AIと喋れる環境を作る(3)ついに喋れた編
 目次
目次
調査編で音声APIを比較し、音声入力実装編でブラウザでの音声入力を実装した。そしてついに、AIキャラと音声で会話できる環境が完成した。
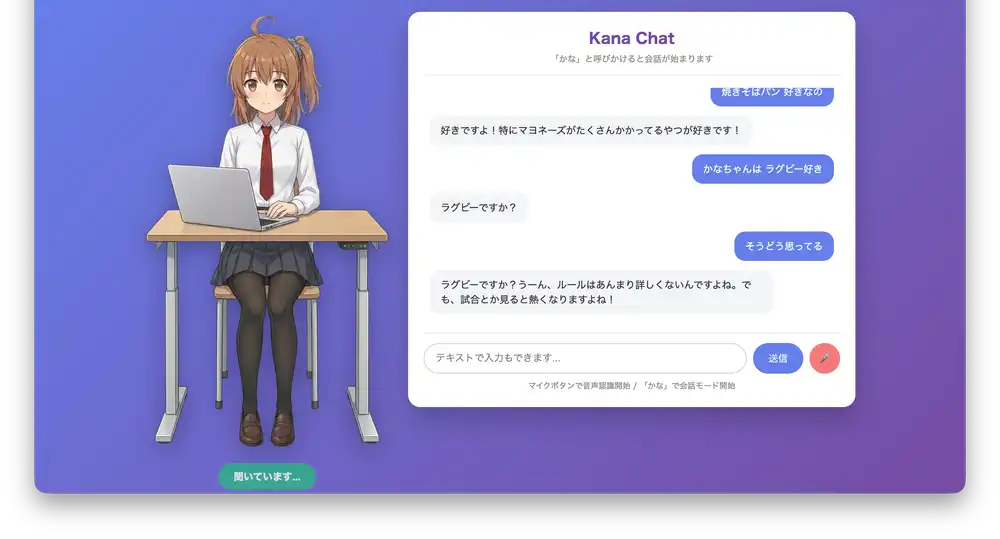
完成したシステムの構成
最終的な構成はこうなった。
| 層 | 技術 |
|---|---|
| 音声認識(STT) | Web Speech API |
| LLM | Gemini 2.0 Flash |
| 音声合成(TTS) | VOICEVOX(春日部つむぎ) |
| バックエンド | Express.js |
| 会話履歴 | SQLite |
さらに、以下のAPIと連携している。
- SwitchBot - 温湿度センサー、照明ON/OFF
- Google Calendar - 予定確認
- GitHub CLI - イシュー・PR確認
- Claude CLI / Codex CLI - 技術的な質問への回答
処理の流れ
- ウェイクワード「かな」で会話モード開始
- Web Speech APIで音声→テキスト変換
- サーバーでルーティング判定(後述)
- Gemini APIで応答生成
- VOICEVOXで音声合成
- ブラウザで音声再生
- 30秒無音で会話モード終了
ルーティングは優先順位がある。
- ローカル即答(時刻・日付)
- SwitchBot(温度、照明操作)
- Git / GitHub
- Google Calendar
- Claude CLI / Codex CLI(技術質問)
- Google検索が必要な質問
- 通常会話(Gemini)
「今何時?」みたいな単純な質問はローカルで即答し、「電気つけて」はSwitchBotに、「最近のニュース教えて」はGoogle検索付きでGeminiに投げる。
実際の動作例
天気を聞く
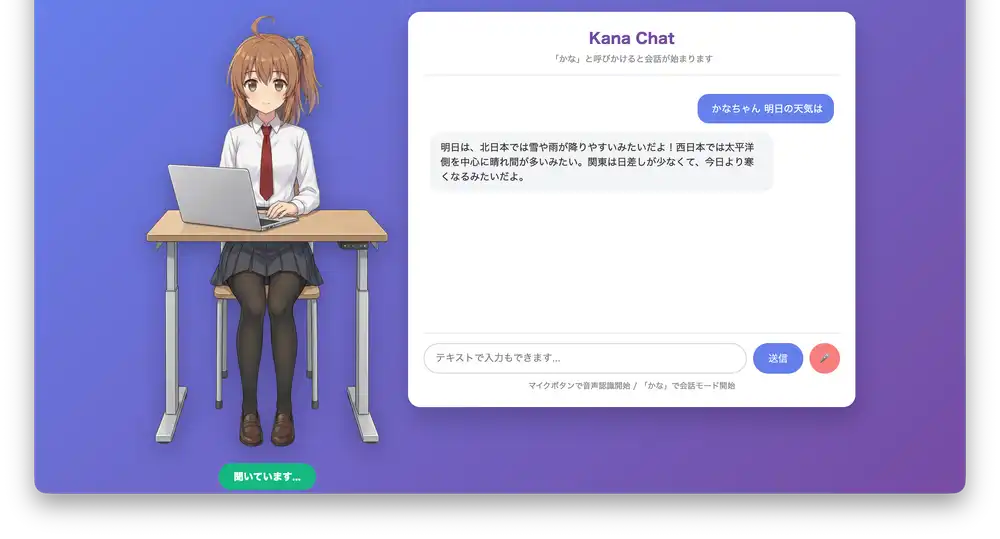
「明日の天気は?」と聞くと、Google検索を使って最新の天気予報を取得して答えてくれる。
SwitchBot連携
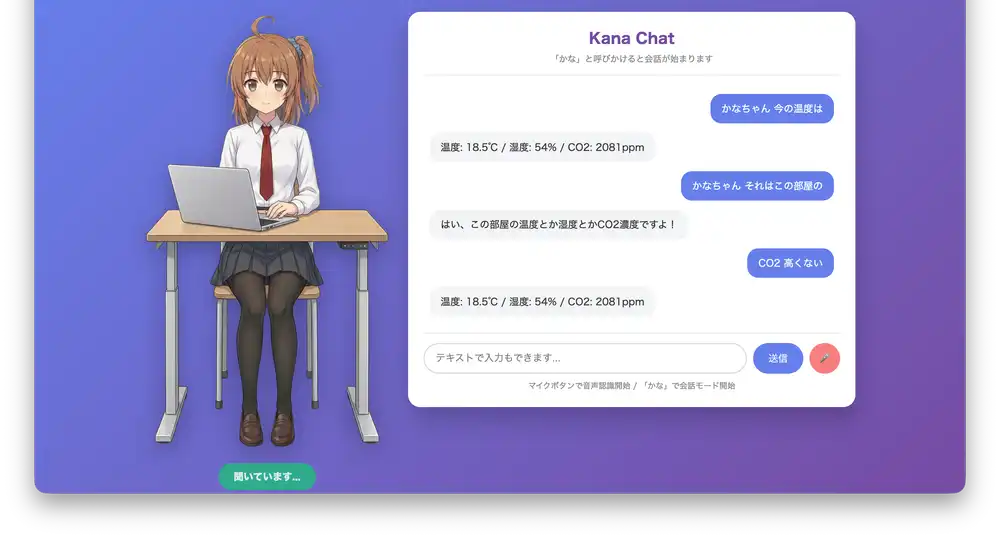
「今の温度は?」と聞くと、SwitchBot温湿度計のデータを取得して教えてくれる。CO2濃度が高いときは「換気したほうがいいかも」と提案してくる。
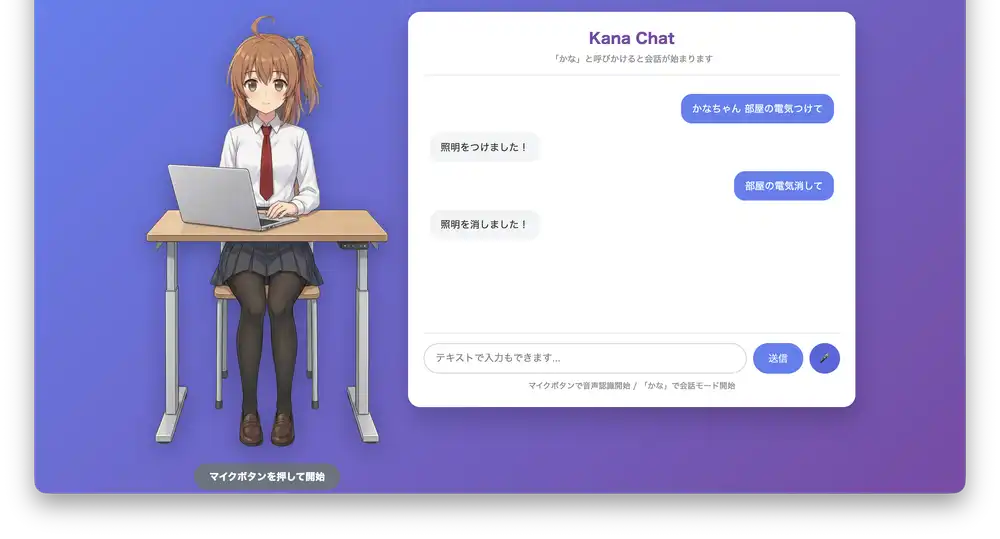
「電気つけて」「電気消して」で照明のON/OFFもできる。
ハマりポイント・Tips
APIトークン取得が地獄
実装自体は事前に調べた通りにできたが、各サービスのAPIトークン取得がとにかく面倒だった。
Google AI Studio(Gemini API)
無料枠を使いたかったが、なぜか有効にならない。Google Cloud Consoleで課金設定を有効にしないとAPIキーが発行できないという罠。無料枠なのに課金設定が必要という矛盾。2026年1月からCloud Consoleと分離して課金不要になるって話だったのに、その話は一体どこへ。
SwitchBot API
APIキーの取得方法がわかりづらすぎる。アプリの設定→アプリバージョンを10回タップ→開発者オプションが出現、という隠しコマンド方式。ゲームの裏技じゃないんだから。
これらのセットアップだけで1時間溶けた。コードを書く時間より認証設定の時間のほうが長いのは現代開発あるある。
自己フィードバック防止
音声再生中にマイクが拾ってしまうと、AIが自分の声に反応してループする。対策として、音声再生中はrecognition.stop()で音声認識を停止している。
function playAudio(base64Audio) {
const audio = new Audio('data:audio/wav;base64,' + base64Audio);
recognition.stop(); // 再生中は認識停止
audio.onended = () => recognition.start();
audio.play();
}display/speak分離
英語やコードを含む応答は、画面表示用と読み上げ用で分ける必要がある。
{
"display": "「Hello」って言えばOKですよ!",
"speak": "「ハロー」って言えばオーケーですよ!"
}プロンプトでこの形式を指定しておくと、Geminiが適切に分離してくれる。
VOICEVOX話速
デフォルトだとちょっと遅い。speedScale: 1.2くらいが聞きやすかった。
const query = await fetch(`${VOICEVOX_URL}/audio_query?text=${text}&speaker=${speaker}`, { method: 'POST' }).then(r => r.json());
query.speedScale = 1.2;
const audio = await fetch(`${VOICEVOX_URL}/synthesis?speaker=${speaker}`, {
method: 'POST',
body: JSON.stringify(query)
});音声認識の誤変換対応
Web Speech APIの認識精度は完璧ではない。「かなちゃん」が「仮名ちゃん」になったりする。プロンプトで「音声認識経由のため誤変換がある。文脈から推測して応答すること」と指示しておくと、Geminiがうまく補完してくれる。
使用感
実際に使ってみた感想。
良かった点:
-
キャラ設定がちゃんと効いている。口調、趣味、反応が一貫している
-
レスポンスは1〜2秒程度。会話として許容範囲
-
SwitchBot連携が意外と便利。「今何度?」とか「電気消して」が声でできるのは楽
-
30秒タイムアウトがあるので、誤反応が続くことがない
-
長い応答でも意外と読み上げてくれる(下のニュース読み上げ参照)。上限はちゃんと調べてないけど、このくらいの長さなら問題なかった
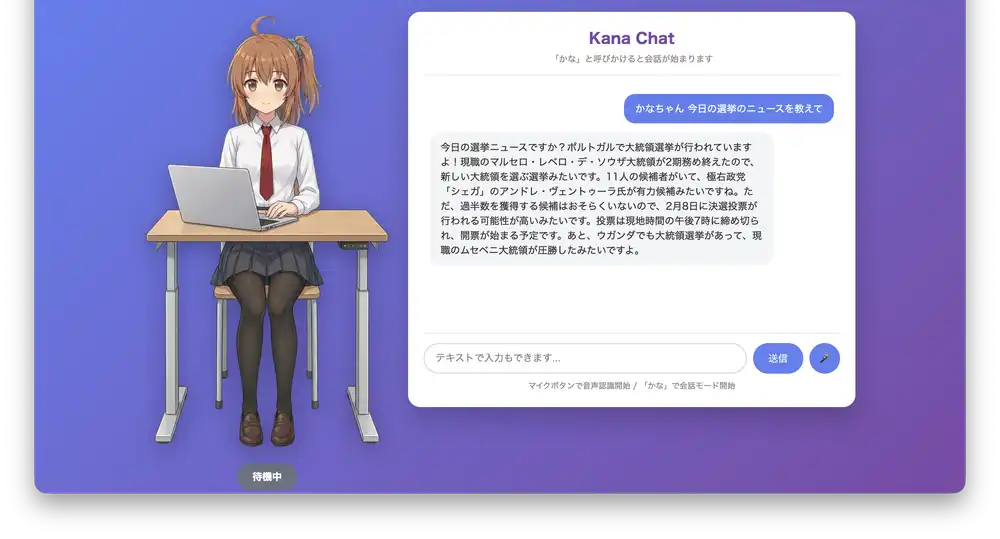
改善したい点:
- 静止画なので、もうちょっと「生きてる感」がほしい
- 「今日の気温は?」と聞くと「場所がわからない」と言われる。位置情報を送っていないので当然。Geolocation APIで位置を取得するか、プロンプトに地名を埋め込むかは要検討
今後の展望
現状は立ち絵が静止画なので、次はアバターを動かしたい。
- Live2D - 2Dアバターを動かす。リップシンクも可能
- VRM - 3Dアバター。VRMファイルを読み込んで動かせる
- 表情変化 - 応答の感情に応じて表情を変える
このプロジェクトはGitHubで公開している。
https://github.com/hide3tu/kana-chat
ひとまずWeb Speech API + Gemini + VOICEVOXの構成で音声会話環境ができた。LLMのAPI代だけで動くので、趣味で遊ぶ分には十分。次はアバターを動かしたい。
- AIと会話を試みる(音声で) - 最初の構想
- AIと喋れる環境を作る(1)音声API調査編 - 音声APIの比較調査
- AIと喋れる環境を作る(2)音声入力の実装編 - Web Speech API / MediaRecorderの実装