向(三面図入力等)で改善したいところだが、TRELLIS.2の run() は単一画像入力のみを前提に設計されていて、多視点の融合は訓練されていない。過去にHyper3D Rodinで複数画像入力を試した記事があるが、あれはRodin側が多視点対応しているから成立する話で、TRELLIS.2では同じ手は使えない。現時点ではTRELLIS.2のMac移植で顔ディテールを引き上げる現実的な手段は見当たらない。
⑦高解像度パイプライン(1024)は動かなかった
顔のディテールをもっと出せないか試すため、--pipeline-type 1024 --no-texture で同じかなちゃん水着を投入した。結果、生成のShape SLat(109秒)とTexture SLat(63秒)までは通ったが、メッシュデコードに入った直後にクラッシュした。
File ".../trellis2/modules/sparse/conv/conv_none.py", line 117
t_idx = tgt_idx[mask]
torch.AcceleratorError: index 17020172 is out of bounds: 0, range 0 to 17020172CUDAフリー移植の核となるgather-scatter型スパース3D畳み込み(conv_none.py)が、1024パイプラインの大きなテンソルで境界チェックを正しく処理できていない。off-by-oneでインデックスが範囲を1超えている。512パイプラインでは同じコードパスで落ちていないので、おそらく特定サイズのボクセルグリッドでのみ発現するバグだ。
現時点のtrellis-macでは512パイプライン以外は実質使えないことになる。顔のディテールを上げる試みはここで頭打ちになった。
パフォーマンス比較
M4 Pro 24GB(元記事公称値)との対比。
| ステージ | M4 Pro 24GB | M1 Max 64GB | 倍率 |
|---|---|---|---|
| モデルロード | 45s | 128-133s(キャッシュ時) | 2.8倍遅い |
| スパース構造サンプリング | 15s | 84s | 5.6倍遅い |
| Shape SLat サンプリング | 90s | 26s | 3.5倍速い |
| Texture SLat サンプリング | 50s | 14s | 3.6倍速い |
| メッシュデコード | 30s | 約80s(生成計から差し引き概算) | 2.7倍遅い |
| 生成合計 | 約3.5分 | 約3.2〜3.4分 | 同等 |
| PBRテクスチャベイク | (元記事時点は未実装) | 66〜224分 | — |
生成だけ見ればM1 MaxはM4 Proと同等、Shape/Texture SLatに至っては3倍以上速い。Shape/Textureは疎テンソル演算が中心で、M1 Maxの400 GB/sメモリ帯域(M4 Proは273 GB/s)が効いたと推測している。
一方でスパース構造サンプリングとメッシュデコードはM1 Maxの方が遅い。このフェーズは backends/conv_none.py のgather-scatter型スパース3D畳み込みが中心で、Pythonレイヤーでのループ・インデックス操作が多くてハードの帯域が活きにくいと思われる。元記事も「pure-PyTorchのスパース畳み込みはCUDAの flex_gemm に比べて約10倍遅い」と書いていて、ここがボトルネック。
メモリ・MPSフォールバックの考察
メモリピークは3ランとも17.5〜18.5GBの範囲に収まった。元記事の「ピーク時18GB前後」という記述と一致する。64GBあれば他のアプリを閉じずに生成できる余裕があった。
重要なのは、16GBのMacではこのモデルは動かないという境界線だ。M4 mini(16GB)では公称ピーク18GBに届かず、スワップに逃げた時点で実用外になる。24GB以上が実質的な最低ラインで、上位機種だがM2/M3/M4 Proクラスが実用域になる。
MPS側のCPUフォールバックは aten::segment_reduce で1箇所だけ警告が出た。
UserWarning: The operator 'aten::segment_reduce' is not currently supported
on the MPS backend and will fall back to run on the CPU.
This may have performance implications.これはPyTorch MPSバックエンド全体のop実装カバレッジの問題で、M4 Proに乗せても同じ警告が出て同じフォールバックが起きる。世代の違いというよりは、PyTorch側でopが埋まるかどうかの問題だ。
M1 Max vs M4 Pro の見立て
M4 Pro で近づけるかを考える材料として、ハード差とソフト差を分けておく。
ハード差は以下の通り。
| 指標 | M1 Max | M4 Pro |
|---|---|---|
| メモリ帯域 | 400 GB/s | 273 GB/s |
| GPUコア数 | 32 | 20 |
| GPU世代 | 古い | 新しい(per-core効率は高い) |
| BF16ネイティブ | ✗(エミュ) | ✓ |
| 統合メモリ(上位) | 64GB | 48GB |
メモリ帯域はM1 Maxの方が高い。BF16ネイティブはM4 Pro有利だが、TRELLIS.2はBF16非依存(元記事で言及)なので今回のワークロードには影響しない。
ソフト側を見ると、segment_reduce のような未実装opはPyTorch MPSバックエンド自体のカバレッジ問題で、M4 Proでも同じCPUフォールバックが起きる。つまり「M4世代向けに最適化されている」わけではなく「どの世代でも等しく実装が足りていない」。
仮にPyTorchのMPSカバレッジが埋まってスパース3D畳み込みがMPSネイティブ実装になった場合、メモリ帯域で勝るM1 Maxの方が速くなる可能性すらある。今はソフト側のボトルネックが効いているフェーズで、ハード差は後回しの論点になっている。
テクスチャベイクが実用性の壁
数字で整理すると、ベイクが全体の90%以上を占めていた。
| ラン | 生成 | ベイク | 合計 | ベイク比率 |
|---|---|---|---|---|
| ①靴 | 201s | 3954s | 4155s | 95% |
| ②水着 | 152s | 5024s | 5176s | 97% |
| ③チビ | 166s | 13429s | 13595s | 99% |
④靴 --no-texture | 192s | 0s | 325s | — |
ベイクが重い理由は、texture_baker.py が全三角形に対してUV展開→ボクセルサンプル→テクセル書き込みをPythonループで回す素朴実装になっているためだ。三角形数にほぼ比例して時間が伸び、100万三角形のチビが224分という極端な数字になった。
しかも時間をかけたベイク結果そのものが実用に耐えない。靴の _basecolor.png を見ると、元画像のカラー情報がUVアンラップ後に正しく張れておらず、ノイズのようなテクスチャが焼かれている。形状生成は動いて品質も悪くないが、PBRテクスチャベイクは時間・品質ともに現状では使いものにならない。頂点カラーでいい用途なら --no-texture で5分台に落とせて、しかもそちらの方が見栄えも良い。
実用性と用途
触った結論として、このMPS移植は「できなかったことをできるようにした」という意味では確実に価値がある。NVIDIA GPU必須というハードルは崩れた。
ただ、クラウドサービスのHyper3D Rodinのように数十秒〜数分で回せるサービスや、CUDA環境での数分という速度と比べると、M1 MaxでのTRELLIS.2は頂点カラーのみなら5分台で済むのでイテレーション可能な実用圏、PBRテクスチャ付きだと66〜224分かかって日常制作には重すぎる。
頂点カラー運用なら、クラウド送信に抵抗があるローカル志向の場面で選択肢になる。PBRテクスチャが必要ならクラウドサービスか、CUDA環境の用意を考えた方が現実的だ。
ソフト側の改善余地は大きい。PyTorch MPSのop実装が進むか、texture_baker.py が最適化されれば大きく変わる。将来的にはMLXへの再実装や、Apple純正の疎テンソル系APIが来れば化ける余地もある。
記事中のスクリーンショットはすべてラボの3DモデルビューアーにGLBをドラッグドロップして撮ったもの。手元のGLBファイルがあれば同じように確認できる。
参考: