Qwen-Image-EditのNSFW版をRunPodで動かした
 目次
目次
3Dモデル用の素体3面図を作りたくて、Qwen-Image-EditのNSFW版(Phr00t AIO)をRunPodで動かしてみた。ローカルスペックを調べて、RunPodでの構築手順をまとめたのに続いて、今回が初めての実践。結構事故って、RTX 4090(24GB)では動かず、RTX 5090(32GB)でやっと成功した。
今日試したこと
RTX 4090(24GB VRAM)での失敗
環境
- RunPod RTX 4090(24GB VRAM)
- テンプレート: runpod/comfyui:latest
- ComfyUIパス:
/workspace/runpod-slim/ComfyUI/
失敗理由
- Phr00t AIO NSFW v18.1(28GB)が24GB VRAMに載らない
--lowvramオプションでも改善せず- FP8版(20GB)はVAE/Text Encoder別途必要で構成が複雑
試したモデル
1. Phr00t AIO NSFW v18.1(28GB)
- パス:
models/checkpoints/v18/Qwen-Rapid-AIO-NSFW-v18.1.safetensors - 結果: 失敗 - 28GBが24GB VRAMに載らない、読み込み中にフリーズ
--lowvramオプションでも改善せず
2. 1038lab FP8版(20GB)
- パス:
models/checkpoints/fp8/Qwen-Image-Edit-2511-FP8_e4m3fn.safetensors - 結果: VAEエラー - このモデルはdiffusion modelのみ、VAE/Text Encoder別途必要
- エラー:
ERROR: VAE is invalid: None
判明した問題点
1. モデル構成の違い
Phr00t AIO版(All-In-One)
- VAE/CLIP統合済み
- 1つのファイルで完結する設計
- ただし28GBで24GB VRAMに収まらない
公式FP8版 / 1038lab FP8版
- diffusion modelのみ
- 以下が別途必要:
- VAE:
qwen_image_vae.safetensors - Text Encoder:
qwen_2.5_vl_7b_fp8_scaled.safetensors
- VAE:
2. 必要なカスタムノード
標準のCLIPTextEncodeではなく TextEncodeQwenImageEditPlus が必要。
このノードはPhr00tがComfyUI標準のnodes_qwen.pyを修正したもの。インストール方法:
# ComfyUIのディレクトリで実行
cd comfy_extras
wget https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO/resolve/main/fixed-textencode-node/nodes_qwen.py -O nodes_qwen.py配布元: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO/tree/main/fixed-textencode-node
3. ワークフローの違い
通常のSD/FLUXワークフロー(CheckpointLoader → LoRA → KSampler)ではなく、 Qwen専用のノード構成が必要
VRAMサイズ別推奨構成
| VRAM | 推奨構成 | 備考 |
|---|---|---|
| 12GB | GGUF Q2_K (7.4GB) | 最軽量、品質やや劣る |
| 16GB | GGUF Q4_K_M (13.3GB) | バランス型、推奨 |
| 24GB | GGUF Q5_K_M (15.1GB) or 公式FP8分離構成 | 高品質 |
| 32GB | Phr00t AIO NSFW (28GB) | フルサイズ、最高品質 |
RTX 4090(24GB VRAM)での選択肢
選択肢A: GGUF版を使う(推奨)
Q4_K_Mで約13GB、24GB VRAMに余裕で収まる。NSFW対応のままGGUF量子化されている。
必要なカスタムノード:
cd /workspace/ComfyUI/custom_nodes
git clone https://github.com/city96/ComfyUI-GGUF
pip install --upgrade gguf必要ファイル:
models/unet/
└── Qwen-Rapid-AIO-NSFW-v18.1-Q4_K_M.gguf
models/text_encoders/
└── Qwen2.5-VL-7B-Instruct-abliterated-Q4_K_M.gguf
└── mmproj-xxx.gguf(同じディレクトリに配置必須)
models/vae/
└── pig_qwen_image_vae_fp32-f16.ggufダウンロード:
pip install huggingface_hub
# GGUF本体
cd /workspace/ComfyUI/models/unet
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('Phil2Sat/Qwen-Image-Edit-Rapid-AIO-GGUF', 'Qwen-Rapid-AIO-NSFW-v18.1-Q4_K_M.gguf', local_dir='./')"
# Text Encoder(abliterated版)
cd /workspace/ComfyUI/models/text_encoders
python3 -c "from huggingface_hub import snapshot_download; snapshot_download('Phil2Sat/Qwen-Image-Edit-Rapid-AIO-GGUF', allow_patterns='Qwen2.5-VL-7B-Instruct-abliterated/*', local_dir='./')"
# VAE
cd /workspace/ComfyUI/models/vae
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('calcuis/pig-vae', 'pig_qwen_image_vae_fp32-f16.gguf', local_dir='./')"ダウンロード元: https://huggingface.co/Phil2Sat/Qwen-Image-Edit-Rapid-AIO-GGUF
選択肢B: 公式FP8分離構成
SFW版。VAE/Text Encoder/Diffusion Modelを個別に読み込む構成。
必要ファイル:
models/diffusion_models/
└── qwen_image_edit_fp8_e4m3fn.safetensors
models/vae/
└── qwen_image_vae.safetensors
models/text_encoders/
└── qwen_2.5_vl_7b_fp8_scaled.safetensors
models/loras/
└── Qwen-Image-Lightning-4steps-V1.0.safetensors(オプション、4ステップ生成用)ダウンロード:
pip install huggingface_hub
cd /workspace/ComfyUI/models
# Diffusion Model
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('Comfy-Org/Qwen-Image-Edit_ComfyUI', 'qwen_image_edit_fp8_e4m3fn.safetensors', local_dir='./diffusion_models/')"
# VAE
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('Comfy-Org/Qwen-Image_ComfyUI', 'qwen_image_vae.safetensors', local_dir='./vae/')"
# Text Encoder
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('Comfy-Org/Qwen-Image_ComfyUI', 'qwen_2.5_vl_7b_fp8_scaled.safetensors', local_dir='./text_encoders/')"
# Lightning LoRA(オプション)
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('Comfy-Org/Qwen-Image-Edit_ComfyUI', 'Qwen-Image-Lightning-4steps-V1.0.safetensors', local_dir='./loras/')"ダウンロード元:
- https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI
- https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI
ワークフロー参考: https://docs.comfy.org/tutorials/image/qwen/qwen-image-edit
参考リンク
ワークフロー
- Phr00t公式ワークフロー: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO/blob/main/Qwen-Rapid-AIO.json
- Civitai 3面図ワークフロー: https://civitai.com/models/2061788/qwen-rapid-aio-three-view-workflow
- ComfyUI公式チュートリアル: https://docs.comfy.org/tutorials/image/qwen/qwen-image-edit
モデル
- Phr00t AIO: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO
- Comfy-Org公式: https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI
- GGUF版: https://huggingface.co/Phil2Sat/Qwen-Image-Edit-Rapid-AIO-GGUF
カスタムノード
- ComfyUI-GGUF: https://github.com/city96/ComfyUI-GGUF
- Comfyui-QwenEditUtils: https://github.com/lrzjason/Comfyui-QwenEditUtils
- Phr00t修正ノード: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO/tree/main/fixed-textencode-node
RunPod運用メモ
課金
- RTX 4090: $0.59〜0.6/時間(2026年1月時点)
- RTX 5090: $0.9/時間(2026年1月時点)
- Volume保持(Stop時): 0.53/日、約$16/月)
Podの止め方
2026-04-05追記: RunPodの停止まわりの整理はRunPodでQwen-Image-Edit-2511を動かすのコスト管理節にまとめ直した。いまの理解では、コンソールで覚える操作は Stop と Terminate が基本。APIでは DELETE、CLIでは runpodctl remove pod という表現が出る。
今回みたいなVolume Disk運用なら、短期の再利用は Stop → Start、別GPUに移るなら Terminate → 新規Pod作成で考えるのがわかりやすい。Pod migrationはbeta扱いで、自分でも2〜3回試したが全然復帰できなかった。復旧手段としてはおすすめしない。
今回のVolume内容
/workspace/runpod-slim/ComfyUI/models/
├── checkpoints/
│ ├── v18/Qwen-Rapid-AIO-NSFW-v18.1.safetensors (28GB)
│ └── fp8/Qwen-Image-Edit-2511-FP8_e4m3fn.safetensors (20GB)
└── loras/
└── Multiple-Angles-LoRA/成功パターン(2026/01/24 確認済み)
入力画像:

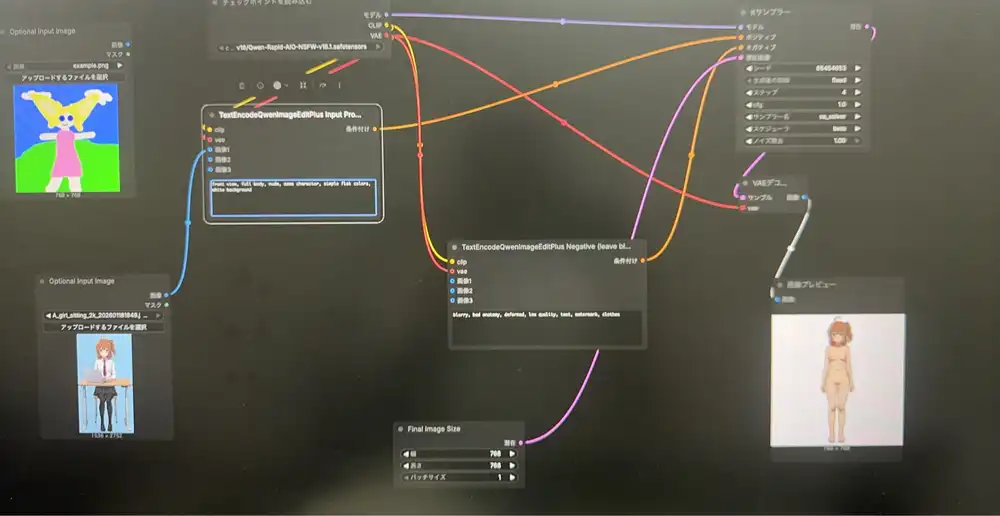
ComfyUIでの生成画面:
環境
- GPU: RTX 5090(32GB VRAM)
- テンプレート: ashleykza/comfyui:cu128-py312-v0.10.0
- PyTorch: 2.9.1+cu128
- ComfyUI: 0.10.0
モデル
- Phr00t AIO NSFW v18.1(28GB)
- パス:
models/checkpoints/v18/Qwen-Rapid-AIO-NSFW-v18.1.safetensors
ワークフロー
- Phr00t公式JSON: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO/blob/main/Qwen-Rapid-AIO.json
- ComfyUIにD&Dで読み込み
設定
- steps: 4
- cfg: 1.0
- sampler: sa_solver
- scheduler: beta
- 出力サイズ: 768x768(テスト用、本番は1024推奨)
デフォルトプロンプトでの出力:

プロンプト(3Dモデル素体用)
ポジティブ:
front view, full body, nude, same character, simple flat colors, white backgroundネガティブ:
blurry, bad anatomy, deformed, low quality, text, watermark, clothes素体プロンプトでの出力(実際はモザイクなし):

3面図を作る場合
- front view → side view → back view でそれぞれ生成
- 入力画像は同じものを使う
生成速度
- 爆速(4ステップで数秒)
RTX 5090(32GB VRAM)での手順
1. Pod作成
- GPU: RTX 5090(32GB VRAM)
- テンプレート: ashleykza/comfyui:cu128-py312-v0.10.0(RTX 5090対応)
- Disk: デフォルトでOK
※RTX 5090はPyTorch 2.8以上が必要。標準のComfyUIテンプレートは非対応。
2. モデルDL(Web Terminal)
Web Terminal開いて実行:
pip install huggingface_hub
cd /workspace/ComfyUI/models/checkpoints
python3 -c "from huggingface_hub import hf_hub_download; hf_hub_download('Phr00t/Qwen-Image-Edit-Rapid-AIO', 'v18/Qwen-Rapid-AIO-NSFW-v18.1.safetensors', local_dir='./')"※28GB、約5分
3. ワークフロー読み込み
- ブラウザで開く: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO/blob/main/Qwen-Rapid-AIO.json
- 「Download」ボタンでローカルに保存
- ComfyUI(Port 3000)にそのJSONファイルをD&D
4. 実行
- チェックポイント:
v18/Qwen-Rapid-AIO-NSFW-v18.1.safetensorsを選択 - 画像をアップロード
- プロンプト設定して実行